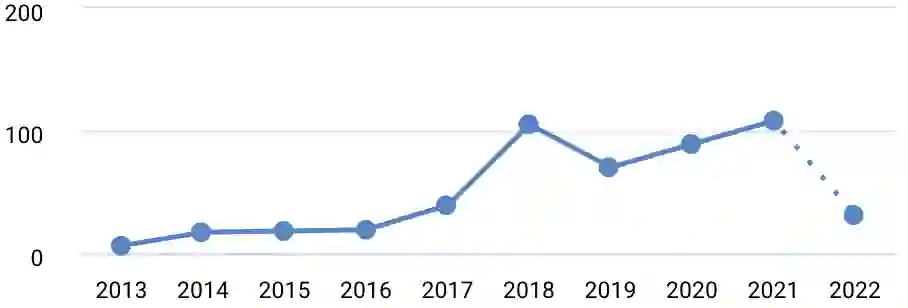
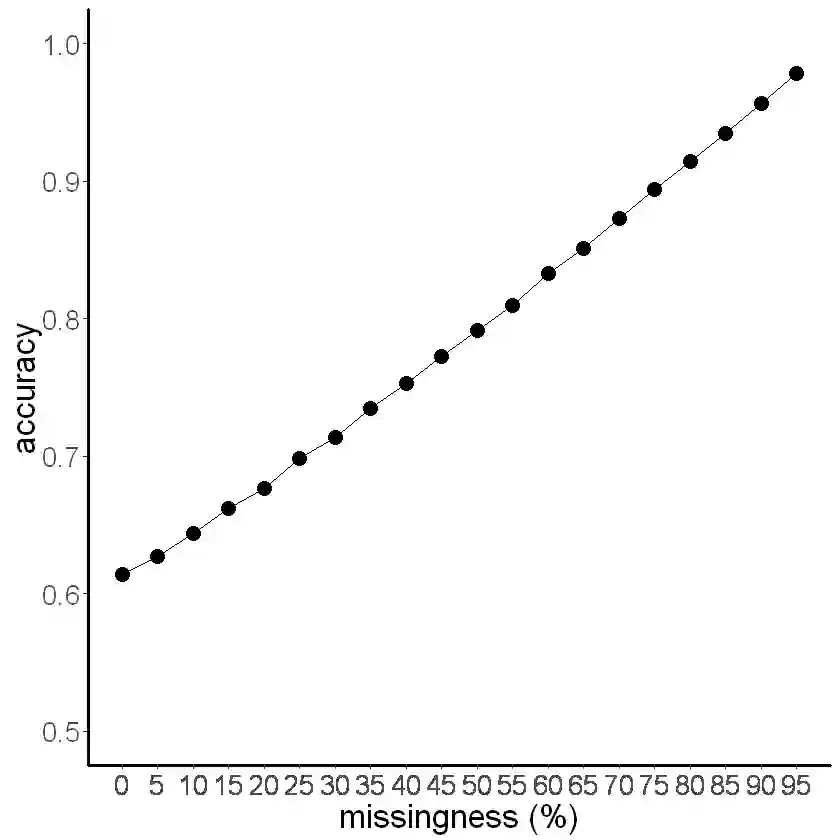
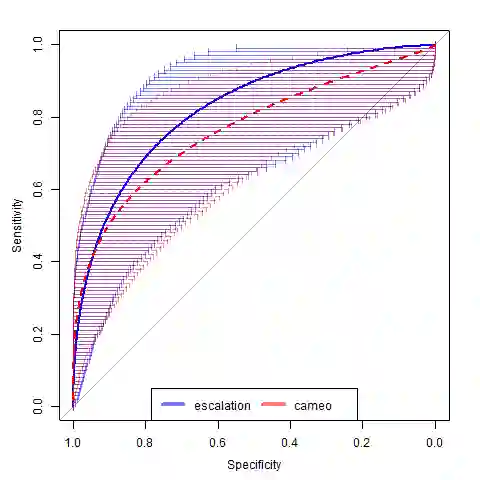
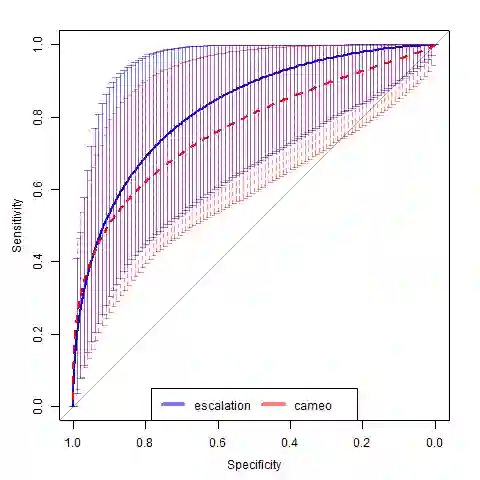
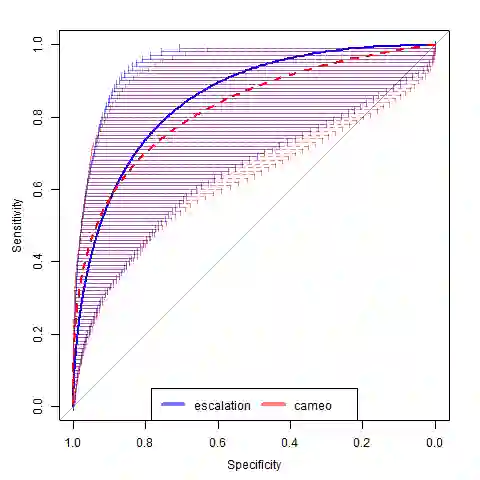
The use of machine learning (ML) methods for prediction and forecasting has become widespread across the quantitative sciences. However, there are many known methodological pitfalls, including data leakage, in ML-based science. In this paper, we systematically investigate reproducibility issues in ML-based science. We show that data leakage is indeed a widespread problem and has led to severe reproducibility failures. Specifically, through a survey of literature in research communities that adopted ML methods, we find 17 fields where errors have been found, collectively affecting 329 papers and in some cases leading to wildly overoptimistic conclusions. Based on our survey, we present a fine-grained taxonomy of 8 types of leakage that range from textbook errors to open research problems. We argue for fundamental methodological changes to ML-based science so that cases of leakage can be caught before publication. To that end, we propose model info sheets for reporting scientific claims based on ML models that would address all types of leakage identified in our survey. To investigate the impact of reproducibility errors and the efficacy of model info sheets, we undertake a reproducibility study in a field where complex ML models are believed to vastly outperform older statistical models such as Logistic Regression (LR): civil war prediction. We find that all papers claiming the superior performance of complex ML models compared to LR models fail to reproduce due to data leakage, and complex ML models don't perform substantively better than decades-old LR models. While none of these errors could have been caught by reading the papers, model info sheets would enable the detection of leakage in each case.
翻译:利用机器学习(ML)方法进行预测和预测在定量科学中已变得广泛。然而,在以ML为基础的科学中,有许多已知的方法缺陷,包括数据泄漏。在本文中,我们系统地调查以ML为基础的科学的复制问题。我们表明,数据泄漏确实是一个普遍的问题,并导致严重的复制失败。具体地说,通过对采用ML方法的研究机构的文献调查,我们发现17个发现错误的领域,这些领域共影响到329份论文,在某些情况下导致错误过于乐观的结论。根据我们的调查,我们提出了8类渗漏的精细分类学,从教科书错误到公开研究问题不等。我们主张对以MLL为基础的科学进行根本的方法改变,以便在出版之前能够发现渗漏案例。为此,我们建议根据ML(ML)模型报告科学索赔的模型,在调查中发现各种类型的渗漏,共同影响到329份论文的复制错误和模型的功效。根据我们的调查,我们没有进行一项精细的分类,我们进行一项从教科书错误到8种渗漏的精细的分类,我们进行一项精确的细的分类研究。我们主张,每个复杂的模型都无法进行这种比较精细的统计模型。