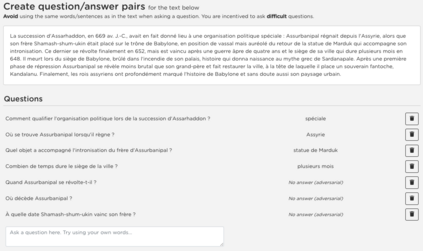
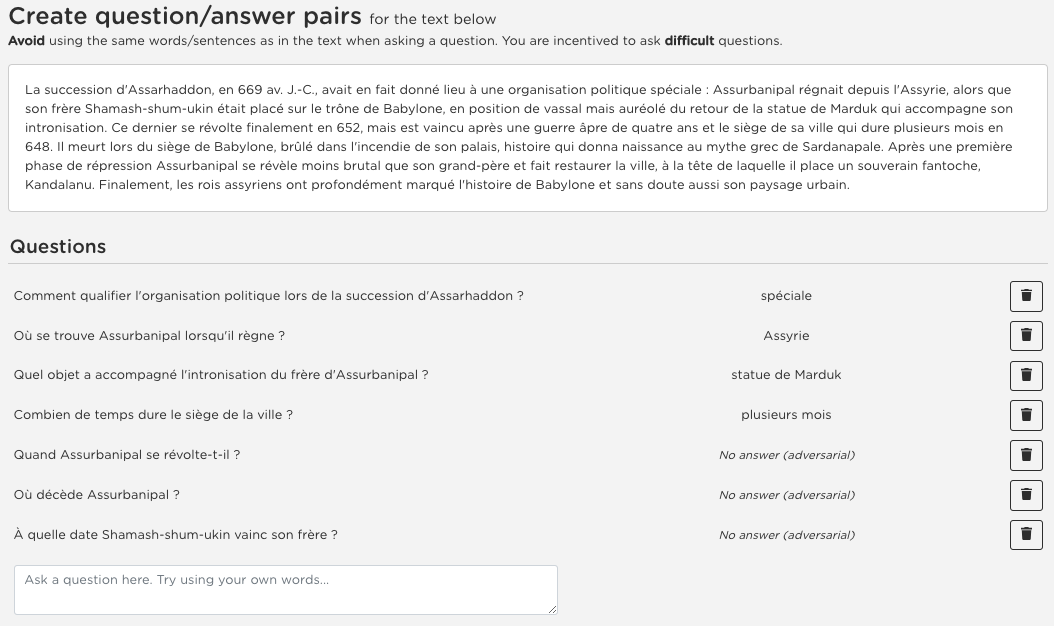
Question Answering, including Reading Comprehension, is one of the NLP research areas that has seen significant scientific breakthroughs over the past few years, thanks to the concomitant advances in Language Modeling. Most of these breakthroughs, however, are centered on the English language. In 2020, as a first strong initiative to bridge the gap to the French language, Illuin Technology introduced FQuAD1.1, a French Native Reading Comprehension dataset composed of 60,000+ questions and answers samples extracted from Wikipedia articles. Nonetheless, Question Answering models trained on this dataset have a major drawback: they are not able to predict when a given question has no answer in the paragraph of interest, therefore making unreliable predictions in various industrial use-cases. In the present work, we introduce FQuAD2.0, which extends FQuAD with 17,000+ unanswerable questions, annotated adversarially, in order to be similar to answerable ones. This new dataset, comprising a total of almost 80,000 questions, makes it possible to train French Question Answering models with the ability of distinguishing unanswerable questions from answerable ones. We benchmark several models with this dataset: our best model, a fine-tuned CamemBERT-large, achieves a F1 score of 82.3% on this classification task, and a F1 score of 83% on the Reading Comprehension task.
翻译:问题解答,包括阅读理解,是国家语言计划研究领域之一,在过去几年里,由于语言建模方面的同时进步,在科学方面取得了重大科学突破。但是,这些突破大多以英语为中心。2020年,作为缩小法语差距的第一个有力举措,Illuin Technology引入了法国本地阅读理解数据集FQAD1.1, 其中包括60,000+问答样本,从维基百科文章中提取的答案样本。然而,在这个数据集上培训的回答问题模型有一个重大缺陷:当某个问题在兴趣段落中找不到答案时,它们无法预测,因此在各种工业使用案例中作出不可靠的预测。在目前的工作中,我们引入FQuuaD2.0, 将FQuAD扩展为17,000+无法回答的问题,并附加了对抗性说明,以便与可回答的问题相似。这个由总共近80,000个问题组成的新数据集,使得有可能对法国回答问题模型进行培训,从而能够区分82-B类最佳的解答率,3级的预测。我们在目前的工作中,我们用一个无法解的排名的排名中,一个比为83的排名。