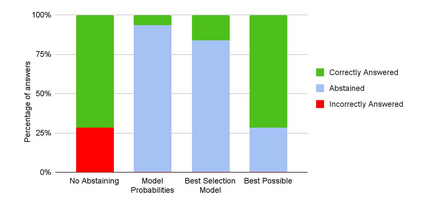
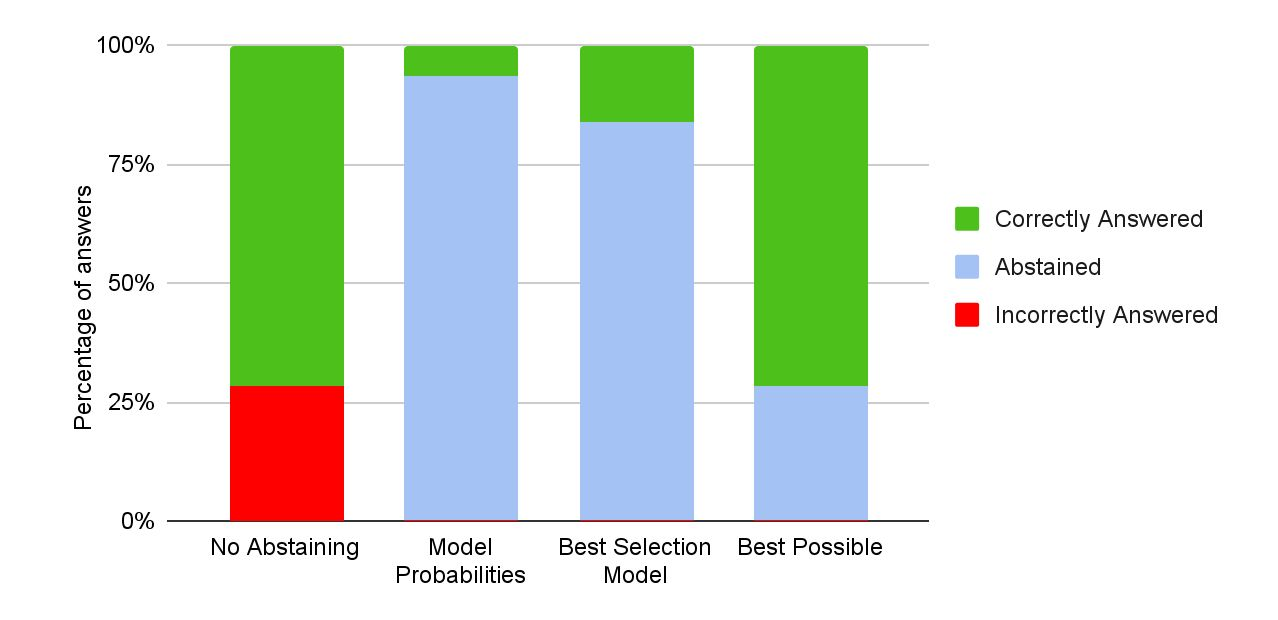
Machine learning has advanced dramatically, narrowing the accuracy gap to humans in multimodal tasks like visual question answering (VQA). However, while humans can say "I don't know" when they are uncertain (i.e., abstain from answering a question), such ability has been largely neglected in multimodal research, despite the importance of this problem to the usage of VQA in real settings. In this work, we promote a problem formulation for reliable VQA, where we prefer abstention over providing an incorrect answer. We first enable abstention capabilities for several VQA models, and analyze both their coverage, the portion of questions answered, and risk, the error on that portion. For that, we explore several abstention approaches. We find that although the best performing models achieve over 70% accuracy on the VQA v2 dataset, introducing the option to abstain by directly using a model's softmax scores limits them to answering less than 7.5% of the questions to achieve a low risk of error (i.e., 1%). This motivates us to utilize a multimodal selection function to directly estimate the correctness of the predicted answers, which we show can increase the coverage by, for example, 2.3x from 6.8% to 15.6% at 1% risk. While it is important to analyze both coverage and risk, these metrics have a trade-off which makes comparing VQA models challenging. To address this, we also propose an Effective Reliability metric for VQA that places a larger cost on incorrect answers compared to abstentions. This new problem formulation, metric, and analysis for VQA provide the groundwork for building effective and reliable VQA models that have the self-awareness to abstain if and only if they don't know the answer.
翻译:机器学习进展显著,缩小了在视觉问答(VQA)等多式联运任务中对人类的准确性差距。然而,虽然人类在不确定时可以说“我不知道”(即不回答一个问题),但这种能力在多式联运研究中在很大程度上被忽略,尽管这个问题对在真实环境中使用VQA很重要。在这项工作中,我们提倡为可靠的VQA制定问题配方,我们宁愿不提供错误的答案。我们首先为若干VQA 模型提供弃权能力,并分析其覆盖范围、回答的问题部分和风险,以及这一部分的错误。为此,我们探索了若干弃权方法。我们发现,尽管最优秀的模型在VQA v2数据集上实现了70%的准确性,但引入了直接使用模型软体积分数的选项,限制他们回答不到7.5 % 的VQA问题,从而降低错误的风险(即1 % ) 。这促使我们利用一个可靠的多式联运选择功能来直接估计预测的答案的正确性, 回答问题部分和风险部分,我们从6.A 度的角度来比较QQ的准确性定义的准确性范围,我们提出一个有效的自我分析范围, 。 比较一个有效的VA 标准是1比 1.3 标准的风险, 分析一个重要性分析一个风险。比 1.3 比较一个风险。比一个标准比一个风险。