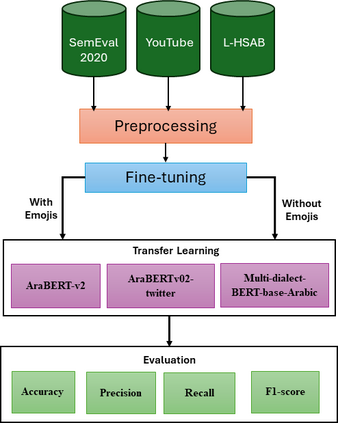
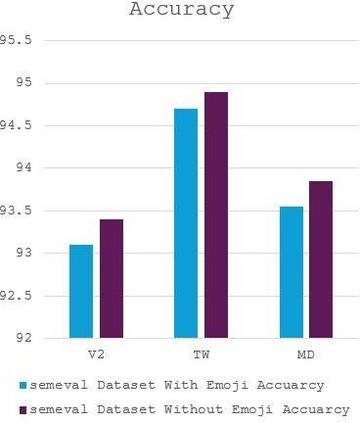
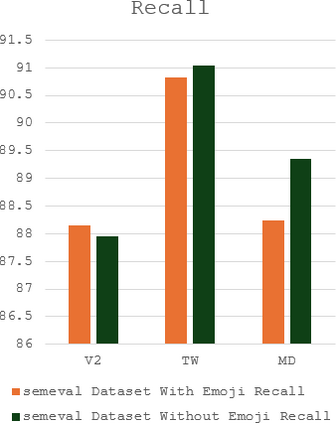
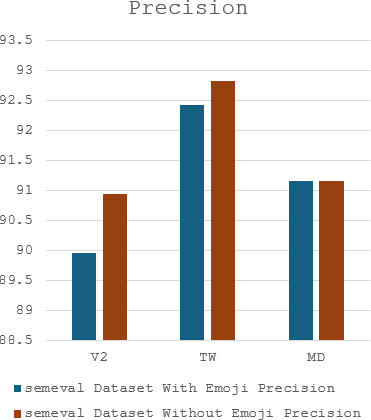
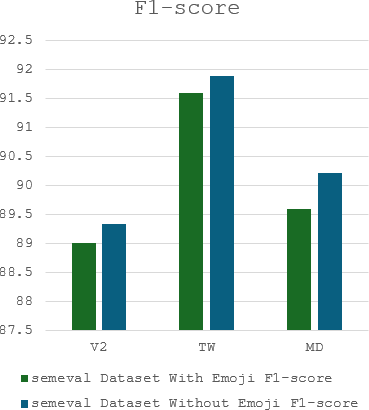
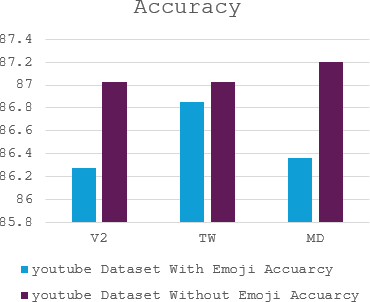
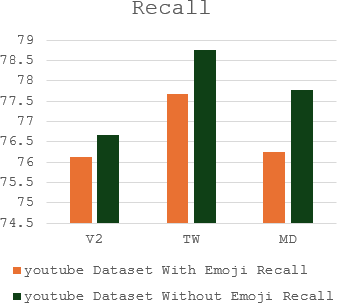
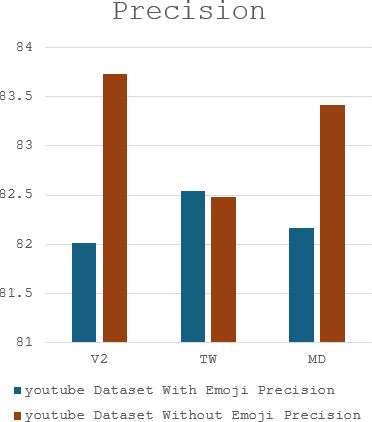
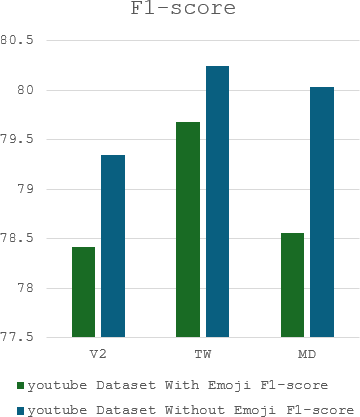
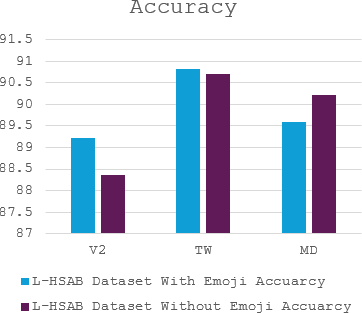
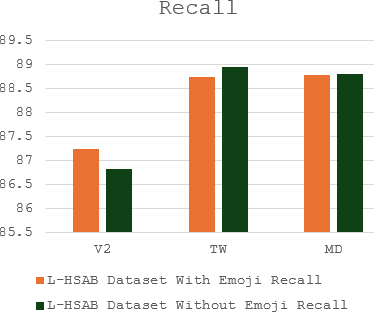
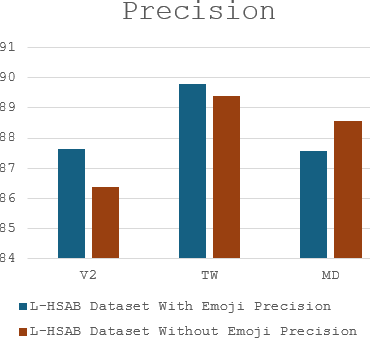
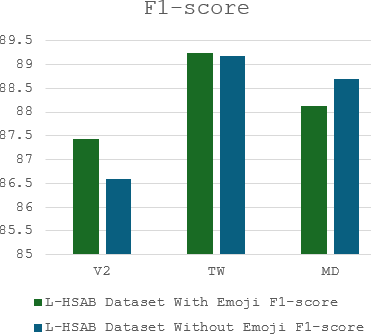
The complex challenge of detecting sarcasm in Arabic speech on social media is increased by the language diversity and the nature of sarcastic expressions. There is a significant gap in the capability of existing models to effectively interpret sarcasm in Arabic, which mandates the necessity for more sophisticated and precise detection methods. In this paper, we investigate the impact of a fundamental preprocessing component on sarcasm speech detection. While emojis play a crucial role in mitigating the absence effect of body language and facial expressions in modern communication, their impact on automated text analysis, particularly in sarcasm detection, remains underexplored. We investigate the impact of emoji exclusion from datasets on the performance of sarcasm detection models in social media content for Arabic as a vocabulary-super rich language. This investigation includes the adaptation and enhancement of AraBERT pre-training models, specifically by excluding emojis, to improve sarcasm detection capabilities. We use AraBERT pre-training to refine the specified models, demonstrating that the removal of emojis can significantly boost the accuracy of sarcasm detection. This approach facilitates a more refined interpretation of language, eliminating the potential confusion introduced by non-textual elements. The evaluated AraBERT models, through the focused strategy of emoji removal, adeptly navigate the complexities of Arabic sarcasm. This study establishes new benchmarks in Arabic natural language processing and presents valuable insights for social media platforms.
翻译:暂无翻译