
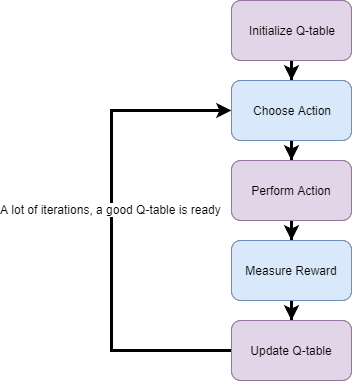
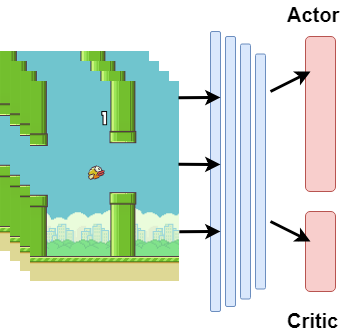
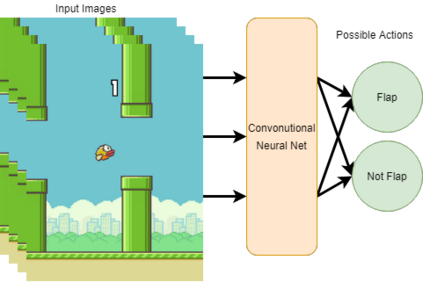
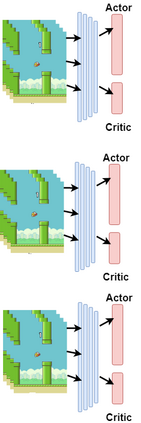
Flappy Bird, which has a very high popularity, has been trained in many algorithms. Some of these studies were trained from raw pixel values of game and some from specific attributes. In this study, the model was trained with raw game images, which had not been seen before. The trained model has learned as reinforcement when to make which decision. As an input to the model, the reward or penalty at the end of each step was returned and the training was completed. Flappy Bird game was trained with the Reinforcement Learning algorithm Deep Q-Network and Asynchronous Advantage Actor Critic (A3C) algorithms.
翻译:受欢迎程度很高的飞禽飞禽飞禽飞禽飞禽飞禽飞禽飞禽飞禽行动,它受到许多算法的培训,其中一些研究是从游戏的原始像素值和某些特定属性来训练的。在这项研究中,模型是用以前从未见过的原始游戏图像来训练的。经过训练的模型在作出何种决定时学到了加强作用。作为模型的一项投入,每一步结束时的奖赏或惩罚被退回,培训也已完成。 飞禽飞鸟飞鸟的比赛经过“加强学习算法深QNetwork”和“Asynchronous Advantage Acritic (A3C)”算法的培训。


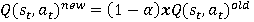
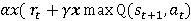
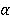
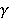

相关内容

2014年2月,《Flappy Bird》被开发者本人从苹果及谷歌应用商店撤下。2014年8月份正式回归APP STORE,正式加入Flappy迷们期待已久的多人对战模式。游戏中玩家必须控制一只小鸟,跨越由各种不同长度水管所组成的障碍。


