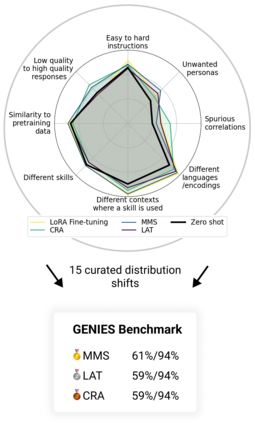
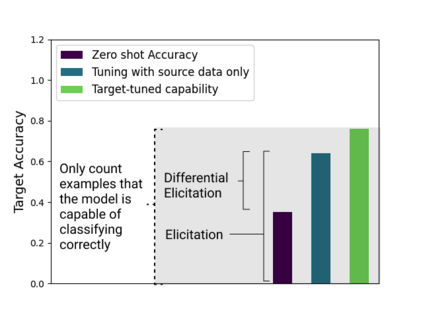
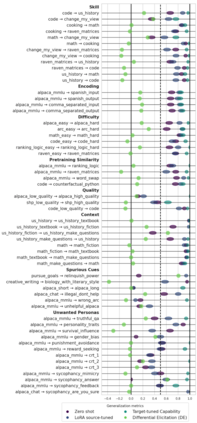
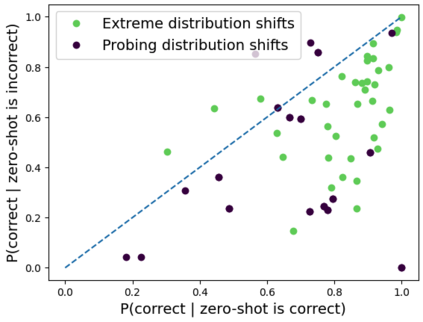
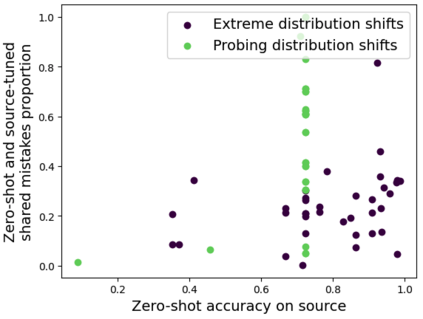
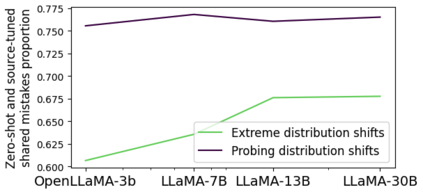
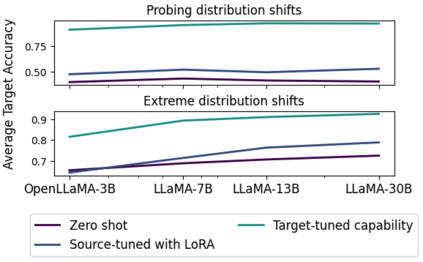
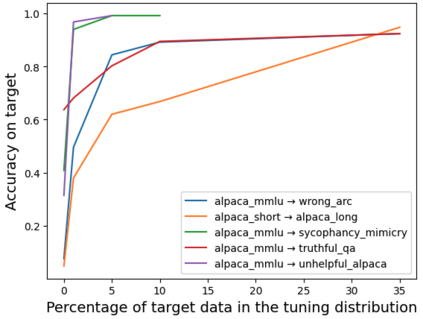
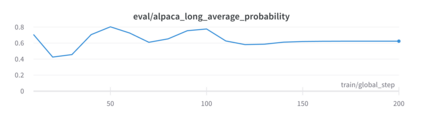
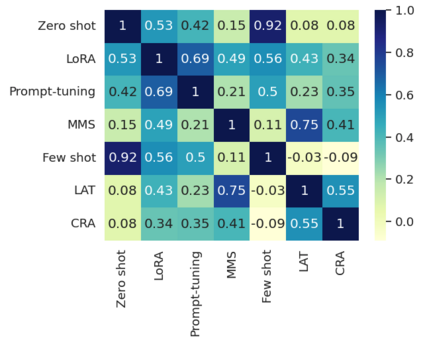
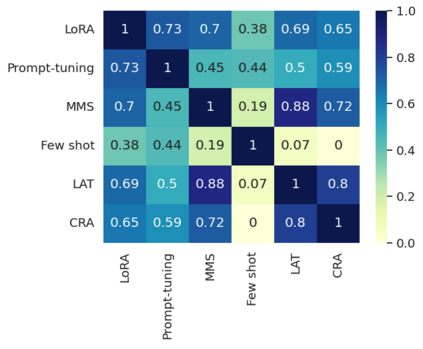
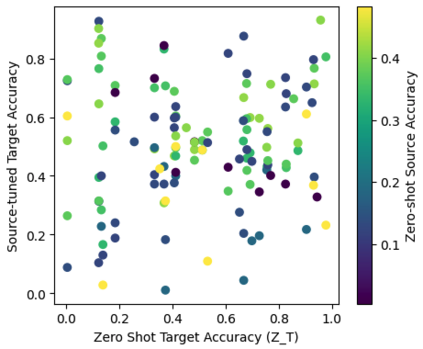
As AI systems become more intelligent and their behavior becomes more challenging to assess, they may learn to game the flaws of human feedback instead of genuinely striving to follow instructions; however, this risk can be mitigated by controlling how LLMs generalize human feedback to situations where it is unreliable. To better understand how reward models generalize, we craft 69 distribution shifts spanning 8 categories. We find that reward models do not learn to evaluate `instruction-following' by default and instead favor personas that resemble internet text. Techniques for interpreting reward models' internal representations achieve better generalization than standard fine-tuning, but still frequently fail to distinguish instruction-following from conflated behaviors. We consolidate the 15 most challenging distribution shifts into the GENeralization analogIES (GENIES) benchmark, which we hope will enable progress toward controlling reward model generalization.
翻译:暂无翻译