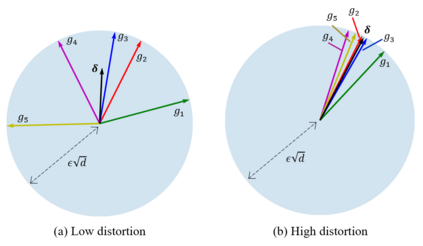
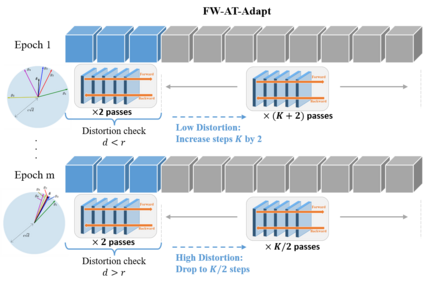
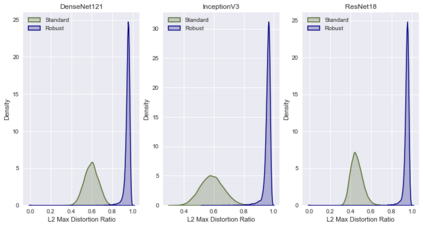
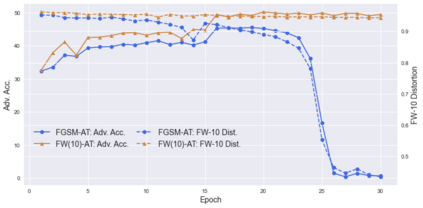
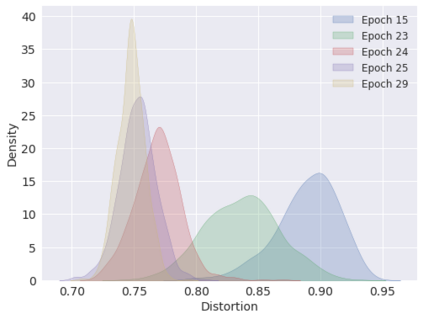
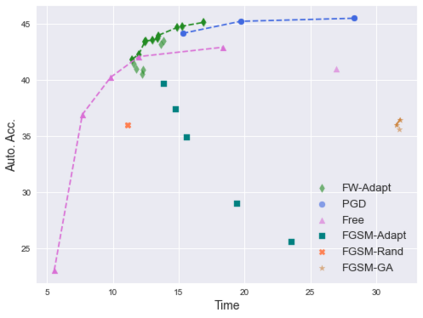
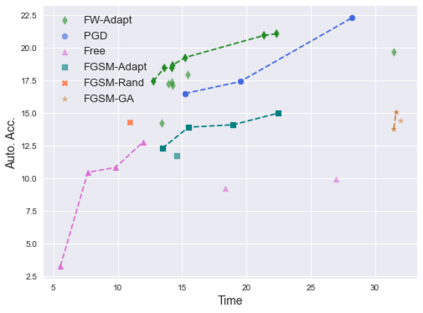
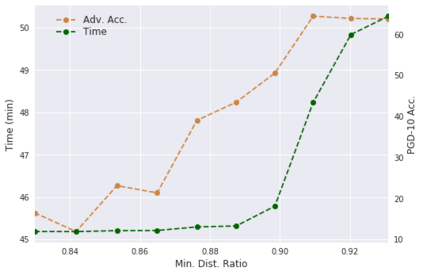
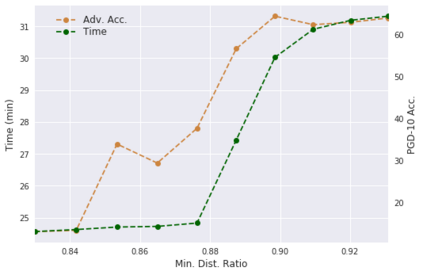
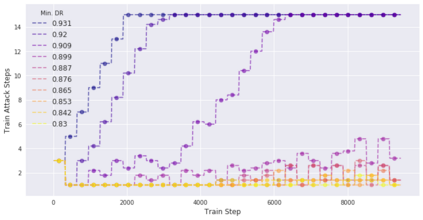
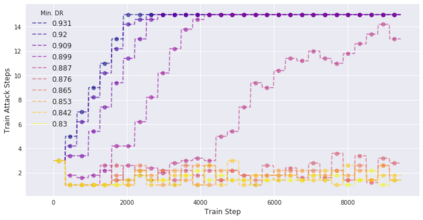
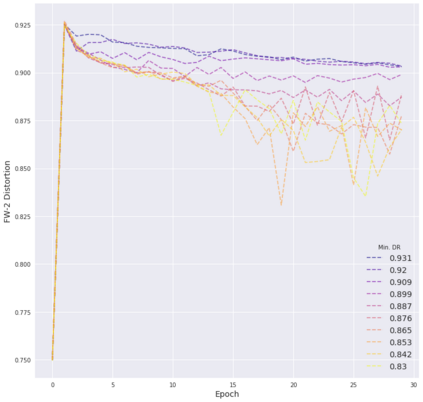
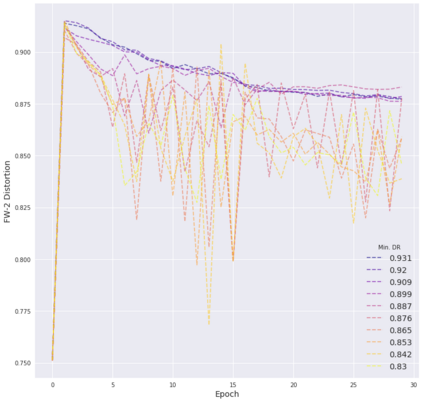
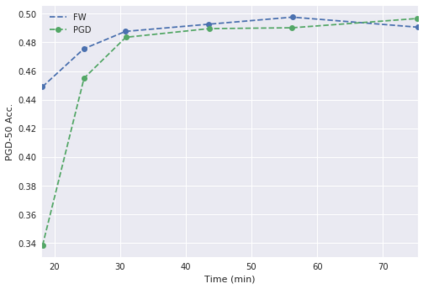
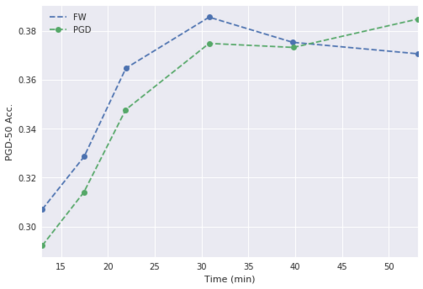
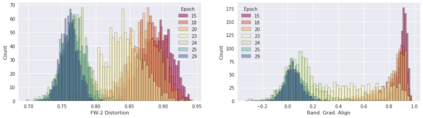
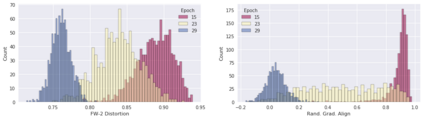
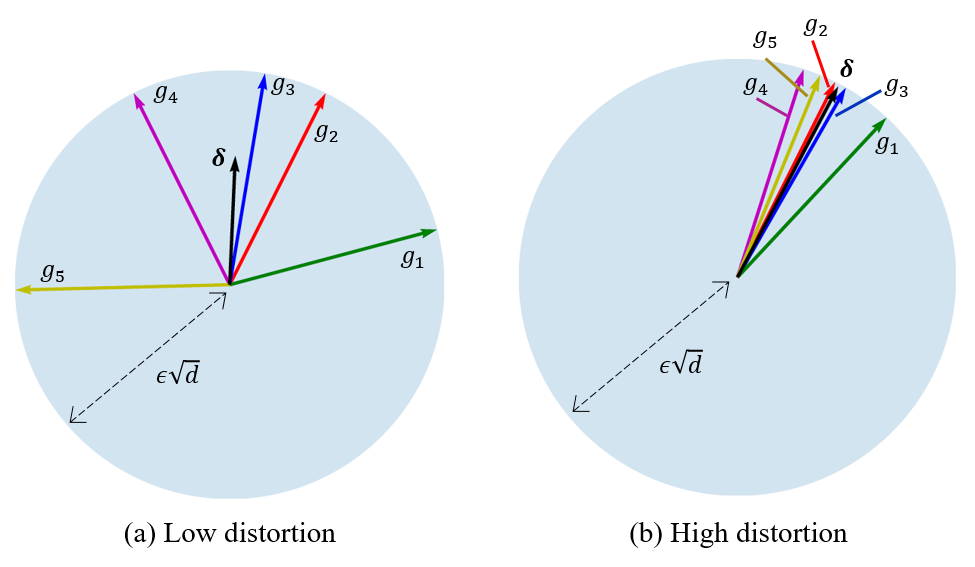
Deep neural networks are easily fooled by small perturbations known as adversarial attacks. Adversarial Training (AT) is a technique that approximately solves a robust optimization problem to minimize the worst-case loss and is widely regarded as the most effective defense against such attacks. Due to the high computation time for generating strong adversarial examples for AT, single-step approaches have been proposed to reduce training time. However, these methods suffer from catastrophic overfitting where adversarial accuracy drops during training. Although improvements have been proposed, they increase training time and robustness is far from that of multi-step AT. We develop a theoretical framework for adversarial training with FW optimization (FW-AT) that reveals a geometric connection between the loss landscape and the $\ell_2$ distortion of $\ell_\infty$ FW attacks. We analytically show that high distortion of FW attacks is equivalent to small gradient variation along the attack path. It is then experimentally demonstrated on various deep neural network architectures that $\ell_\infty$ attacks against robust models achieve near maximal $\ell_2$ distortion, while standard networks have lower distortion. Furthermore, it is experimentally shown that catastrophic overfitting is strongly correlated with low distortion of FW attacks. To demonstrate the utility of our theoretical framework we develop FW-AT-Adapt, a novel adversarial training algorithm which uses a simple distortion measure to adapt the number of attack steps to increase efficiency without compromising robustness. FW-AT-Adapt provides training times on par with single-step fast AT methods and improves closing the gap between fast AT methods and multi-step PGD-AT with minimal loss in adversarial accuracy in white-box and black-box settings.
翻译:深心神经网络很容易被称为对抗性攻击的小规模扰动蒙骗。 反向培训(AT)是一种技术,它大约解决了强力优化问题,以尽量减少最坏情况的损失,并被广泛视为对付此类攻击的最有效防御手段。 由于为AT提供强大的对抗性例子的计算时间太长,因此建议了单步方法来缩短培训时间。然而,这些方法在培训期间对抗性精确度下降的地方存在灾难性的超常状态。虽然提出了改进建议,但它们增加了培训时间和稳健性,远比多步AT的准确性要强。我们开发了一个理论框架,用FW最强优化(FW-AT)来进行对抗性培训,这显示了损失的几何联系。 标准网络在F-A 中提高了成本效率($ell_infty)的扭曲性。 标准网络在F- tral-real-real-real-real-real-deferal-real-lax a lax lax a lax lax lax a lax laimal laction a lax lax a lax a lax lax lax a lax lax lax lax lax lax a lax a lax lax a lax lax lax lax lax lax lax laut lax lax lax lax lax lax) laut a a a lax a lax lax laut lax lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a lax) lax a lax a lax a lax a lax a lax a lax a lax a lax a lax a la la la la la la la la la la la