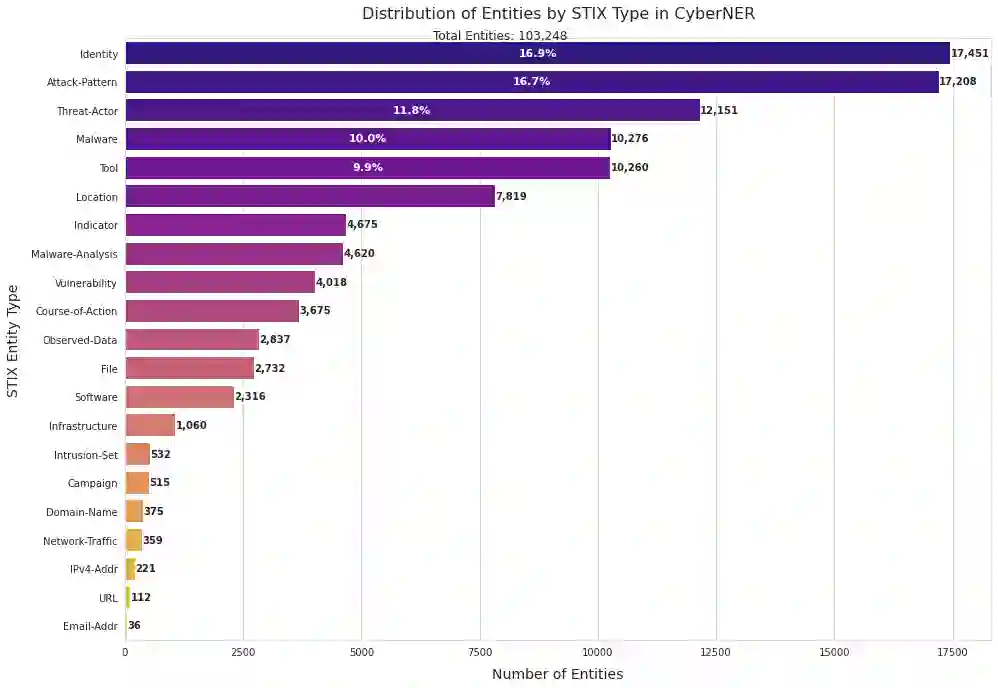
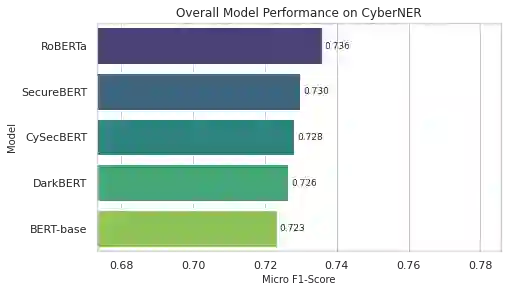
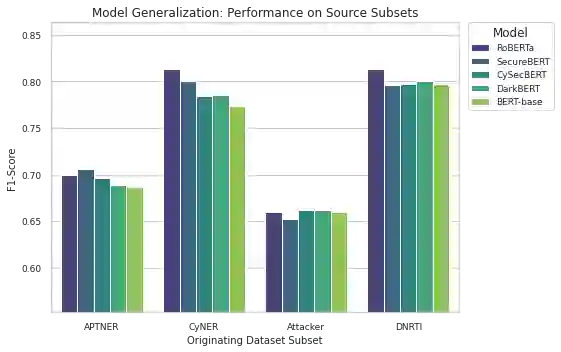
Extracting structured intelligence via Named Entity Recognition (NER) is critical for cybersecurity, but the proliferation of datasets with incompatible annotation schemas hinders the development of comprehensive models. While combining these resources is desirable, we empirically demonstrate that naively concatenating them results in a noisy label space that severely degrades model performance. To overcome this critical limitation, we introduce CyberNER, a large-scale, unified corpus created by systematically harmonizing four prominent datasets (CyNER, DNRTI, APTNER, and Attacker) onto the STIX 2.1 standard. Our principled methodology resolves semantic ambiguities and consolidates over 50 disparate source tags into 21 coherent entity types. Our experiments show that models trained on CyberNER achieve a substantial performance gain, with a relative F1-score improvement of approximately 30% over the naive concatenation baseline. By publicly releasing the CyberNER corpus, we provide a crucial, standardized benchmark that enables the creation and rigorous comparison of more robust and generalizable entity extraction models for the cybersecurity domain.
翻译:通过命名实体识别(NER)提取结构化情报对于网络安全至关重要,但具有不兼容标注模式的数据集激增阻碍了综合性模型的发展。尽管整合这些资源是可取的,但我们通过实证研究表明,简单地拼接它们会产生一个嘈杂的标签空间,严重降低模型性能。为克服这一关键局限,我们引入了CyberNER,这是一个通过系统性地将四个重要数据集(CyNER、DNRTI、APTNER和Attacker)统一至STIX 2.1标准而构建的大规模、统一语料库。我们的原则性方法解决了语义歧义,并将超过50个不同的源标签整合为21个一致的实体类型。实验表明,在CyberNER上训练的模型实现了显著的性能提升,其F1分数相对于简单拼接基线提高了约30%。通过公开发布CyberNER语料库,我们提供了一个关键的标准化基准,使得网络安全领域能够创建并严格比较更鲁棒、更可泛化的实体抽取模型。