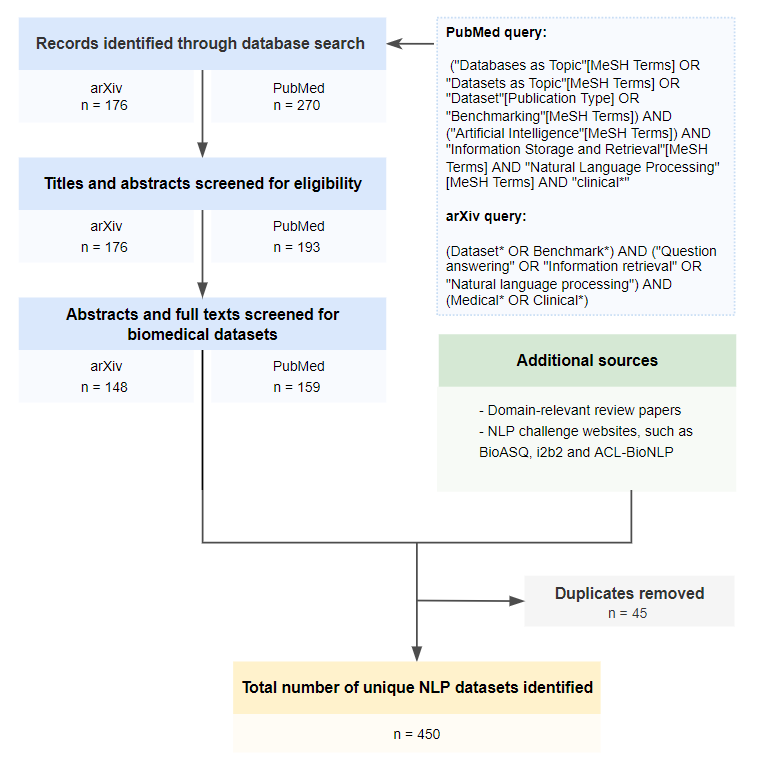
Publicly accessible benchmarks that allow for assessing and comparing model performances are important drivers of progress in artificial intelligence (AI). While recent advances in AI capabilities hold the potential to transform medical practice by assisting and augmenting the cognitive processes of healthcare professionals, the coverage of clinically relevant tasks by AI benchmarks is largely unclear. Furthermore, there is a lack of systematized meta-information that allows clinical AI researchers to quickly determine accessibility, scope, content and other characteristics of datasets and benchmark datasets relevant to the clinical domain. To address these issues, we curated and released a comprehensive catalogue of datasets and benchmarks pertaining to the broad domain of clinical and biomedical natural language processing (NLP), based on a systematic review of literature and online resources. A total of 450 NLP datasets were manually systematized and annotated with rich metadata, such as targeted tasks, clinical applicability, data types, performance metrics, accessibility and licensing information, and availability of data splits. We then compared tasks covered by AI benchmark datasets with relevant tasks that medical practitioners reported as highly desirable targets for automation in a previous empirical study. Our analysis indicates that AI benchmarks of direct clinical relevance are scarce and fail to cover most work activities that clinicians want to see addressed. In particular, tasks associated with routine documentation and patient data administration workflows are not represented despite significant associated workloads. Thus, currently available AI benchmarks are improperly aligned with desired targets for AI automation in clinical settings, and novel benchmarks should be created to fill these gaps.
翻译:可用于评估和比较模型业绩的可公开查阅的基准是人工智能(AI)取得进展的重要驱动因素。尽管AI能力最近的进展有可能通过协助和扩大保健专业人员的认知过程来改变医疗做法,但AI基准对临床相关任务的范围基本上不清楚。此外,缺乏系统化的元信息,使临床AI研究人员能够迅速确定数据集和基准数据集的可获取性、范围、内容和其他特点以及与临床领域相关的数据基数。为解决这些问题,我们整理并发布了一个全面的数据集和基准目录,其中涉及临床和生物医学自然语言处理的广泛领域,这是基于对文献和在线资源的系统审查。总共450个NLP数据集是手工系统化的,并附有丰富的元数据,如有针对性的任务、临床适用性、数据类型、性能衡量标准、可获取性和许可信息以及数据的提供。我们随后将AI基准数据集所涵盖的任务与医学从业人员报告为自动化的高度可取目标的相关任务进行了比较。我们的分析表明,在临床直接相关的临床基准和在线资源(NLP)的广泛领域,我们的分析表明,在临床相关基准中,尽管临床基准与临床相关基准目前缺乏并且无法涵盖大部分日常工作量,但与临床相关数据管理所需的基准,因此,我们需要看到与临床相关基准,这些基准必须符合与临床相关的工作需要符合。