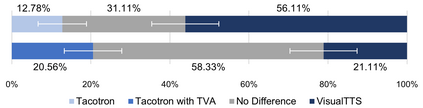
In this paper, we formulate a novel task to synthesize speech in sync with a silent pre-recorded video, denoted as automatic voice over (AVO). Unlike traditional speech synthesis, AVO seeks to generate not only human-sounding speech, but also perfect lip-speech synchronization. A natural solution to AVO is to condition the speech rendering on the temporal progression of lip sequence in the video. We propose a novel text-to-speech model that is conditioned on visual input, named VisualTTS, for accurate lip-speech synchronization. The proposed VisualTTS adopts two novel mechanisms that are 1) textual-visual attention, and 2) visual fusion strategy during acoustic decoding, which both contribute to forming accurate alignment between the input text content and lip motion in input lip sequence. Experimental results show that VisualTTS achieves accurate lip-speech synchronization and outperforms all baseline systems.
翻译:在本文中,我们设计了一项新颖的任务,即将语言与无声预录视频同步合成,称为自动语音(AVO ) 。与传统的语音合成不同,AVO寻求不仅产生人听的语音,而且产生完美的嘴语同步。AVO的自然解决方案是将讲话以视频中嘴语顺序的时序发展为条件。我们提出了一个以视觉输入为条件的新颖的文字对口语模式,名为“视觉TTTS ”, 以精确的嘴语同步为条件。拟议的视觉TTTS 采用了两种新颖机制,即:(1) 文字-视觉关注,和(2) 声学解码期间的视觉融合战略,两者都有助于在输入文字内容和输入唇序列的唇动之间形成准确的一致。实验结果表明,视觉TTTS 实现了准确的嘴语同步,超越了所有基线系统。