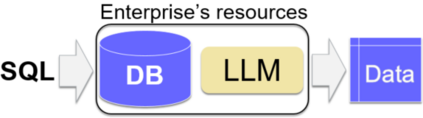
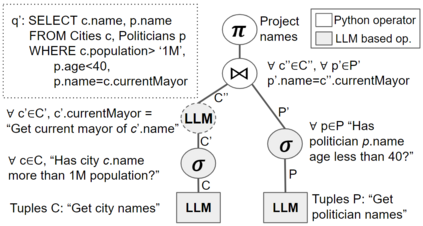
In many use-cases, information is stored in text but not available in structured data. However, extracting data from natural language text to precisely fit a schema, and thus enable querying, is a challenging task. With the rise of pre-trained Large Language Models (LLMs), there is now an effective solution to store and use information extracted from massive corpora of text documents. Thus, we envision the use of SQL queries to cover a broad range of data that is not captured by traditional databases by tapping the information in LLMs. To ground this vision, we present Galois, a prototype based on a traditional database architecture, but with new physical operators for querying the underlying LLM. The main idea is to execute some operators of the the query plan with prompts that retrieve data from the LLM. For a large class of SQL queries, querying LLMs returns well structured relations, with encouraging qualitative results. Preliminary experimental results make pre-trained LLMs a promising addition to the field of database systems, introducing a new direction for hybrid query processing. However, we pinpoint several research challenges that must be addressed to build a DBMS that exploits LLMs. While some of these challenges necessitate integrating concepts from the NLP literature, others offer novel research avenues for the DB community.
翻译:暂无翻译