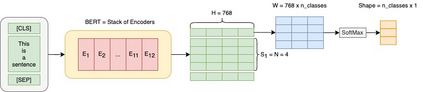
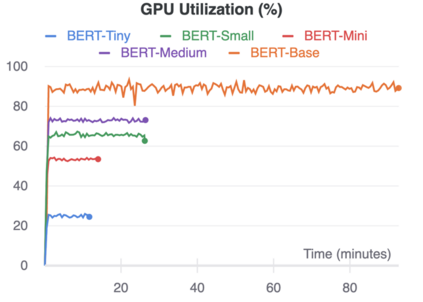
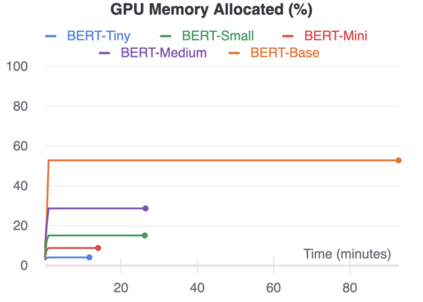
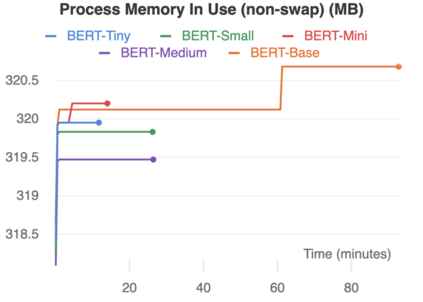
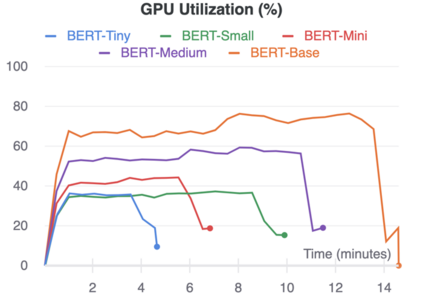
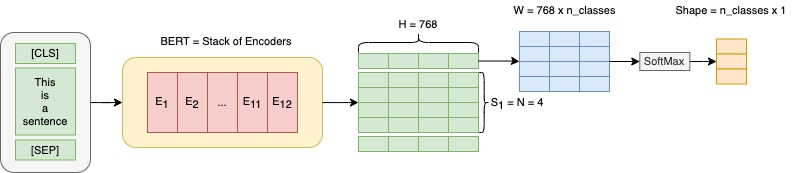
The rise of big data analytics on top of NLP increases the computational burden for text processing at scale. The problems faced in NLP are very high dimensional text, so it takes a high computation resource. The MapReduce allows parallelization of large computations and can improve the efficiency of text processing. This research aims to study the effect of big data processing on NLP tasks based on a deep learning approach. We classify a big text of news topics with fine-tuning BERT used pre-trained models. Five pre-trained models with a different number of parameters were used in this study. To measure the efficiency of this method, we compared the performance of the BERT with the pipelines from Spark NLP. The result shows that BERT without Spark NLP gives higher accuracy compared to BERT with Spark NLP. The accuracy average and training time of all models using BERT is 0.9187 and 35 minutes while using BERT with Spark NLP pipeline is 0.8444 and 9 minutes. The bigger model will take more computation resources and need a longer time to complete the tasks. However, the accuracy of BERT with Spark NLP only decreased by an average of 5.7%, while the training time was reduced significantly by 62.9% compared to BERT without Spark NLP.
翻译:在NLP上方,大数据分析器的上升增加了文本处理的计算负担。 NLP 中面临的问题是高度的文本,因此它需要很高的计算资源。 MapRduce 使得大量计算能够平行进行,并能提高文本处理的效率。这项研究旨在研究大数据处理对NLP任务的影响,其基础是深层次的学习方法。我们用经过预先训练的模型对一个微调的BERT 进行新闻专题的大型文本进行了分类。在这项研究中使用了五个具有不同参数的预培训模型。为了测量这种方法的效率,我们将BERT的性能与Spark NLP 的输油管进行比较。结果显示,没有Spark NLP的BERT与BERT相比,其准确性能更高。使用BERT的所有模型的精度平均和训练时间为0.9187和35分钟,同时使用Spark NLP 管道的BERT的精度为0.8444和9分钟。更大的模型需要更多计算资源并需要更长的时间来完成任务。然而,没有用Spar L的SPR的平均时间缩小了62 NPR的精度。