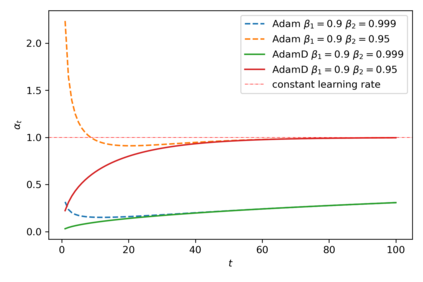
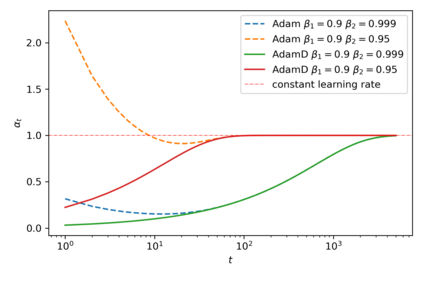
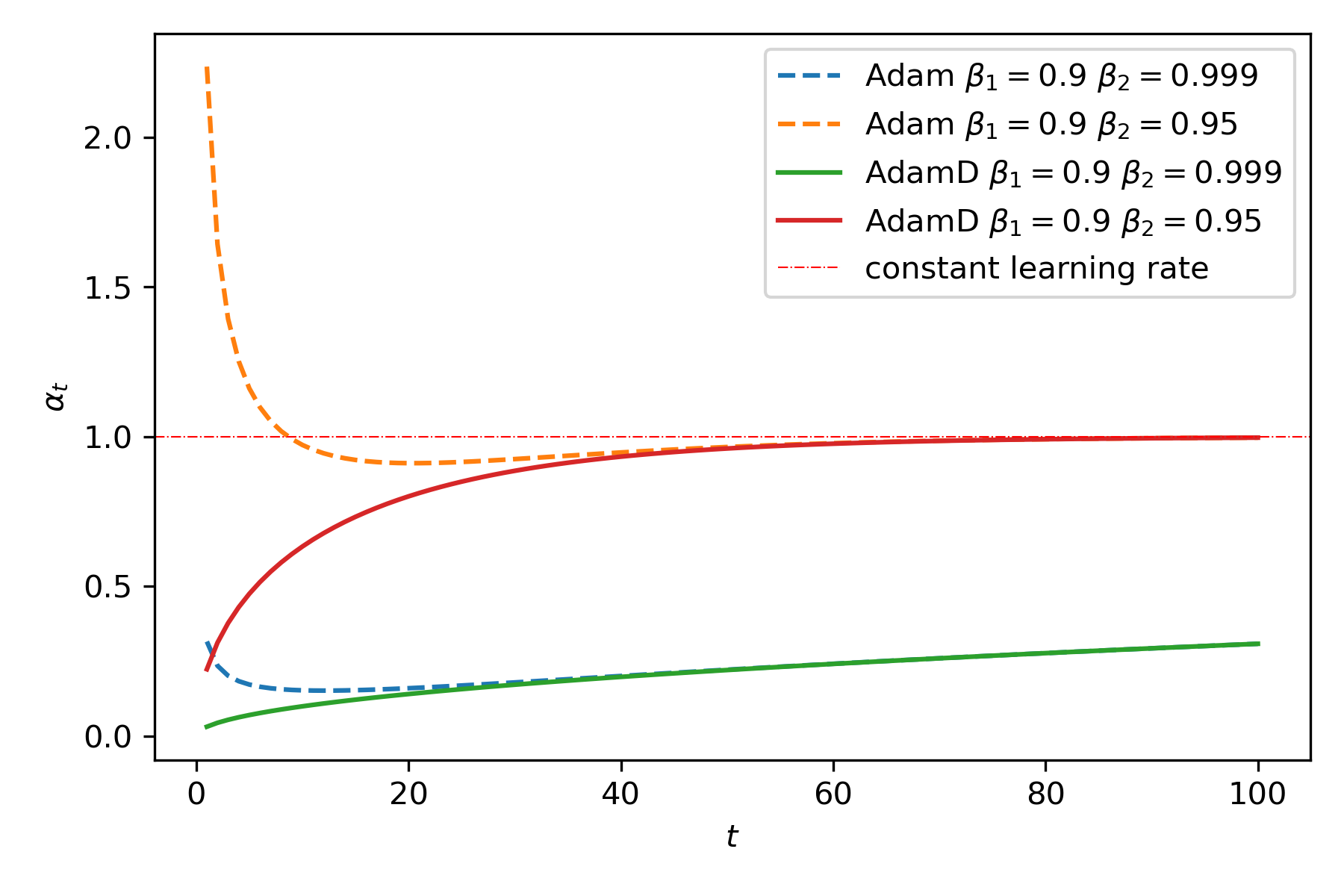
Here I present a small update to the bias-correction term in the Adam optimizer that has the advantage of making smaller gradient updates in the first several steps of training. With the default bias-correction, Adam may actually make larger than requested gradient updates early in training. By only including the well-justified bias-correction of the second moment gradient estimate, $v_t$, and excluding the bias-correction on the first-order estimate, $m_t$, we attain these more desirable gradient update properties in the first series of steps. The default implementation of Adam may be as sensitive as it is to the hyperparameters $\beta_1, \beta_2$ partially due to the originally proposed bias correction procedure, and its behavior in early steps.
翻译:这里我对亚当优化器中的偏差校正术语做了一个小的更新, 其优点是在培训的前几个步骤中进行较小的梯度更新。 在默认的偏差校正的情况下, 亚当实际上可以在培训初期比要求的梯度更新要大。 仅将第二个时刻的偏差校正( $v_ t$) 包括在内, 并排除第一级估算的偏差校正( $m_ t$ ), 我们就可以在第一个步骤系列中实现这些更可取的梯度更新属性。 亚当的默认实施可能像对超参数 $\beta_ 1,\beta_ 2 美元一样敏感, 部分原因是最初提出的偏差校正程序及其早期的行为 。