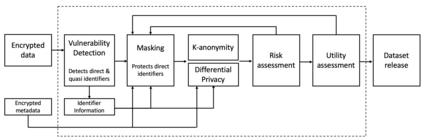
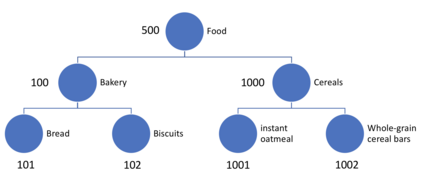
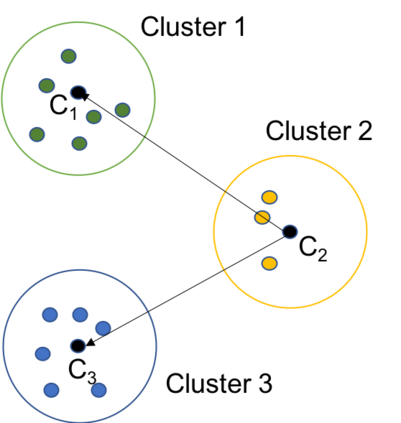
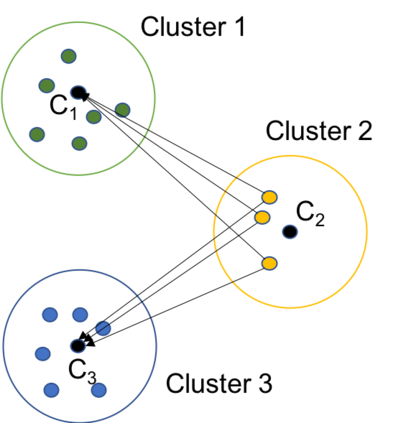
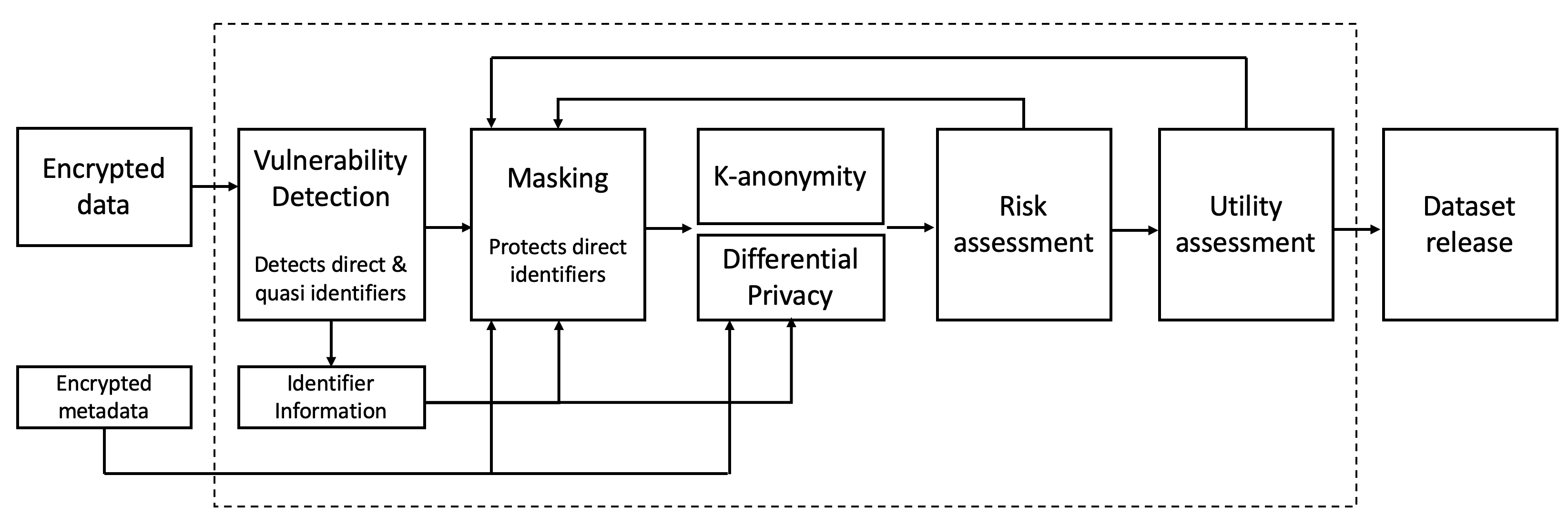
Data protection algorithms are becoming increasingly important to support modern business needs for facilitating data sharing and data monetization. Anonymization is an important step before data sharing. Several organizations leverage on third parties for storing and managing data. However, third parties are often not trusted to store plaintext personal and sensitive data; data encryption is widely adopted to protect against intentional and unintentional attempts to read personal/sensitive data. Traditional encryption schemes do not support operations over the ciphertexts and thus anonymizing encrypted datasets is not feasible with current approaches. This paper explores the feasibility and depth of implementing a privacy-preserving data publishing workflow over encrypted datasets leveraging on homomorphic encryption. We demonstrate how we can achieve uniqueness discovery, data masking, differential privacy and k-anonymity over encrypted data requiring zero knowledge about the original values. We prove that the security protocols followed by our approach provide strong guarantees against inference attacks. Finally, we experimentally demonstrate the performance of our data publishing workflow components.
翻译:数据保护算法对于支持现代商业需要促进数据共享和数据货币化越来越重要。匿名化是数据共享之前的一个重要步骤。若干组织利用第三方储存和管理数据。不过,第三方往往不信任储存普通个人和敏感数据;数据加密被广泛采用,以防止有意和无意地试图阅读个人/敏感数据。传统的加密办法不支持对密码的操作,因此用加密数据集匿名是不可行的。本文件探讨了对加密数据集采用保密数据发布工作流程的可行性和深度。我们展示了我们如何实现独特性发现、数据掩蔽、差异隐私和k-匿名,而加密数据则要求对原始价值没有了解。我们证明,我们采用的方法所遵循的安全协议提供了有力的保证,防止推断攻击。最后,我们实验性地展示了我们数据发布工作流程组成部分的性能。