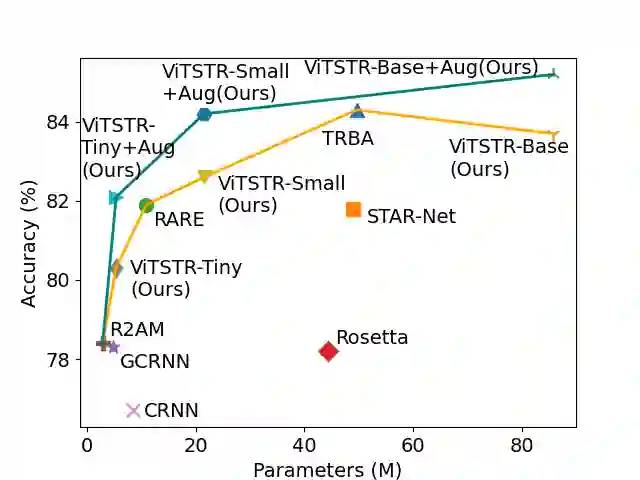
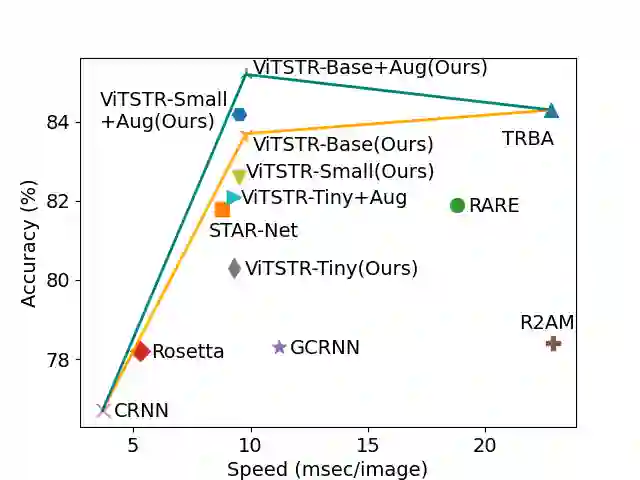
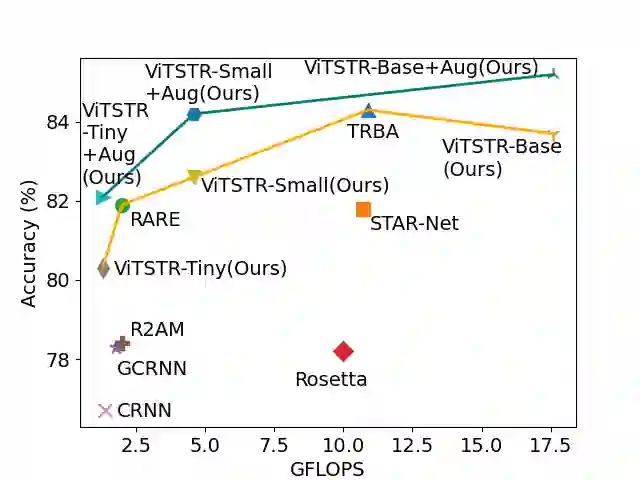
Scene text recognition (STR) enables computers to read text in natural scenes such as object labels, road signs and instructions. STR helps machines perform informed decisions such as what object to pick, which direction to go, and what is the next step of action. In the body of work on STR, the focus has always been on recognition accuracy. There is little emphasis placed on speed and computational efficiency which are equally important especially for energy-constrained mobile machines. In this paper we propose ViTSTR, an STR with a simple single stage model architecture built on a compute and parameter efficient vision transformer (ViT). On a comparable strong baseline method such as TRBA with accuracy of 84.3%, our small ViTSTR achieves a competitive accuracy of 82.6% (84.2% with data augmentation) at 2.4x speed up, using only 43.4% of the number of parameters and 42.2% FLOPS. The tiny version of ViTSTR achieves 80.3% accuracy (82.1% with data augmentation), at 2.5x the speed, requiring only 10.9% of the number of parameters and 11.9% FLOPS. With data augmentation, our base ViTSTR outperforms TRBA at 85.2% accuracy (83.7% without augmentation) at 2.3x the speed but requires 73.2% more parameters and 61.5% more FLOPS. In terms of trade-offs, nearly all ViTSTR configurations are at or near the frontiers to maximize accuracy, speed and computational efficiency all at the same time.
翻译:显示文本识别(STS) 使计算机能够在物体标签、路标和指示等自然场景中阅读文字。 STS 帮助机器执行知情决定, 如选择对象、 方向和下一步行动。 在STS 的正文中, 重点始终是确认准确性。 很少强调速度和计算效率, 这对于能源限制的移动机器来说尤其重要。 在本文中, 我们提议VITSTR, 是一个简单的单一阶段模型结构, 以一个计算和参数高效的视觉变异器( VT) 为基础, 简单的单一阶段。 在类似快速的基线方法( 如TRBA, 精确度为84.3% ), 我们的小VITSTR 实现了82.6%( 84.2%) 的竞争性准确性, 数据增加2.4x速度, 仅使用43.4%的参数和42.2%的FLOPS。 VITS 的所有小版本都达到80.3%的准确性( 82.1%), 速度为2.5x, 只需要10.9%的参数和11.9%的FLOPS。 。 在数据增强中, 的精确性为: 2.3 更精确性为25, 在数据增长中, 或更接近的TRSBRBRBRBRFS 的精确度为23 的精确度为23 。