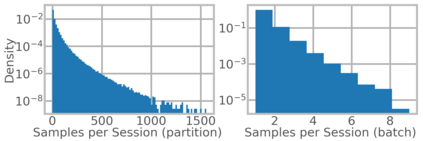
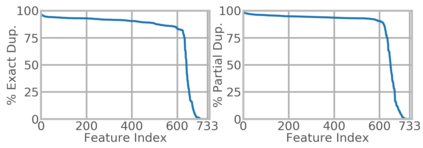
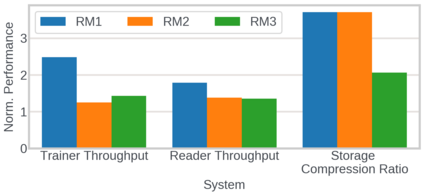
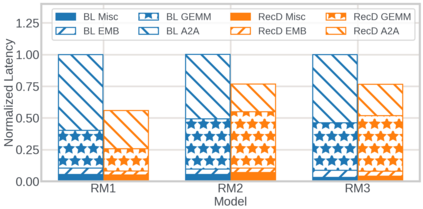
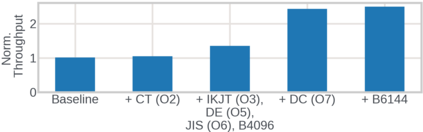
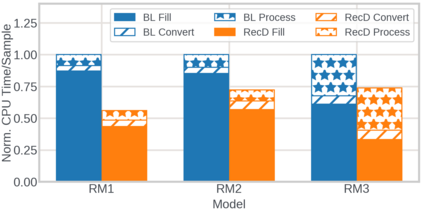
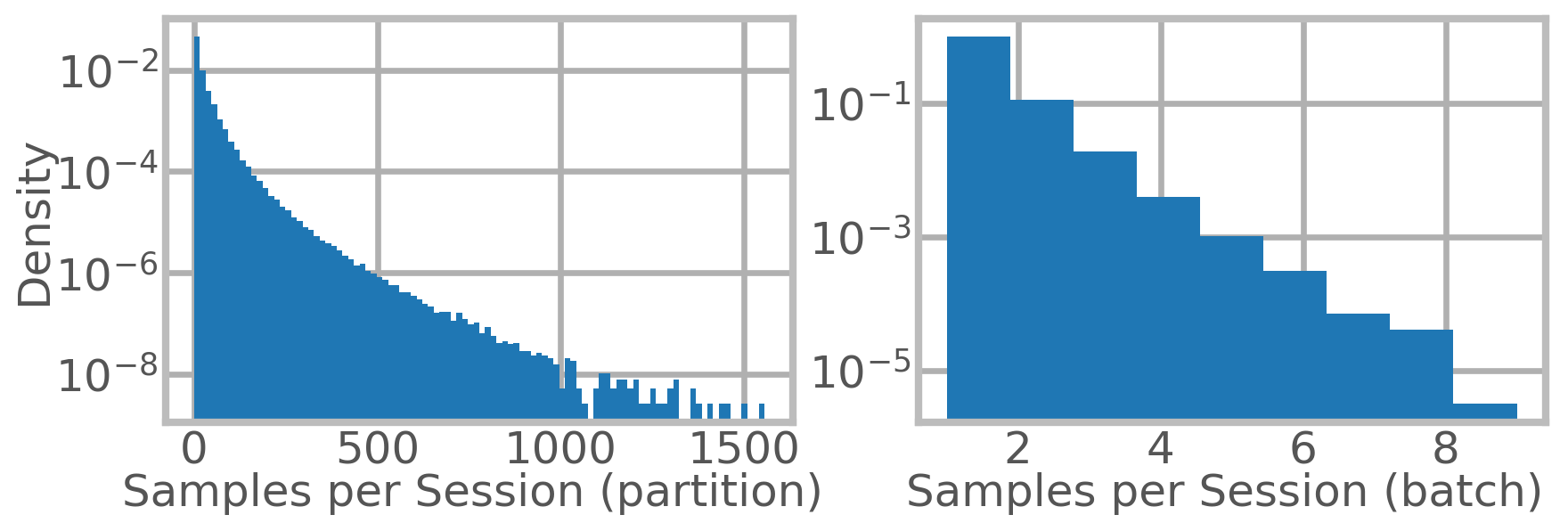
We present RecD (Recommendation Deduplication), a suite of end-to-end infrastructure optimizations across the Deep Learning Recommendation Model (DLRM) training pipeline. RecD addresses immense storage, preprocessing, and training overheads caused by feature duplication inherent in industry-scale DLRM training datasets. Feature duplication arises because DLRM datasets are generated from interactions. While each user session can generate multiple training samples, many features' values do not change across these samples. We demonstrate how RecD exploits this property, end-to-end, across a deployed training pipeline. RecD optimizes data generation pipelines to decrease dataset storage and preprocessing resource demands and to maximize duplication within a training batch. RecD introduces a new tensor format, InverseKeyedJaggedTensors (IKJTs), to deduplicate feature values in each batch. We show how DLRM model architectures can leverage IKJTs to drastically increase training throughput. RecD improves the training and preprocessing throughput and storage efficiency by up to 2.48x, 1.79x, and 3.71x, respectively, in an industry-scale DLRM training system.
翻译:我们提出了RecD(推荐去重复),这是一套端到端的基础架构优化,适用于深度学习推荐模型(DLRM)的各个训练阶段。RecD解决了由于特征重复存在于行业规模的DLRM训练数据集中,导致的存储,预处理和训练成本巨大的问题。由于DLRM数据集是从用户交互中生成的,因此会出现特征重复。尽管每个用户会生成多个训练样本,但这些样本中许多特征的值不会发生变化。我们演示了RecD如何利用这个属性,端到端地在部署的训练管线中运用到它。RecD通过优化数据生成管道来减少数据集的存储和预处理资源需求,并最大化每个训练批次中的重复数据。RecD引入了一种新的张量格式,称为InverseKeyedJaggedTensors (IKJTs),以在每个批次中去重复特征值。我们展示了DLRM模型架构如何利用IKJTs来大幅提高训练吞吐量。在行业规模的DLRM训练系统中,RecD提高了训练和预处理吞吐量和存储效率,分别达到2.48倍,1.79倍和3.71倍。