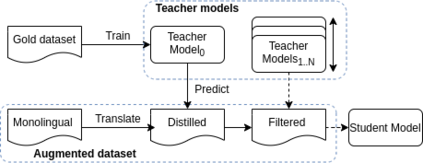
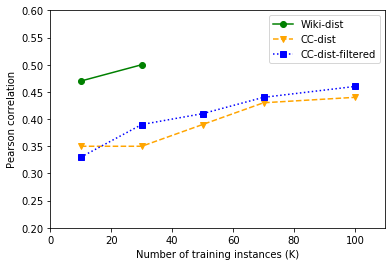
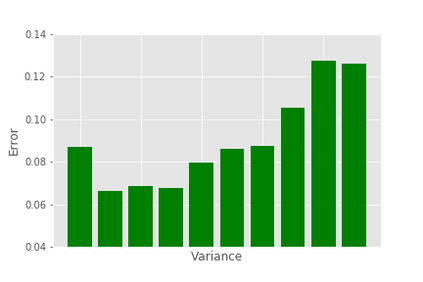
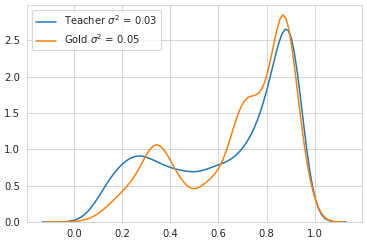
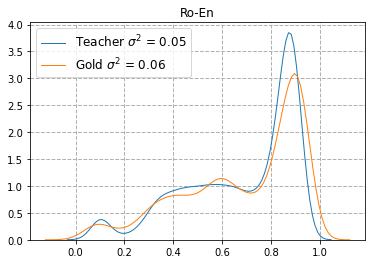
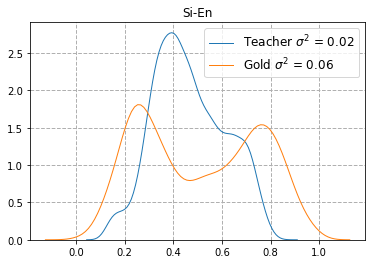
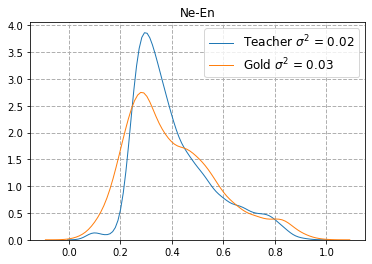
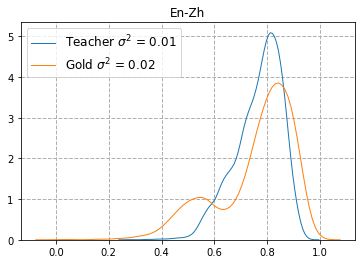
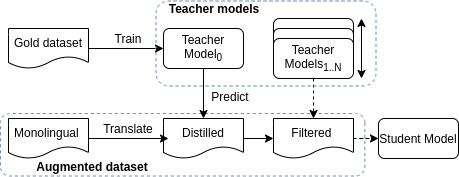
Quality Estimation (QE) is the task of automatically predicting Machine Translation quality in the absence of reference translations, making it applicable in real-time settings, such as translating online social media conversations. Recent success in QE stems from the use of multilingual pre-trained representations, where very large models lead to impressive results. However, the inference time, disk and memory requirements of such models do not allow for wide usage in the real world. Models trained on distilled pre-trained representations remain prohibitively large for many usage scenarios. We instead propose to directly transfer knowledge from a strong QE teacher model to a much smaller model with a different, shallower architecture. We show that this approach, in combination with data augmentation, leads to light-weight QE models that perform competitively with distilled pre-trained representations with 8x fewer parameters.
翻译:质量估计(QE)的任务是在没有参考翻译的情况下自动预测机器翻译质量,使之适用于实时环境,例如在线社交媒体对话翻译。QE最近的成功源于使用多语言的预培训演示,其中非常庞大的模型导致令人印象深刻的结果。然而,这些模型的推论时间、磁盘和记忆要求不允许在现实世界中广泛使用。对于许多使用情景而言,经过精炼的预培训演示模式培训的模型仍然过于庞大。我们提议直接将知识从一个强大的QE教师模型转移到一个规模小得多、结构不同、更浅的模型。我们表明,这一方法与数据扩增相结合,导致轻量的量化模型与经过精炼的预培训演示具有竞争力,其参数少8x。