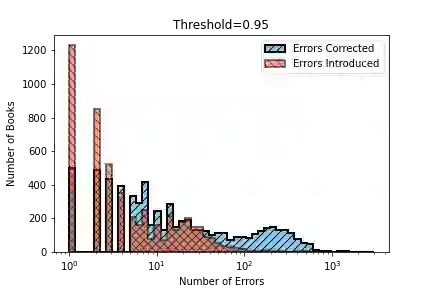
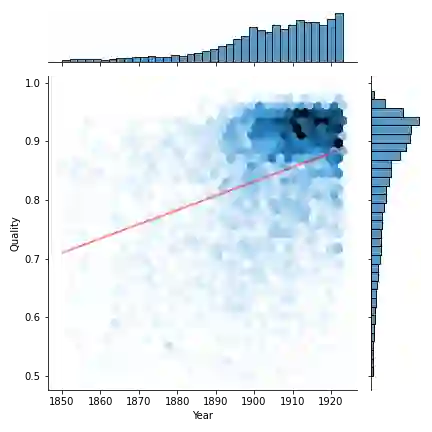
Substantial amounts of work are required to clean large collections of digitized books for NLP analysis, both because of the presence of errors in the scanned text and the presence of duplicate volumes in the corpora. In this paper, we consider the issue of deduplication in the presence of optical character recognition (OCR) errors. We present methods to handle these errors, evaluated on a collection of 19,347 texts from the Project Gutenberg dataset and 96,635 texts from the HathiTrust Library. We demonstrate that improvements in language models now enable the detection and correction of OCR errors without consideration of the scanning image itself. The inconsistencies found by aligning pairs of scans of the same underlying work provides training data to build models for detecting and correcting errors. We identify the canonical version for each of 17,136 repeatedly-scanned books from 58,808 scans. Finally, we investigate methods to detect and correct errors in single-copy texts. We show that on average, our method corrects over six times as many errors as it introduces. We also provide interesting analysis on the relation between scanning quality and other factors such as location and publication year.
翻译:需要大量的工作来清理大量数字化书籍的收集,以便进行NLP分析,这既是因为扫描文本中存在错误,又是因为Corpora有重复的卷本。在本文件中,我们考虑了光学字符识别错误中的重复问题。我们提出了处理这些错误的方法,对古滕贝格项目数据集的19 347个文本和HathiTrust图书馆的96 635个文本进行了评估。我们表明,语言模型的改进现在能够发现和纠正OCR错误,而不必考虑扫描图像本身。通过对同一基本工作的扫描对齐发现的不一致之处,为建立探测和纠正错误的模型提供了培训数据。我们确定了从58 808扫描中反复扫描的17 136本书的可理解版本。最后,我们调查了单本文本中发现和纠正错误的方法。我们显示,平均而言,我们的方法纠正了六倍多的错误。我们还就扫描质量与诸如地点和出版年份等其他因素之间的关系提供了有趣的分析。