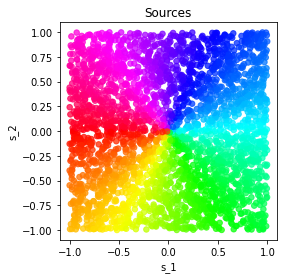
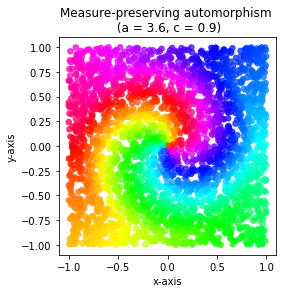
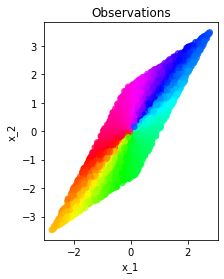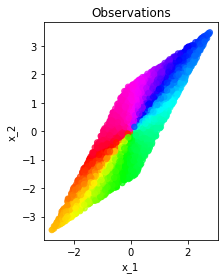Model identifiability is a desirable property in the context of unsupervised representation learning. In absence thereof, different models may be observationally indistinguishable while yielding representations that are nontrivially related to one another, thus making the recovery of a ground truth generative model fundamentally impossible, as often shown through suitably constructed counterexamples. In this note, we discuss one such construction, illustrating a potential failure case of an identifiability result presented in "Desiderata for Representation Learning: A Causal Perspective" by Wang & Jordan (2021). The construction is based on the theory of nonlinear independent component analysis. We comment on implications of this and other counterexamples for identifiable representation learning.
翻译:模型可识别性是未经监督的代表性学习中的一种可取的财产,如果没有模型,则不同的模型可能是观察不可分的,而不同的模型则会产生互无关联的表达,从而使得从地面真相基因化模型的恢复从根本上成为不可能,这经常通过适当构建的反实例来证明。我们在本说明中讨论了其中一种建构,说明了Wang & Jordan(2021年)在“代表性学习的边际性:因果关系观点”中出现的可识别性结果的潜在失败案例。 建构基于非线性独立组成部分分析理论,我们评论了这一模型和其他反实例对可识别的代表性学习的影响。