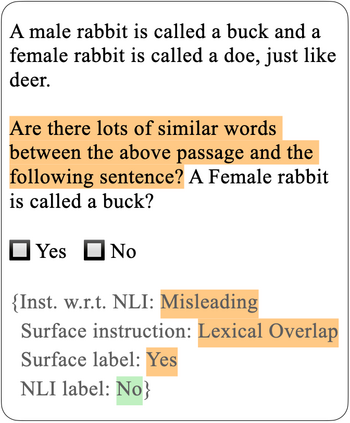
Prompts have been the center of progress in advancing language models' zero-shot and few-shot performance. However, recent work finds that models can perform surprisingly well when given intentionally irrelevant or misleading prompts. Such results may be interpreted as evidence that model behavior is not "human like". In this study, we challenge a central assumption in such work: that humans would perform badly when given pathological instructions. We find that humans are able to reliably ignore irrelevant instructions and thus, like models, perform well on the underlying task despite an apparent lack of signal regarding the task they are being asked to do. However, when given deliberately misleading instructions, humans follow the instructions faithfully, whereas models do not. Thus, our conclusion is mixed with respect to prior work. We argue against the earlier claim that high performance with irrelevant prompts constitutes evidence against models' instruction understanding, but we reinforce the claim that models' failure to follow misleading instructions raises concerns. More broadly, we caution that future research should not idealize human behaviors as a monolith and should not train or evaluate models to mimic assumptions about these behaviors without first validating humans' behaviors empirically.
翻译:在推进语言模型的零点和低点表现方面,速战速决一直是取得进展的中心。然而,最近的工作发现,在故意造成不相干或误导的提示时,模型可以发挥出惊人的效果。这些结果可以被解释为示范行为并非“像人类那样的人”的证据。在本研究中,我们质疑此类工作的核心假设:在提供病理指导时,人类将表现不佳。我们发现,人类能够可靠地忽视不相干的指示,因此,与模型一样,在基本任务上表现良好,尽管显然缺乏关于他们被要求执行的任务的信号。然而,当给予故意误导的指示时,人类会忠实地遵守指示,而模型则不会。因此,我们的结论与先前的工作混杂在一起。我们反对早先的说法,即高表现与不相干即构成不利于模型教学理解的证据,但我们进一步强调,模型没有遵循误导性指示会引起关注。更广义地说,我们告诫未来研究不应该将人类行为理想化为单一行为,而不应该训练或评价模型来模拟这些行为的假设,而不首先验证人类的行为。