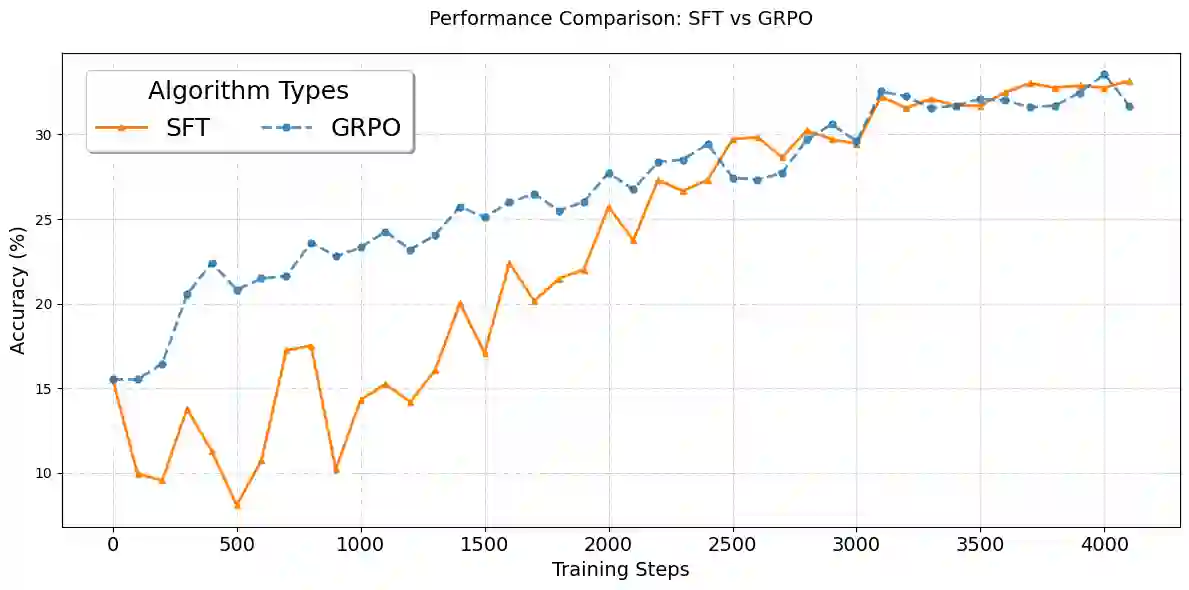
Multimodal Large Language Models (MLLMs) have gained significant traction for their ability to process diverse input data types and generate coherent, contextually relevant outputs across various applications. While supervised fine-tuning (SFT) has been the predominant approach to enhance MLLM capabilities in task-specific optimization, it often falls short in fostering crucial generalized reasoning abilities. Although reinforcement learning (RL) holds great promise in overcoming these limitations, it encounters two significant challenges: (1) its generalized capacities in multimodal tasks remain largely unexplored, and (2) its training constraints, including the constant Kullback-Leibler divergence or the clamp strategy, often result in suboptimal bottlenecks. To address these challenges, we propose OThink-MR1, an advanced MLLM equipped with profound comprehension and reasoning capabilities across multimodal tasks. Specifically, we introduce Group Relative Policy Optimization with a dynamic Kullback-Leibler strategy (GRPO-D), which markedly enhances reinforcement learning (RL) performance. For Qwen2-VL-2B-Instruct, GRPO-D achieves a relative improvement of more than 5.72% over SFT and more than 13.59% over GRPO in same-task evaluation on two adapted datasets. Furthermore, GRPO-D demonstrates remarkable cross-task generalization capabilities, with an average relative improvement of more than 61.63% over SFT in cross-task evaluation. These results highlight that the MLLM trained with GRPO-D on one multimodal task can be effectively transferred to another task, underscoring the superior generalized reasoning capabilities of our proposed OThink-MR1 model.
翻译:暂无翻译