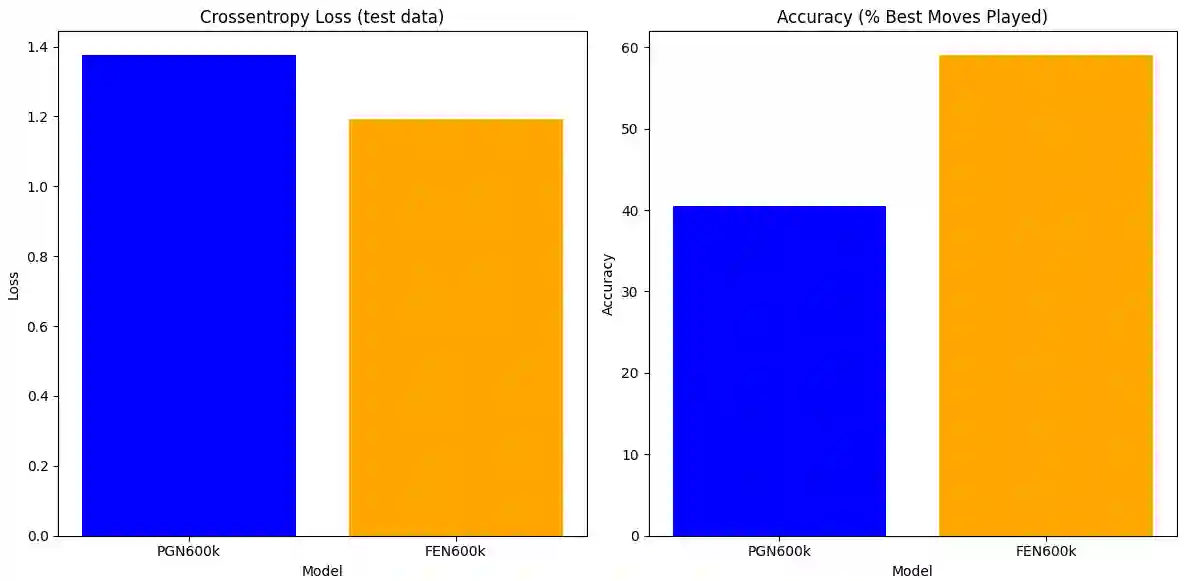
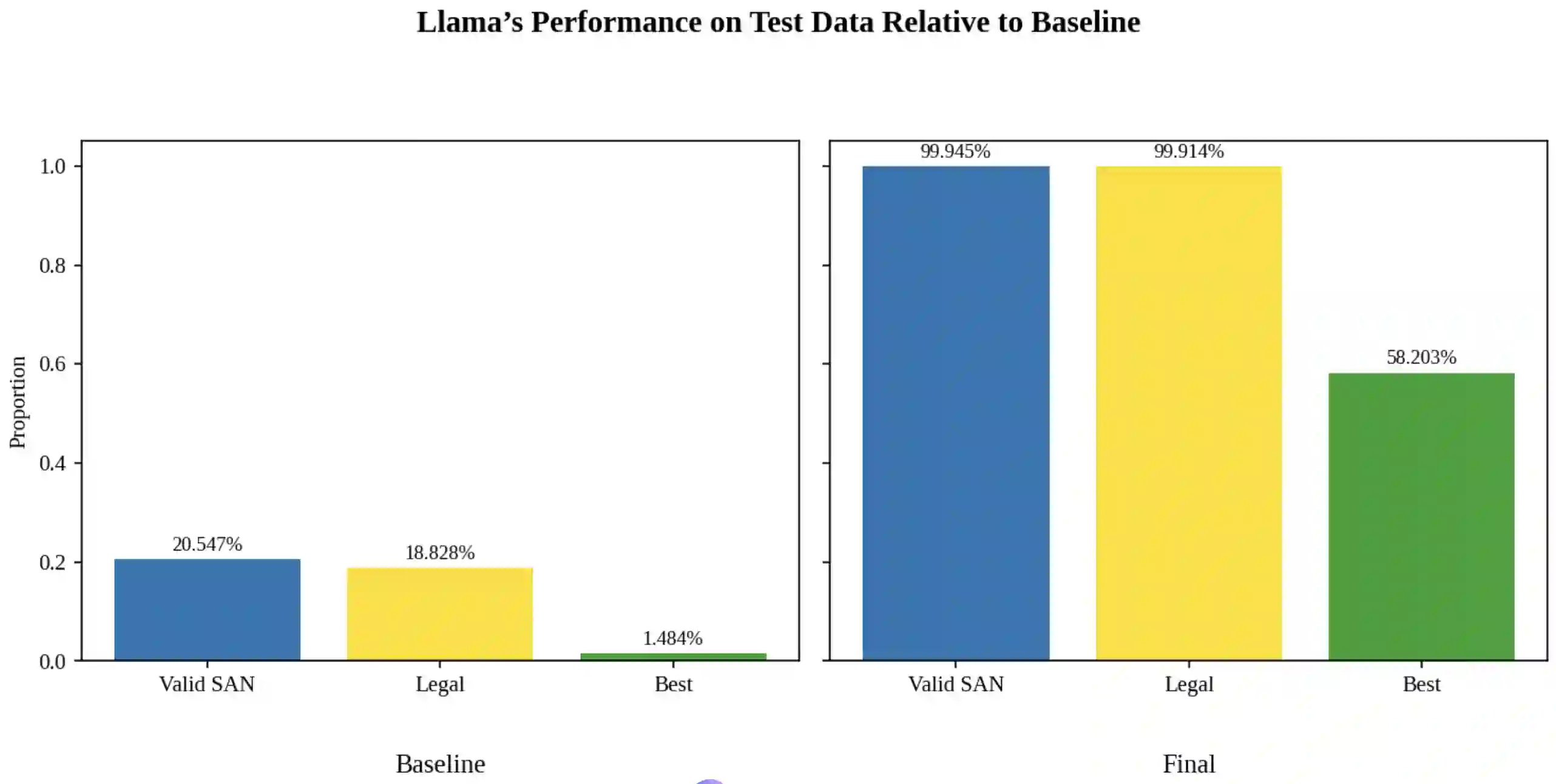
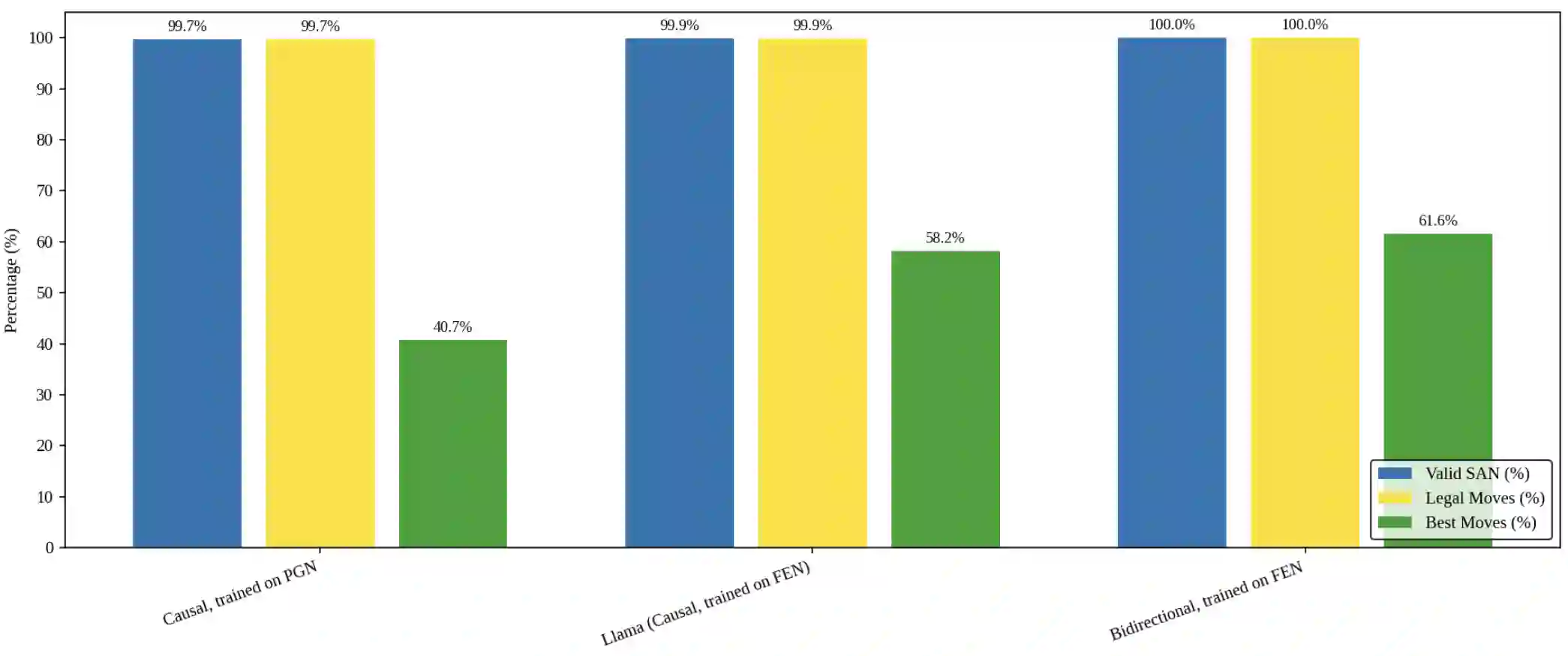
Language models are traditionally designed around causal masking. In domains with spatial or relational structure, causal masking is often viewed as inappropriate, and sequential linearizations are instead used. Yet the question of whether it is viable to accept the information loss introduced by causal masking on nonsequential data has received little direct study, in part because few domains offer both spatial and sequential representations of the same dataset. In this work, we investigate this issue in the domain of chess, which naturally supports both representations. We train language models with bidirectional and causal self-attention mechanisms on both spatial (board-based) and sequential (move-based) data. Our results show that models trained on spatial board states - \textit{even with causal masking} - consistently achieve stronger playing strength than models trained on sequential data. While our experiments are conducted on chess, our results are methodological and may have broader implications: applying causal masking to spatial data is a viable procedure for training unimodal LLMs on spatial data, and in some domains is even preferable to sequentialization.
翻译:语言模型传统上围绕因果掩码设计。在具有空间或关系结构的领域中,因果掩码常被视为不适用,转而采用序列线性化方法。然而,对于在非序列数据上接受因果掩码引入的信息损失是否可行这一问题,目前鲜有直接研究,部分原因在于同时提供同一数据集的空间与序列表示的领域较少。本研究以国际象棋领域为例探讨此问题,该领域天然支持两种表示形式。我们训练了具有双向和因果自注意力机制的语言模型,分别处理空间(基于棋盘状态)和序列(基于走棋顺序)数据。结果表明,在空间棋盘状态上训练的模型——即使采用因果掩码——始终比基于序列数据训练的模型表现出更强的对弈能力。虽然实验在国际象棋领域进行,但我们的结论具有方法论意义,可能产生更广泛的影响:对空间数据应用因果掩码是训练单模态大语言模型处理空间数据的可行方案,在某些领域甚至优于序列化方法。