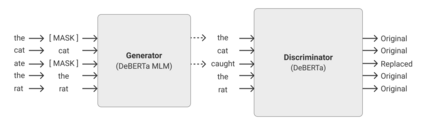
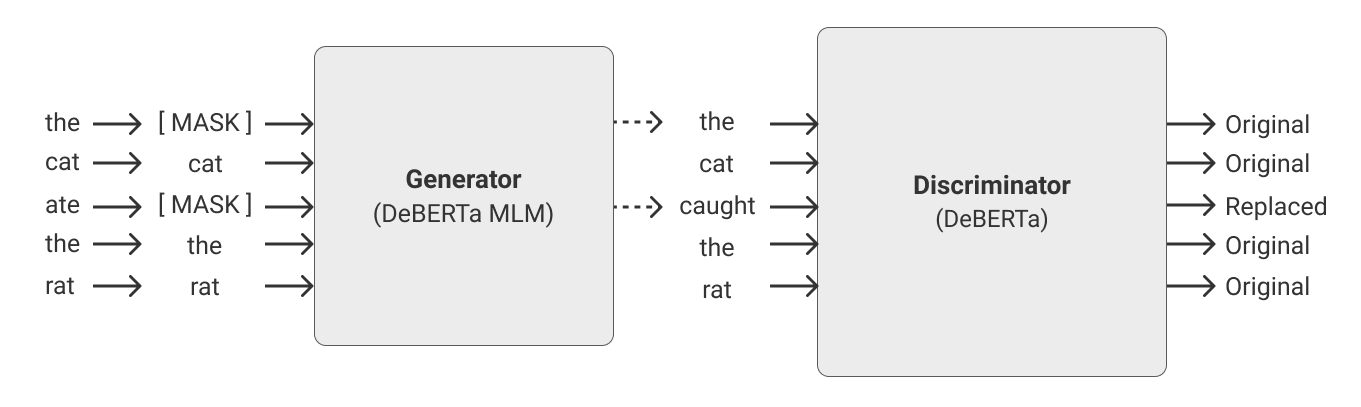
Recent progress in the Natural Language Processing domain has given us several State-of-the-Art (SOTA) pretrained models which can be finetuned for specific tasks. These large models with billions of parameters trained on numerous GPUs/TPUs over weeks are leading in the benchmark leaderboards. In this paper, we discuss the need for a benchmark for cost and time effective smaller models trained on a single GPU. This will enable researchers with resource constraints experiment with novel and innovative ideas on tokenization, pretraining tasks, architecture, fine tuning methods etc. We set up Small-Bench NLP, a benchmark for small efficient neural language models trained on a single GPU. Small-Bench NLP benchmark comprises of eight NLP tasks on the publicly available GLUE datasets and a leaderboard to track the progress of the community. Our ELECTRA-DeBERTa (15M parameters) small model architecture achieves an average score of 81.53 which is comparable to that of BERT-Base's 82.20 (110M parameters). Our models, code and leaderboard are available at https://github.com/smallbenchnlp
翻译:自然语言处理领域最近的进展使我们获得了几项经过培训的先进模型(SOTA),这些经过培训的先进模型可以对具体任务进行微调,这些具有数十亿个参数的大型模型在数周内就许多GPU/TPU进行了数十亿次培训,这些模型在基准首列中领先。在本文件中,我们讨论了是否需要为成本和时间方面有效的小型模型制定基准,在单一的GPU上进行了培训。这将使资源有限的研究人员能够就象征性化、培训前任务、建筑、微调方法等方面进行新的创新想法的实验。我们建立了小型BERT-Base82.20(M110参数),这是在单一的GPUPU上培训的小型高效神经语言模型的基准。小型-NLPNLP基准由8项NLP任务组成,在公众可得到的GLUE数据集和跟踪社区进展的首页组成。我们的ELTRA-DEBERTA(15M参数)小型模型结构平均得81.53分,这与BERT-Base的82.20(M110参数)相似。我们的模型、代码和领导板可在http://github.com/smb.