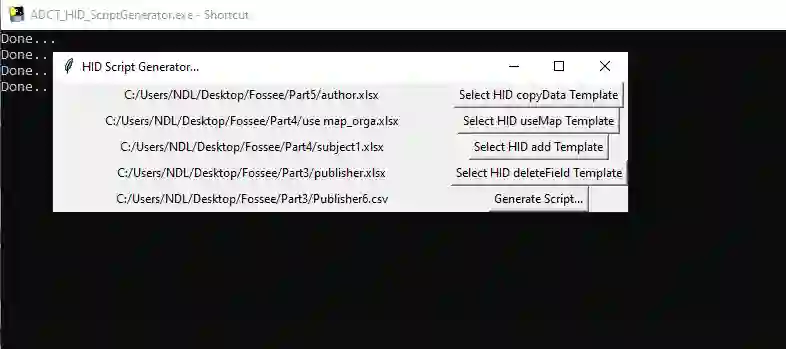
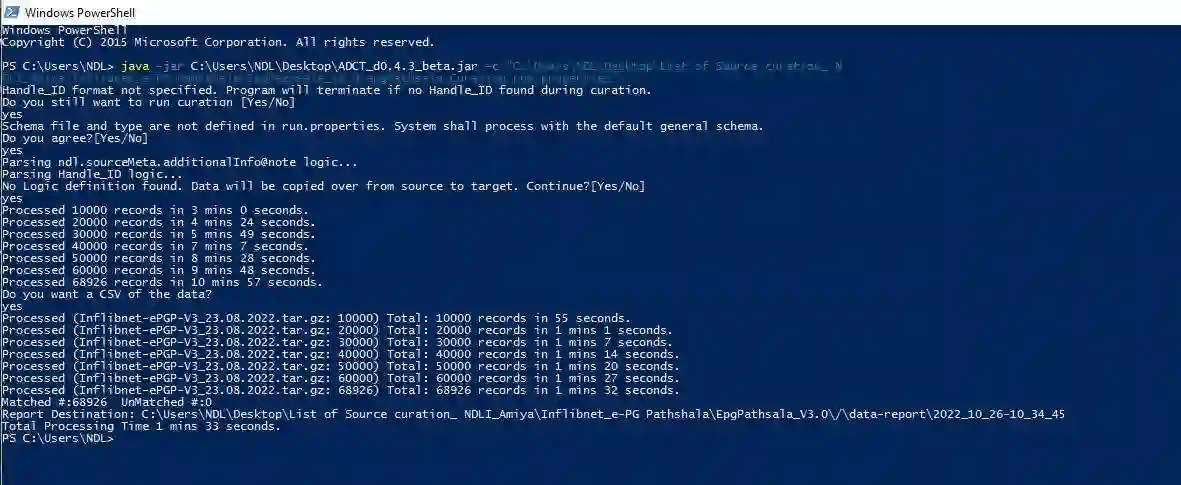
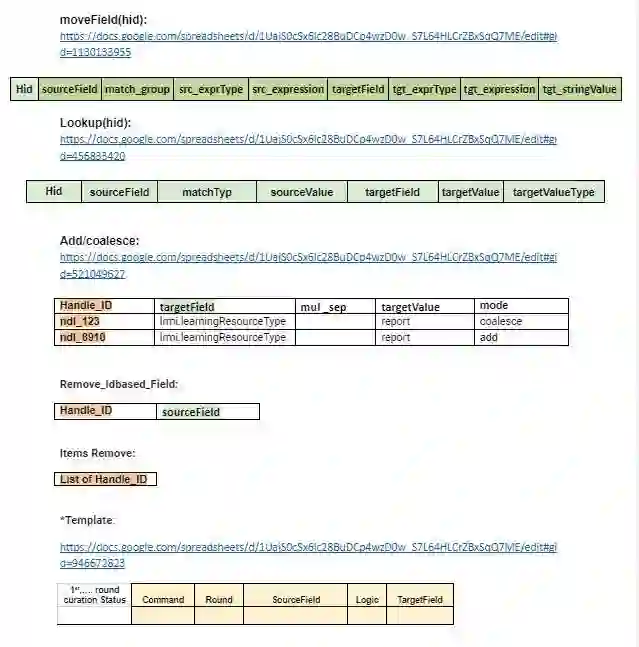
In library and information science, document storage and user-specific document retrieval are the main aspects of digital library services. To preserve the cultural heritage, documents, and literature, we need a common platform where all types of documents are available in a specific format. Our proposed software tool, ADCT can handle a bulk amount of data and transforms different types of raw data into specified metadata information. It generalizes multiple forms of curation logic applied to the source data. As state of the art, many research activities is done in various university to manage their research data in digital library services. The author provides descriptive statistics of library and information service (LIS) activities for information storage and retrieval. The paper shows research on methodology, information gathering, and scientific communication done on library data as an activity of the LIS community. The analysis of LIS data and the change of interest in information storage and retrieval from classification and indexing to retrieval are much important. For Building these types of digitized educational services, automatic data curation is an important stepping stone. The paper shows that automation can complement expertise and knowledge. The author builds an automated data transformation and curation tool that assists users in the analysis of metadata information and effort towards conforming to generic standards using a catalog when a librarian wants to see the adjacent related metadata for an archival collection of congressional correspondence.
翻译:在图书馆和信息科学方面,文献储存和用户专用文件检索是数字图书馆服务的主要方面。为了保存文化遗产、文件和文献,我们需要一个共同的平台,使所有类型的文件都能以特定格式提供。我们提议的软件工具,ADCT可以处理大量的数据,并将不同种类的原始数据转换成指定的元数据信息。它概括了适用于源数据的多种形式的整理逻辑。作为最新情况,许多研究活动是在多所大学进行,以管理数字图书馆服务的研究数据。作者提供了图书馆和信息服务活动的描述性统计数据,供信息储存和检索之用。文件展示了关于方法、信息收集和图书馆数据科学交流的研究,作为LIS社区的一项活动。分析LIS数据以及信息储存和检索的兴趣从分类和索引到检索的改变非常重要。关于建立这些数字化教育服务,自动数据整理是一个重要的垫脚石。文件表明自动化可以补充专门知识和知识。作者制作了一个自动化数据转换和整理工具,用以协助用户分析与图书馆数据相关的数据元数据数据库,以便利用数据库相关的数据库努力,使数据库的用户能够查阅与数据库相关的数据库。