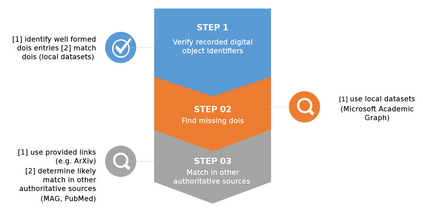
Datasets explicitly linking publications to funding at project level are the basis of evaluative bibliometric analysis of funding programmes. Analysis of the impact of the EU funding programmes has been often frustrated by the lack of data on publications to which the funding has contributed. Here we present a dataset of scholarly publications reported by the projects funded by the European Union under the 7th Framework Programme. The dataset was created by first consolidating data from different reporting channels and validating the records by systematically matching them to external authoritative sources and assigning them external identifiers. The initial dataset had 305k records linked to one or more projects out of which 69% had a digital object identify (doi). Through the data quality assurance, we validate 93% of the initial records (283k) and assign a doi to 90% of them of them (245k). The resulting dataset has 245k unique dois (linked to one or more projects). It is, to our knowledge, the first comprehensive and curated dataset of scholarly outputs of the Framework Programme as reported by the grant holders. The dataset could only be created thanks to significant improvements and investments made in the reporting systems used by EU funded projects. The dataset is available EU open data portal: https://data.europa.eu/data/datasets/cordisfp7projects
翻译:将出版物与项目一级供资明确挂钩的数据集是供资方案评价二元分析的基础。对欧盟供资方案的影响的分析往往因缺少关于供资所资助的出版物的数据而受挫。我们在这里展示了欧洲联盟资助项目在第7个框架方案下报告的学术出版物数据集。数据集最初通过将不同报告渠道的数据与外部权威来源系统地匹配并指定外部识别资料,从而验证记录,从而创建了数据集。初始数据集有305k个记录与一个或多个项目链接,其中69%的项目有数字对象识别(doi)。通过数据质量保证,我们验证了93%的初始记录(283k),并将其中的90%指定为Doi(245k)。由此产生的数据集有245k独有的版本(与一个或多个项目相关)。据我们所知,这是由赠款持有者报告的《框架方案》首次全面和整理的学术产出数据集。数据集的创建只能归功于欧盟供资/数据门户使用的报告系统的重大改进和投资。现有数据是:httpeurdata/httpeurdata。