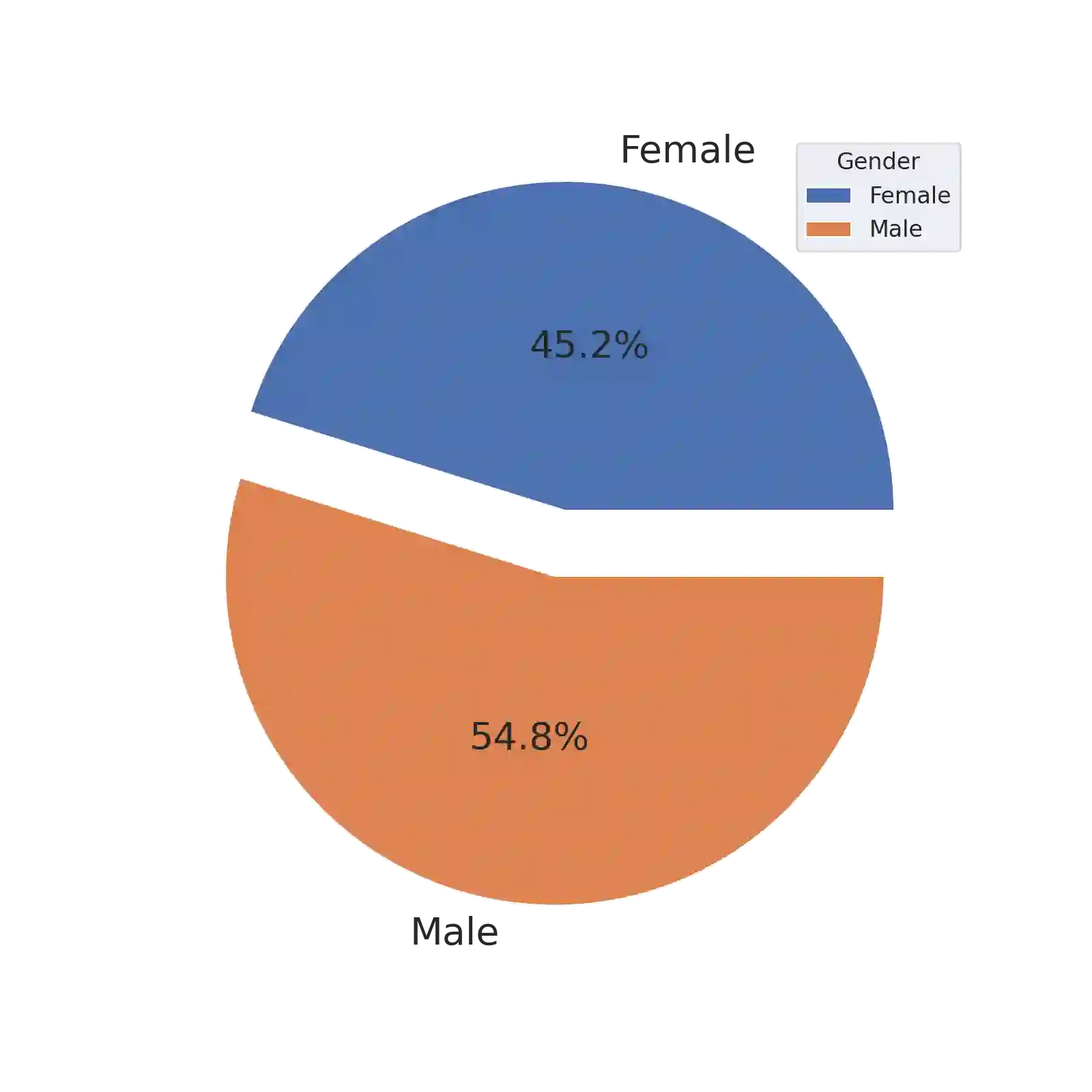
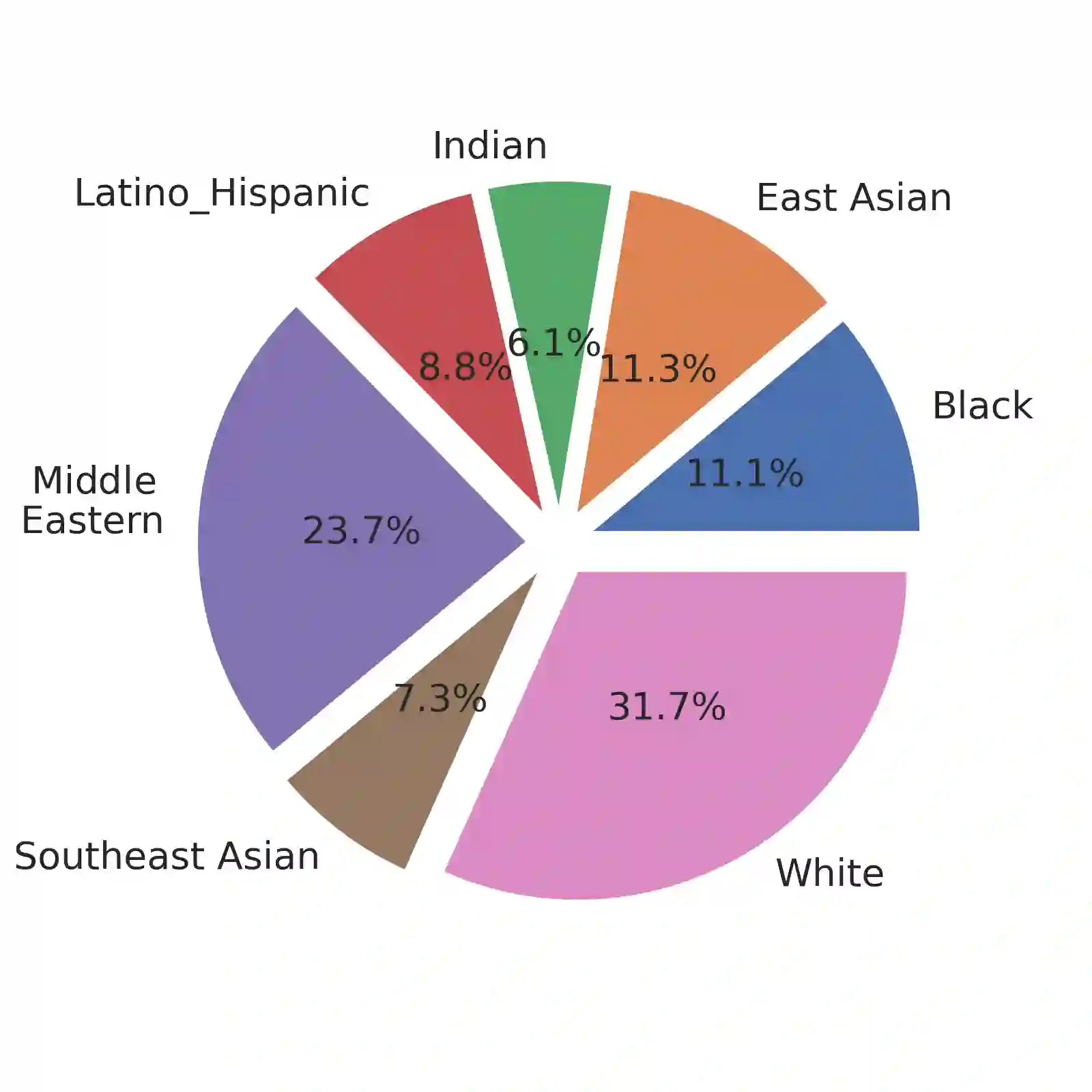
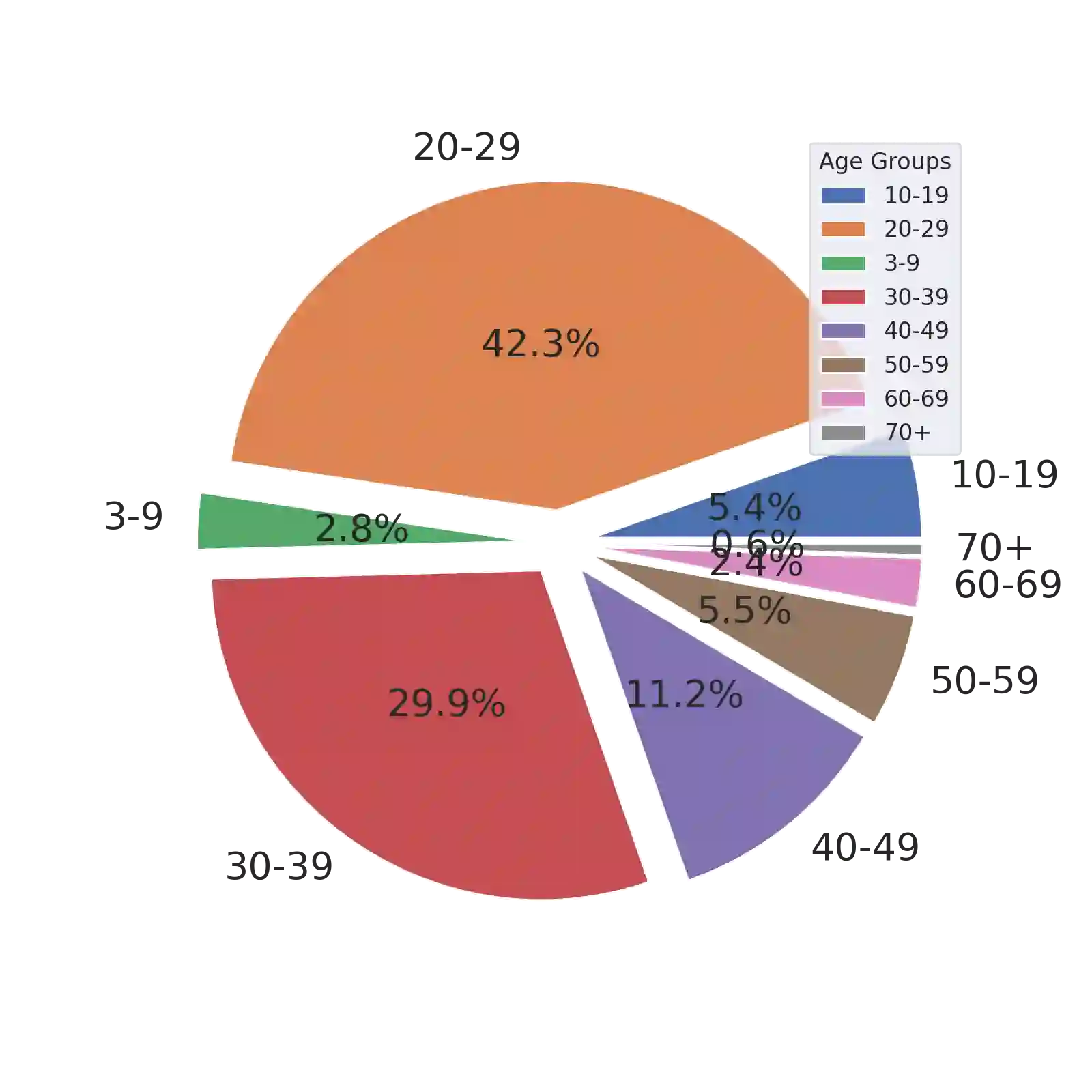
In December 2019, a novel coronavirus (COVID-19) spread so quickly around the world that many countries had to set mandatory face mask rules in public areas to reduce the transmission of the virus. To monitor public adherence, researchers aimed to rapidly develop efficient systems that can detect faces with masks automatically. However, the lack of representative and novel datasets proved to be the biggest challenge. Early attempts to collect face mask datasets did not account for potential race, gender, and age biases. Therefore, the resulting models show inherent biases toward specific race groups, such as Asian or Caucasian. In this work, we present a novel face mask detection dataset that contains images posted on Twitter during the pandemic from around the world. Unlike previous datasets, the proposed Bias-Aware Face Mask Detection (BAFMD) dataset contains more images from underrepresented race and age groups to mitigate the problem for the face mask detection task. We perform experiments to investigate potential biases in widely used face mask detection datasets and illustrate that the BAFMD dataset yields models with better performance and generalization ability. The dataset is publicly available at https://github.com/Alpkant/BAFMD.
翻译:2019年12月,一种新的冠状病毒(COVID-19)迅速传播到世界各地,以至于许多国家不得不在公共领域制定强制性面罩规则,以减少病毒的传播。为了监测公众的遵守情况,研究人员力求迅速发展高效系统,能够自动用面具探测面部。然而,缺乏代表性和新颖的数据集证明是最大的挑战。早期收集面罩数据集的尝试没有考虑到潜在的种族、性别和年龄偏见。因此,由此产生的模型显示了对特定种族群体的固有偏见,如亚洲人或高加索人。在这项工作中,我们展示了一个新的面罩检测数据集,其中载有在大流行病期间张贴在推特上的图像。与以前的数据集不同,拟议的Bias-Aware面具检测(BAFMD)数据集包含来自代表性不足的种族和年龄组的更多图像,以缓解面罩检测任务中的问题。我们进行了实验,以调查广泛使用的面罩检测数据集的潜在偏差,并表明BAFMD数据集生成了更好的性能和一般化能力。数据集于https://github.AF./MD.A./CANcom。