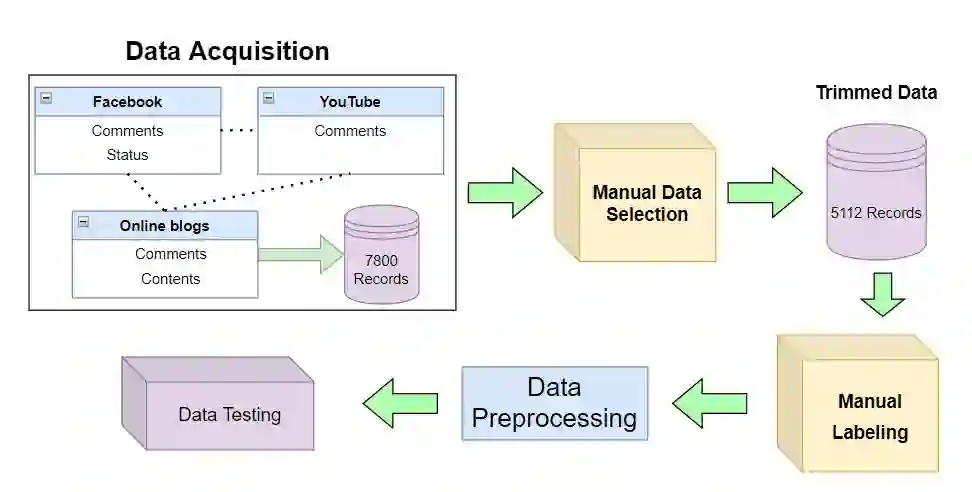
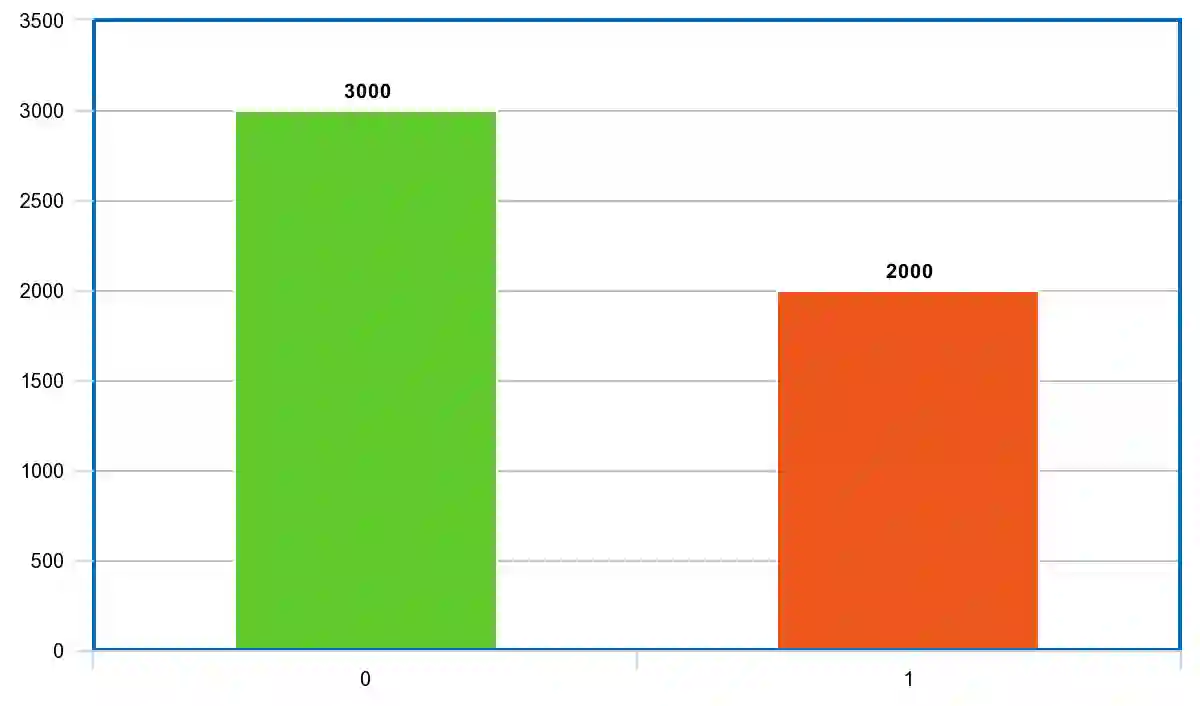
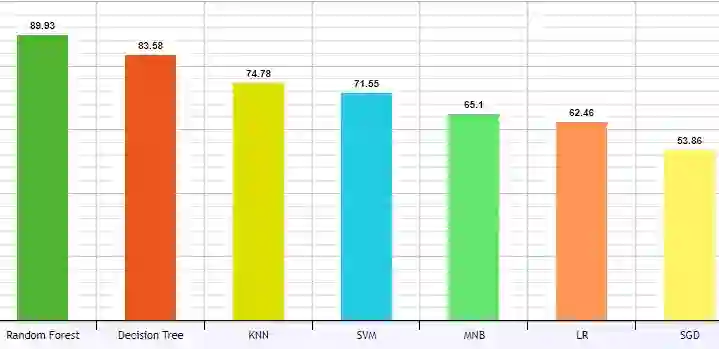
Being one of the most widely spoken language in the world, the use of Bangla has been increasing in the world of social media as well. Sarcasm is a positive statement or remark with an underlying negative motivation that is extensively employed in today's social media platforms. There has been a significant improvement in sarcasm detection in English over the previous many years, however the situation regarding Bangla sarcasm detection remains unchanged. As a result, it is still difficult to identify sarcasm in bangla, and a lack of high-quality data is a major contributing factor. This article proposes BanglaSarc, a dataset constructed specifically for bangla textual data sarcasm detection. This dataset contains of 5112 comments/status and contents collected from various online social platforms such as Facebook, YouTube, along with a few online blogs. Due to the limited amount of data collection of categorized comments in Bengali, this dataset will aid in the of study identifying sarcasm, recognizing people's emotion, detecting various types of Bengali expressions, and other domains. The dataset is publicly available at https://www.kaggle.com/datasets/sakibapon/banglasarc.
翻译:作为世界上最广泛使用的语言之一,孟加拉语的使用在社交媒体世界中也一直在增加。讽刺是一种积极的言论或言论,其基本负面动机在今天的社会媒体平台中广泛使用。在过去几年里,英语的讽刺讽刺性探测有了显著改善,但孟加拉语讽刺性探测情况仍然未变。因此,在Bangla中仍然难以辨别讽刺的讽刺,缺乏高质量的数据是一个主要促成因素。这篇文章提出了BanglaSarc,这是专门为Hangla文本数据讽刺性探测而建造的数据集。该数据集包含从脸书、YouTube等各种在线社会平台收集的5112条评论/状况和内容,以及几个在线博客。由于孟加拉语分类评论的数据收集量有限,该数据集将有助于研究识别讽刺性,承认人们的情感,检测各种孟加拉语表达方式和其他领域。该数据集在https://www.ggle.com/datasetas/datastaysbasion上公开提供。