
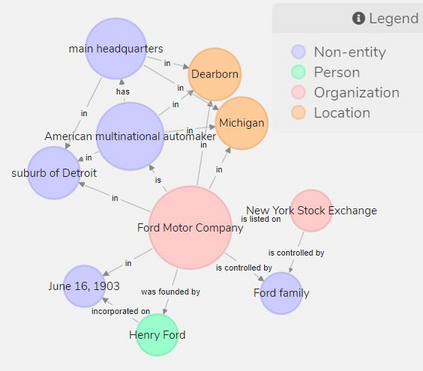
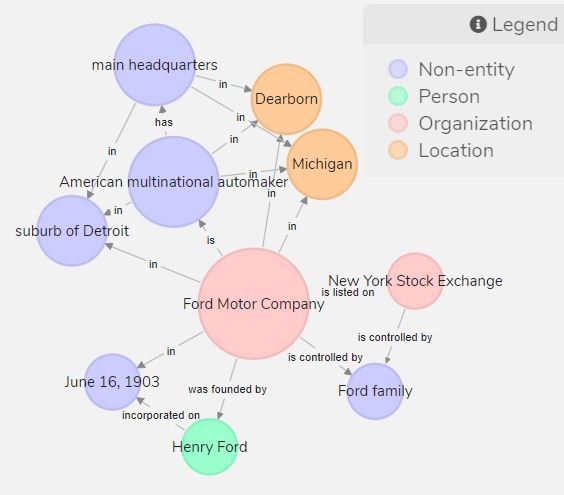
We present an overview of our triple extraction system for the ICDM 2019 Knowledge Graph Contest. Our system uses a pipeline-based approach to extract a set of triples from a given document. It offers a simple and effective solution to the challenge of knowledge graph construction from domain-specific text. It also provides the facility to visualise useful information about each triple such as the degree, betweenness, structured relation type(s), and named entity types.
翻译:我们为2019年国际清洁发展机制知识图表竞赛概述了我们的三重提取系统。我们的系统使用基于管道的方法从给定文件中提取一组三重内容。它为从特定领域文本中构建知识图表的挑战提供了简单而有效的解决方案。它也为视觉化关于每三重内容的有用信息提供了便利,如程度、介质、结构关系类型和名称实体类型。
相关内容

IEEE国际数据挖掘会议(ICDM)是世界上首屈一指的数据挖掘研究会议。它提供了一个国际论坛,介绍原始的研究成果,以及交流和传播创新和实际的发展经验。会议涵盖了数据挖掘的所有方面,包括算法、软件、系统和应用程序。ICDM吸引了来自统计、机器学习、模式识别、数据库、数据仓库、数据可视化、基于知识的系统和高性能计算等数据挖掘相关领域的研究人员、应用程序开发人员和实践者。会议通过促进新颖、高质量的研究成果和解决具有挑战性的数据挖掘问题的创新方案,力求推动数据挖掘领域的最新发展。
官网地址:http://dblp.uni-trier.de/db/conf/icdm/
专知会员服务
59+阅读 · 2020年6月30日
专知会员服务
26+阅读 · 2020年5月6日
Arxiv
23+阅读 · 2019年11月5日
Arxiv
3+阅读 · 2019年1月31日


相关VIP内容
专知会员服务
59+阅读 · 2020年6月30日
专知会员服务
26+阅读 · 2020年5月6日
相关资讯
相关论文
Arxiv
23+阅读 · 2019年11月5日
Arxiv
3+阅读 · 2019年1月31日