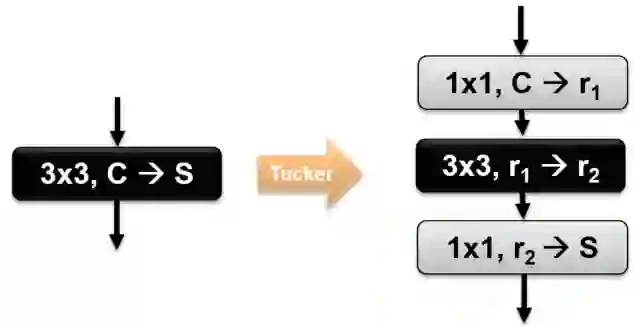
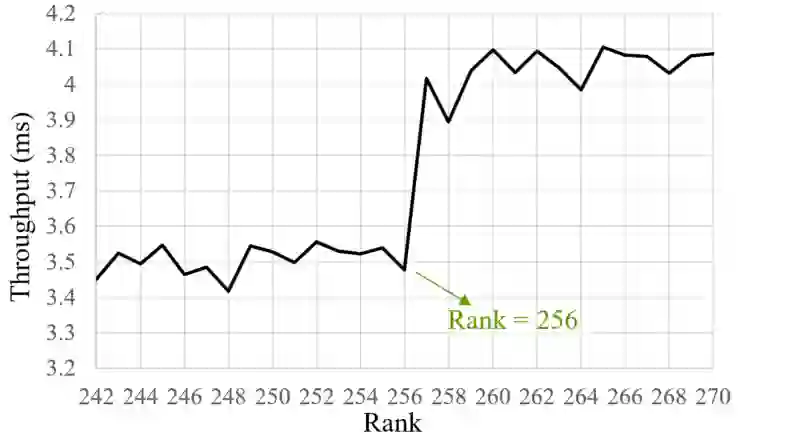
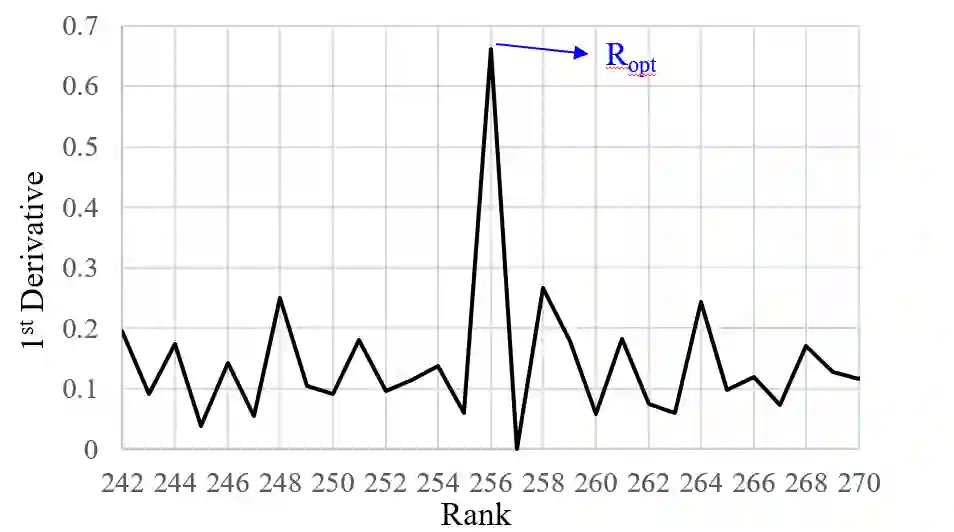
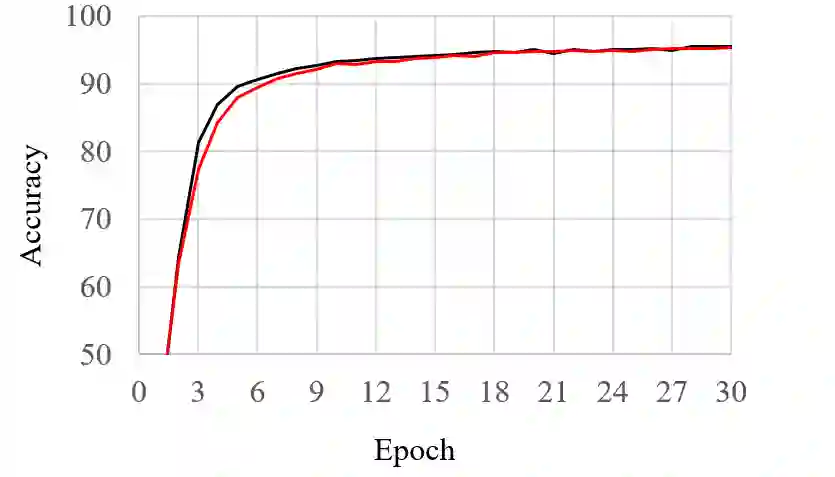
Low Rank Decomposition (LRD) is a model compression technique applied to the weight tensors of deep learning models in order to reduce the number of trainable parameters and computational complexity. However, due to high number of new layers added to the architecture after applying LRD, it may not lead to a high training/inference acceleration if the decomposition ranks are not small enough. The issue is that using small ranks increases the risk of significant accuracy drop after decomposition. In this paper, we propose two techniques for accelerating low rank decomposed models without requiring to use small ranks for decomposition. These methods include rank optimization and sequential freezing of decomposed layers. We perform experiments on both convolutional and transformer-based models. Experiments show that these techniques can improve the model throughput up to 60% during training and 37% during inference when combined together while preserving the accuracy close to that of the original models
翻译:暂无翻译