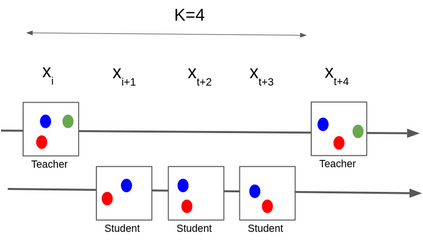
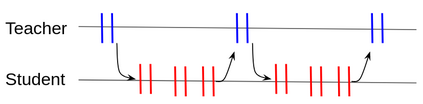
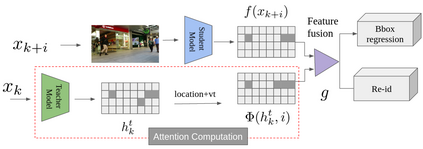
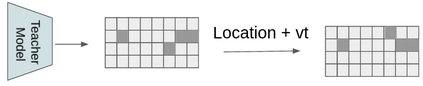
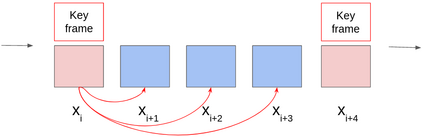
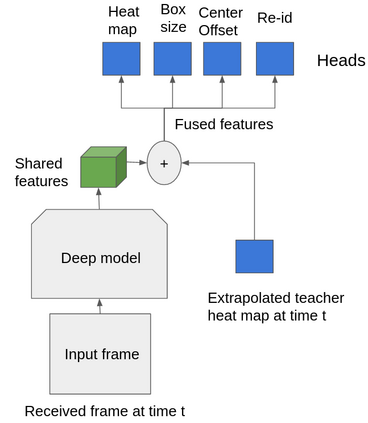
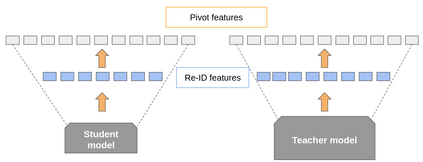
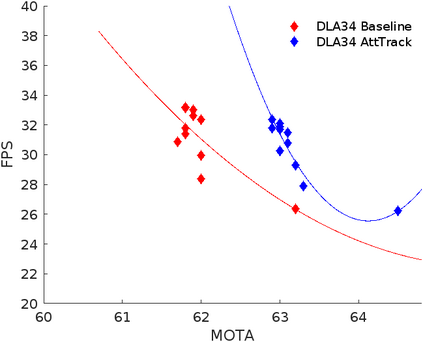
Multi-object tracking (MOT) is a vital component of intelligent video analytics applications such as surveillance and autonomous driving. The time and storage complexity required to execute deep learning models for visual object tracking hinder their adoption on embedded devices with limited computing power. In this paper, we aim to accelerate MOT by transferring the knowledge from high-level features of a complex network (teacher) to a lightweight network (student) at both training and inference times. The proposed AttTrack framework has three key components: 1) cross-model feature learning to align intermediate representations from the teacher and student models, 2) interleaving the execution of the two models at inference time, and 3) incorporating the updated predictions from the teacher model as prior knowledge to assist the student model. Experiments on pedestrian tracking tasks are conducted on the MOT17 and MOT15 datasets using two different object detection backbones YOLOv5 and DLA34 show that AttTrack can significantly improve student model tracking performance while sacrificing only minor degradation of tracking speed.
翻译:多目标跟踪(MOT)是监视和自主驾驶等智能视频分析应用的关键组成部分。执行视觉物体跟踪的深学习模型所需的时间和储存复杂性阻碍了在计算机功率有限的嵌入装置上采用这些模型。在本文件中,我们的目标是通过将复杂网络(教师)的高级特征知识转移到轻量级网络(学生)进行培训和推断的时间,加快多目标跟踪(MOT),拟议的AttTrack框架有三个关键组成部分:1)跨模范特征学习以协调教师和学生模型的中间表现;2)在推断时间执行两种模型时相互间隔,3)将教师模型的最新预测作为先前的知识纳入,以协助学生模型。行人跟踪任务实验在MOT17和MOT15数据集上进行,使用两个不同的物体探测主干线YOLOv5和DLA34显示,Attrack可以显著改进学生模型跟踪性能,同时只牺牲跟踪速度的轻微退化。