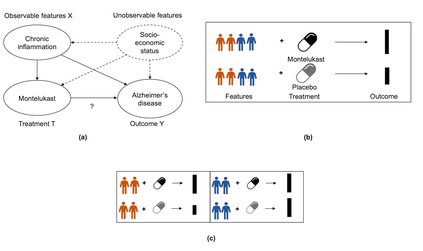
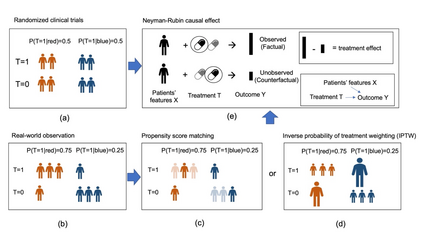
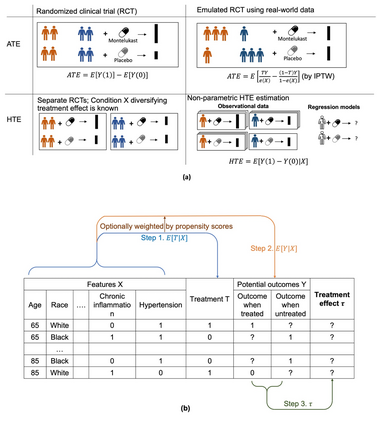
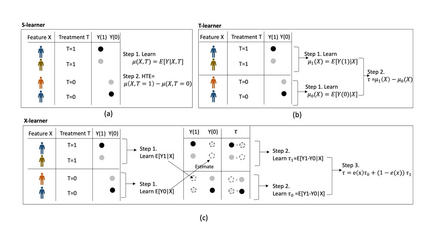
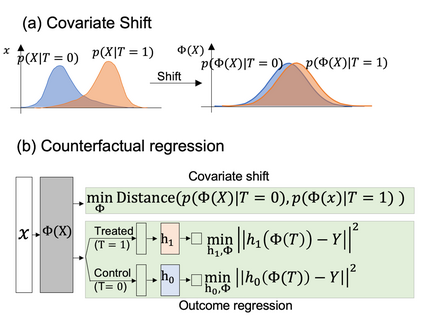
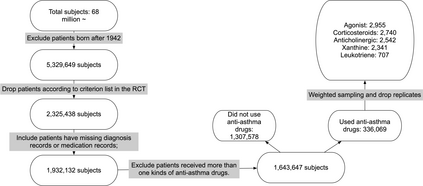
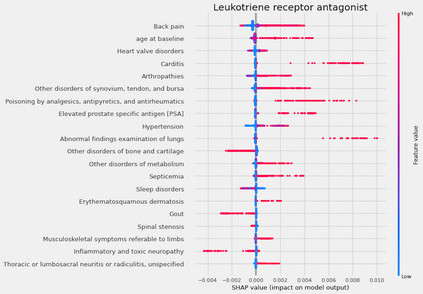
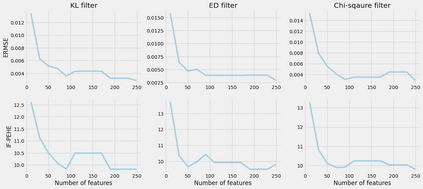
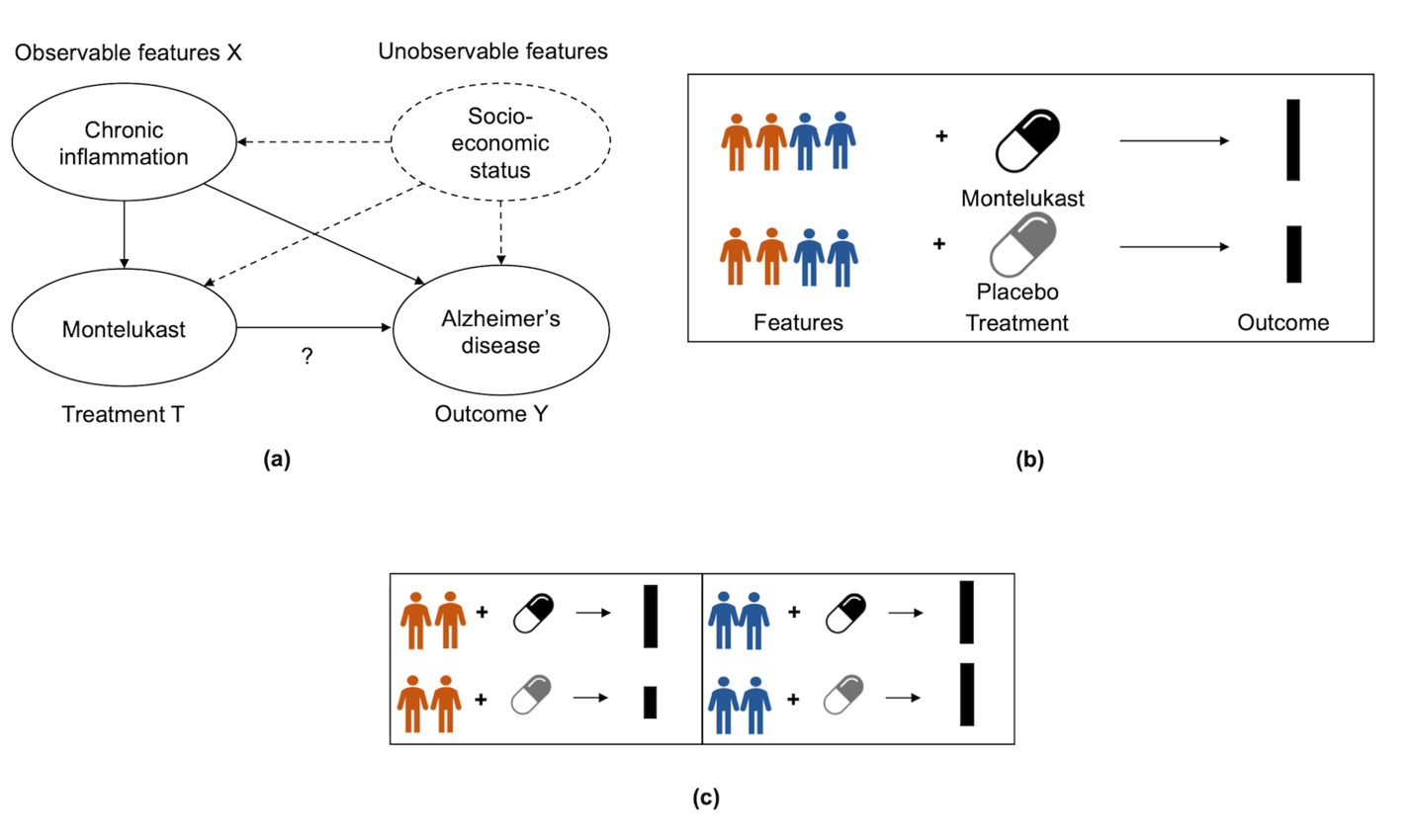
Developing new drugs for target diseases is a time-consuming and expensive task, drug repurposing has become a popular topic in the drug development field. As much health claim data become available, many studies have been conducted on the data. The real-world data is noisy, sparse, and has many confounding factors. In addition, many studies have shown that drugs effects are heterogeneous among the population. Lots of advanced machine learning models about estimating heterogeneous treatment effects (HTE) have emerged in recent years, and have been applied to in econometrics and machine learning communities. These studies acknowledge medicine and drug development as the main application area, but there has been limited translational research from the HTE methodology to drug development. We aim to introduce the HTE methodology to the healthcare area and provide feasibility consideration when translating the methodology with benchmark experiments on healthcare administrative claim data. Also, we want to use benchmark experiments to show how to interpret and evaluate the model when it is applied to healthcare research. By introducing the recent HTE techniques to a broad readership in biomedical informatics communities, we expect to promote the wide adoption of causal inference using machine learning. We also expect to provide the feasibility of HTE for personalized drug effectiveness.
翻译:针对目标疾病开发新药物是一项耗时费时且昂贵的任务,在药物开发领域,重新规划药物已成为一个流行话题。随着大量健康要求数据,已经对数据进行了许多研究。真实世界数据繁杂、稀少,而且有许多混乱因素。此外,许多研究显示,人口中的药物影响各异。近年来出现了许多关于估计不同治疗效果的先进机器学习模型(HTE),这些模型应用于计量经济和机器学习社区。这些研究承认药物和药物开发是主要应用领域,但从HTE方法到药物开发的翻译研究有限。我们的目标是在保健领域采用HTE方法,并在将保健行政要求数据的基准实验方法翻译时提供可行性考虑。此外,我们想利用基准实验来展示在将模型应用于保健研究时如何解释和评价该模型。通过向生物医学信息学界的广大读者介绍最近的HTE技术,我们期望通过机器学习促进广泛采用因果关系推论。我们还期望为HTE个人药物提供可行性。