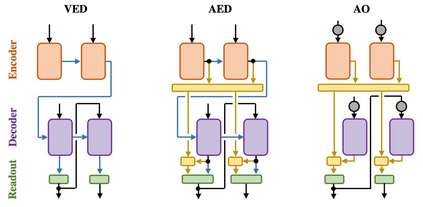
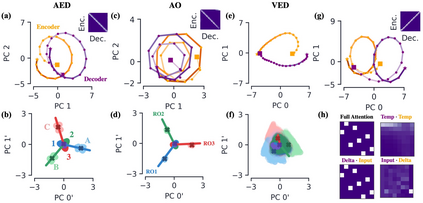
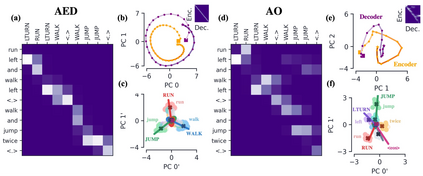
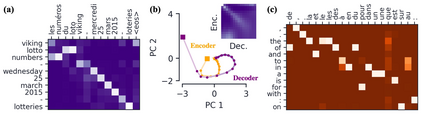
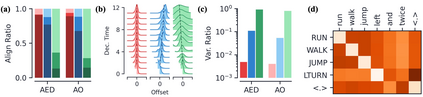
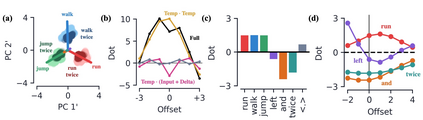
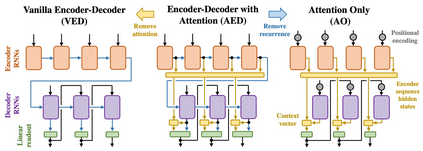
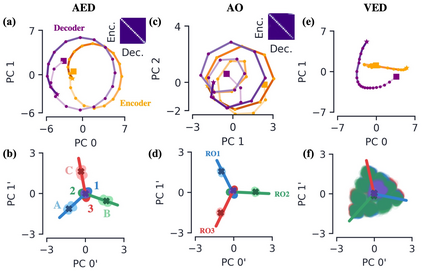
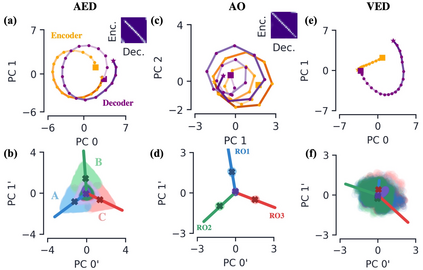
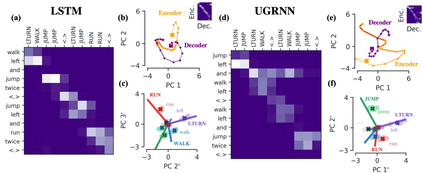
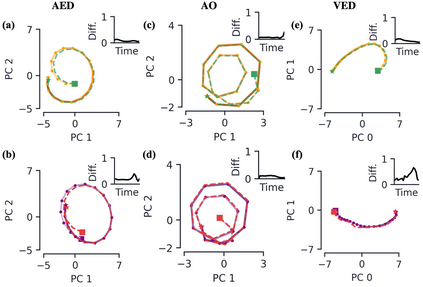
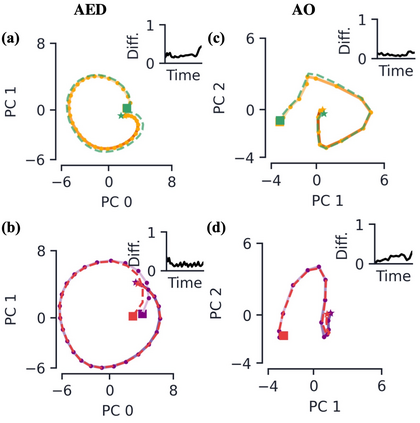
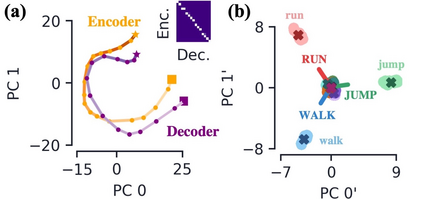
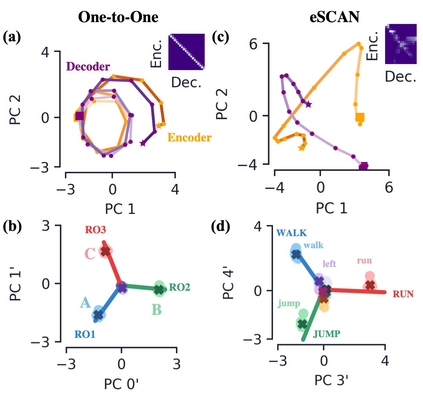
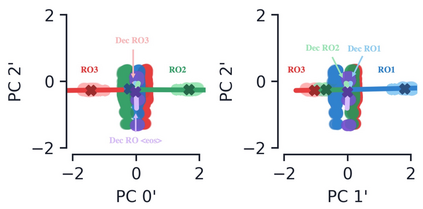
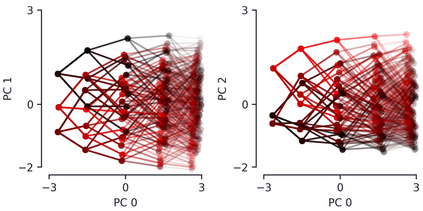
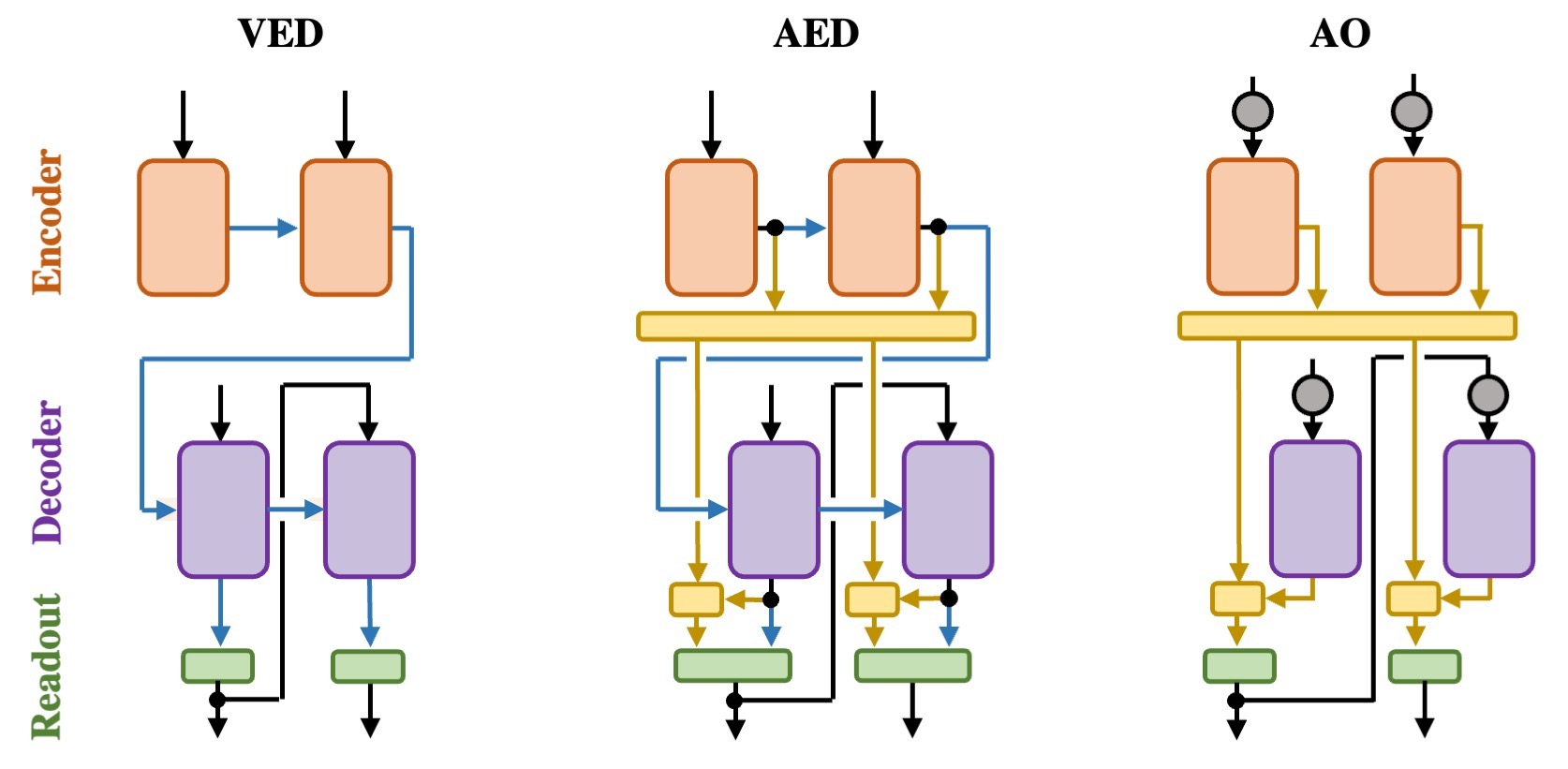
Encoder-decoder networks with attention have proven to be a powerful way to solve many sequence-to-sequence tasks. In these networks, attention aligns encoder and decoder states and is often used for visualizing network behavior. However, the mechanisms used by networks to generate appropriate attention matrices are still mysterious. Moreover, how these mechanisms vary depending on the particular architecture used for the encoder and decoder (recurrent, feed-forward, etc.) are also not well understood. In this work, we investigate how encoder-decoder networks solve different sequence-to-sequence tasks. We introduce a way of decomposing hidden states over a sequence into temporal (independent of input) and input-driven (independent of sequence position) components. This reveals how attention matrices are formed: depending on the task requirements, networks rely more heavily on either the temporal or input-driven components. These findings hold across both recurrent and feed-forward architectures despite their differences in forming the temporal components. Overall, our results provide new insight into the inner workings of attention-based encoder-decoder networks.
翻译:关注的编码器- 解码器网络已被证明是解决许多序列到序列任务的有力方法。 在这些网络中, 注意将编码器和解码器状态相匹配, 并经常用于网络行为的视觉化。 但是, 网络用来生成适当关注矩阵的机制仍然神秘。 此外, 这些机制如何因编码器和解码器( 经常的、 向前的、 向前的等) 所使用的特定结构而不同, 也没有得到很好的理解。 在这项工作中, 我们调查了编码器- 解码器网络如何解决不同序列到序列的任务。 我们引入了一种将隐藏状态分解的方式, 将一个序列分解成时间序列( 取决于输入) 和 输入驱动的( 取决于序列位置) 。 这揭示了注意矩阵是如何形成的: 取决于任务要求, 网络更加依赖时间或输入驱动的部件。 这些发现存在于经常和向前的架构中, 尽管它们在形成时间组成部分方面存在差异。 总之, 我们的结果为基于注意的编码解码器网络的内部工作提供了新的洞察。