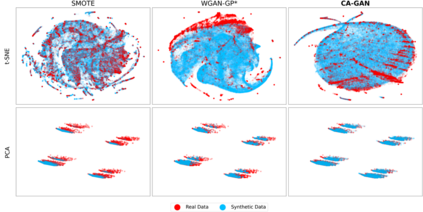
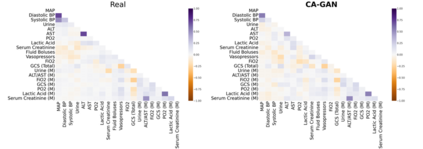
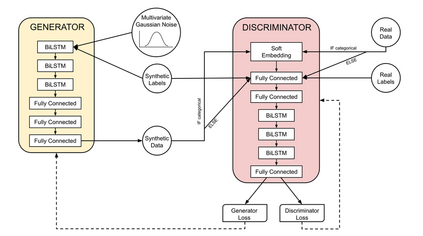
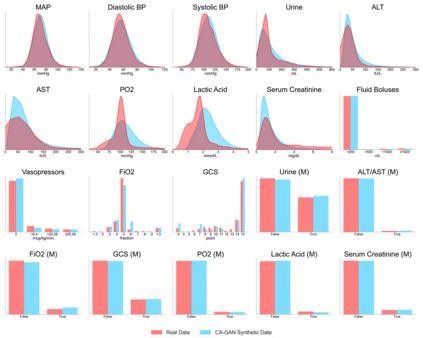
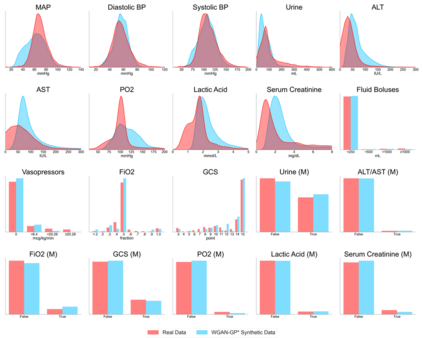
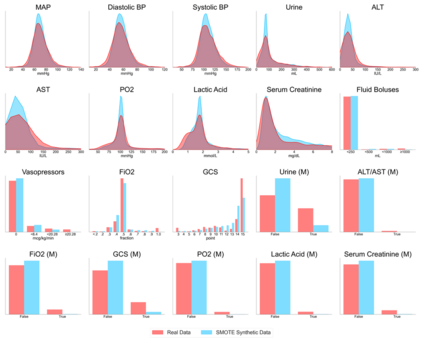
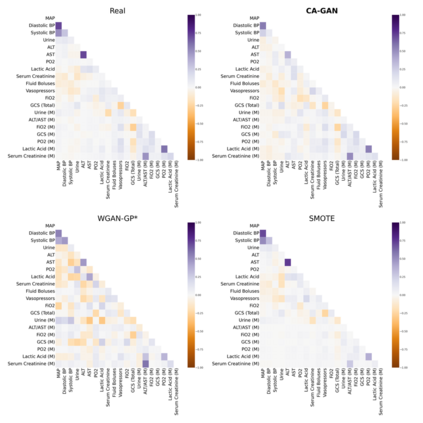
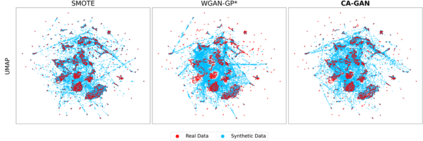
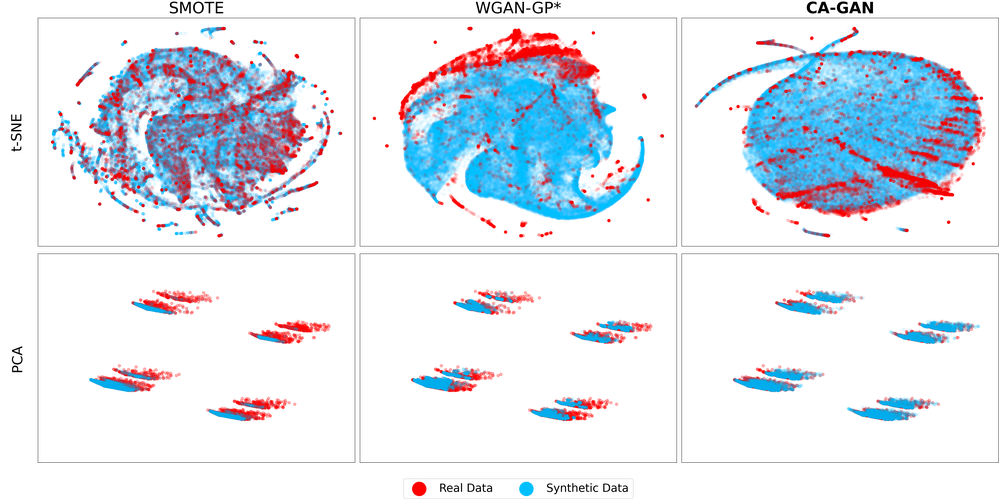
Several approaches have been developed to mitigate algorithmic bias stemming from health data poverty, where minority groups are underrepresented in training datasets. Augmenting the minority class using resampling (such as SMOTE) is a widely used approach due to the simplicity of the algorithms. However, these algorithms decrease data variability and may introduce correlations between samples, giving rise to the use of generative approaches based on GAN. Generation of high-dimensional, time-series, authentic data that provides a wide distribution coverage of the real data, remains a challenging task for both resampling and GAN-based approaches. In this work we propose CA-GAN architecture that addresses some of the shortcomings of the current approaches, where we provide a detailed comparison with both SMOTE and WGAN-GP*, using a high-dimensional, time-series, real dataset of 3343 hypotensive Caucasian and Black patients. We show that our approach is better at both generating authentic data of the minority class and remaining within the original distribution of the real data.
翻译:为了减少来自健康数据贫困的算法偏差,在培训数据集中少数群体代表性不足的地方,制定了几种方法来减少来自健康数据贫困的算法偏差。由于算法的简单性,利用重新抽样(如SMOTE)扩大少数群体类是一个广泛使用的方法。然而,这些算法降低了数据可变性,并可能引入样本之间的相互关系,从而导致使用基于GAN的基因化方法。 生成高维、时间序列和真实数据,提供真实数据的广泛分布,对于重新采样和基于GAN的方法来说,这仍然是一项艰巨的任务。在这个工作中,我们提出了CA-GAN结构,以解决当前方法的一些缺点,我们提供了与SMOTE和WGAN-GP* 的详细比较,使用了高维度、时间序列和真实的3343个低密度高加索人和黑人病人的数据集。我们表明,我们的方法在生成少数群体类真实数据以及保留在原始数据分布范围内方面都比较好。