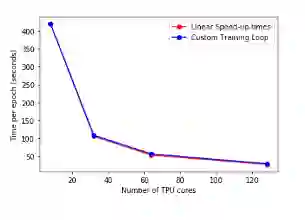
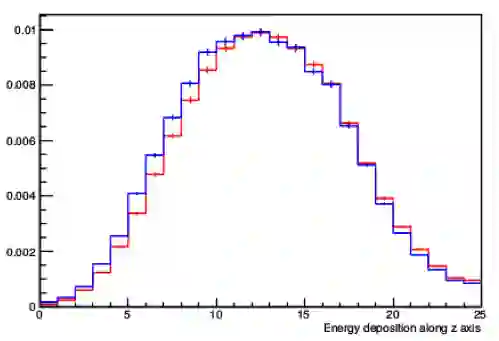
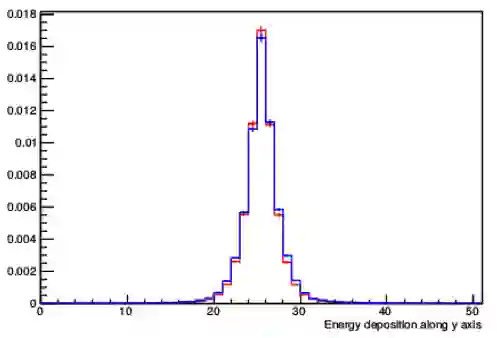
With the increasing number of Machine and Deep Learning applications in High Energy Physics, easy access to dedicated infrastructure represents a requirement for fast and efficient R&D. This work explores different types of cloud services to train a Generative Adversarial Network (GAN) in a parallel environment, using Tensorflow data parallel strategy. More specifically, we parallelize the training process on multiple GPUs and Google Tensor Processing Units (TPU) and we compare two algorithms: the TensorFlow built-in logic and a custom loop, optimised to have higher control of the elements assigned to each GPU worker or TPU core. The quality of the generated data is compared to Monte Carlo simulation. Linear speed-up of the training process is obtained, while retaining most of the performance in terms of physics results. Additionally, we benchmark the aforementioned approaches, at scale, over multiple GPU nodes, deploying the training process on different public cloud providers, seeking for overall efficiency and cost-effectiveness. The combination of data science, cloud deployment options and associated economics allows to burst out heterogeneously, exploring the full potential of cloud-based services.
翻译:随着高能物理中机器和深层学习应用数量的增加,对专门基础设施的方便访问是快速高效研发的一项要求。 这项工作探索了不同类型的云服务,利用Tensorflow数据平行战略,在一个平行的环境中培训创生反对流网络(GAN),更具体地说,我们将多个GPU和Google Tensor处理器(TPU)的培训过程平行进行,我们比较了两种算法:TensorFlow内在逻辑和定制循环,优化了对分配给每个GPU工人或TPU核心的元素的控制。生成的数据的质量与Monte Carlo模拟相比较。实现了培训过程的线性加速,同时保留了物理结果方面的大多数绩效。此外,我们从规模上将上述方法作为基准,超过多个GPU节点,将培训过程部署到不同的公共云提供商,以寻求总体效率和成本效益。数据科学、云部署选项和相关经济学的结合,使得数据科学、云库服务的全部潜力得以破碎。