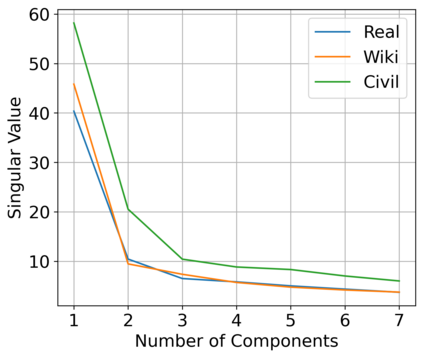
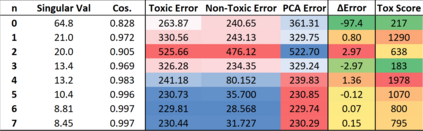
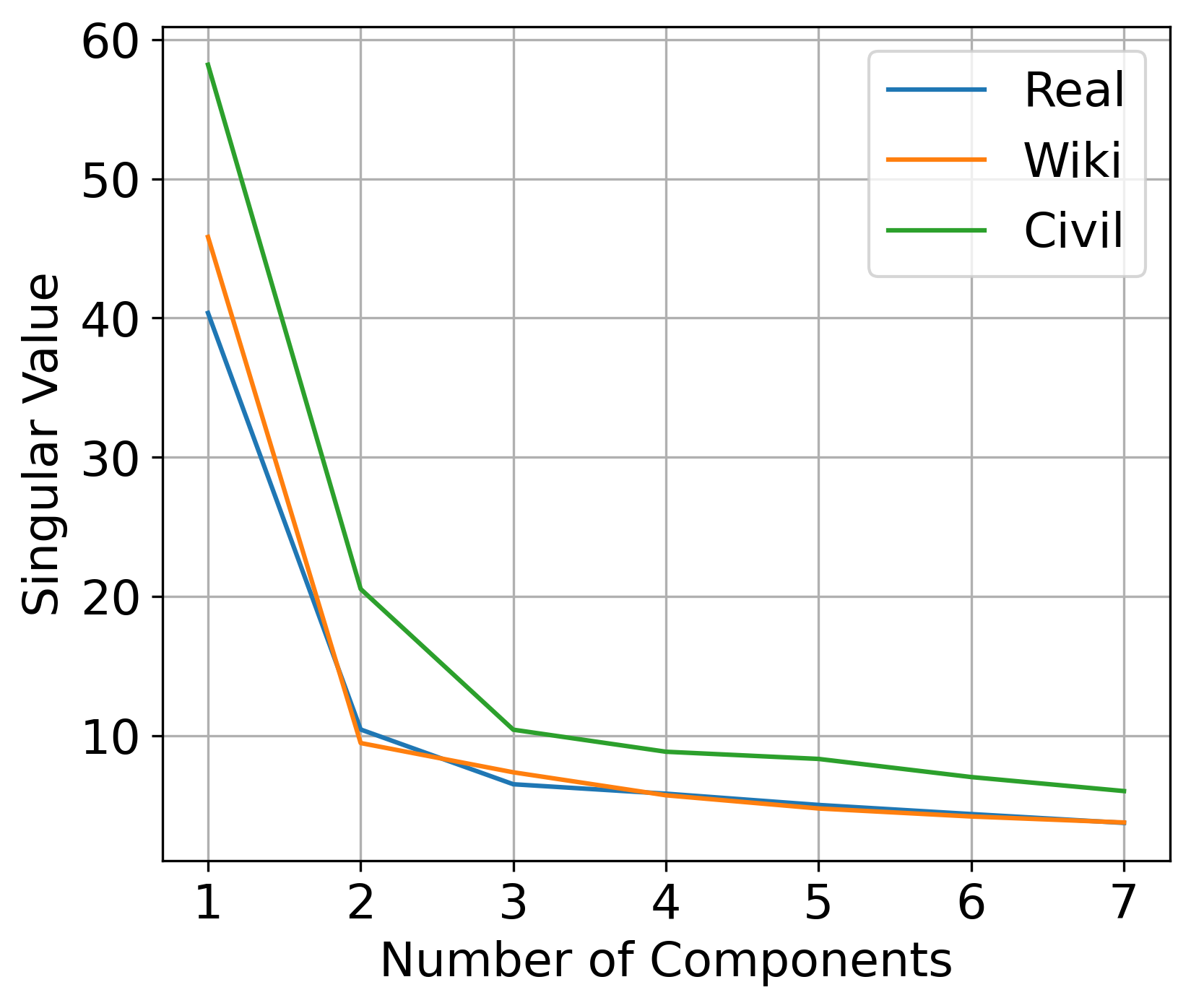
Large pre-trained language models are often trained on large volumes of internet data, some of which may contain toxic or abusive language. Consequently, language models encode toxic information, which makes the real-world usage of these language models limited. Current methods aim to prevent toxic features from appearing generated text. We hypothesize the existence of a low-dimensional toxic subspace in the latent space of pre-trained language models, the existence of which suggests that toxic features follow some underlying pattern and are thus removable. To construct this toxic subspace, we propose a method to generalize toxic directions in the latent space. We also provide a methodology for constructing parallel datasets using a context based word masking system. Through our experiments, we show that when the toxic subspace is removed from a set of sentence representations, almost no toxic representations remain in the result. We demonstrate empirically that the subspace found using our method generalizes to multiple toxicity corpora, indicating the existence of a low-dimensional toxic subspace.
翻译:受过训练的大型语言模型往往在大量互联网数据方面接受培训,其中一些数据可能含有有毒或滥用语言。因此,语言模型编码有毒信息,从而限制这些语言模型的实际使用。目前的方法旨在防止产生毒性特征。我们假设在经过训练的语言模型的潜伏空间中存在着低维有毒亚空间,这表明有毒特征遵循了某种基本模式,因此是可以拆除的。为了构建这一有毒子空间,我们建议了一种方法,在潜藏空间中概括毒性方向。我们还提供了一种方法,用一种基于上下文的字面遮罩系统构建平行数据集。我们通过实验表明,当有毒亚空间从一组句子表达中去除时,结果中几乎没有任何毒性表现。我们从经验上表明,我们用方法发现的子空间一般地概括了多种毒性子空间,表明存在一种低维毒性子空间。