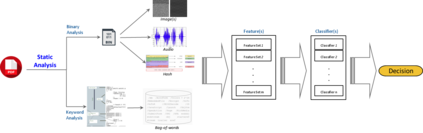
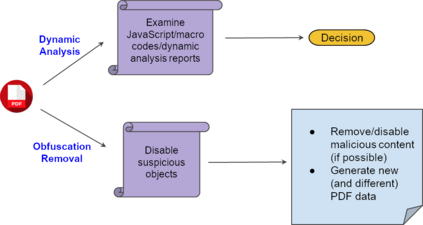
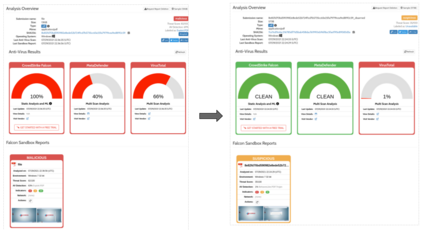
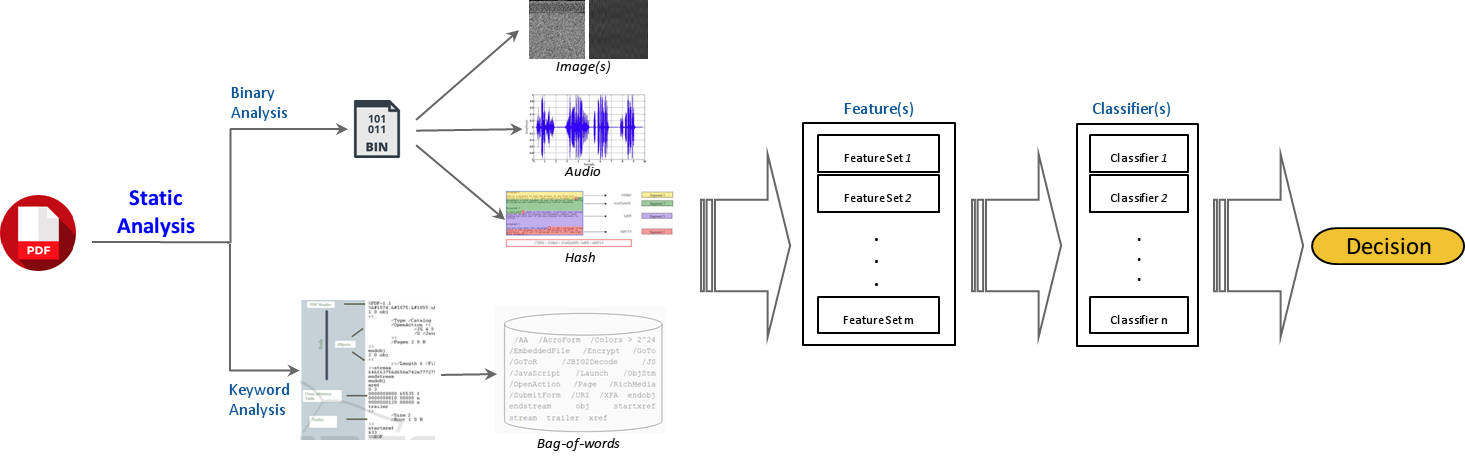
Malicious PDF documents present a serious threat to various security organizations that require modern threat intelligence platforms to effectively analyze and characterize the identity and behavior of PDF malware. State-of-the-art approaches use machine learning (ML) to learn features that characterize PDF malware. However, ML models are often susceptible to evasion attacks, in which an adversary obfuscates the malware code to avoid being detected by an Antivirus. In this paper, we derive a simple yet effective holistic approach to PDF malware detection that leverages signal and statistical analysis of malware binaries. This includes combining orthogonal feature space models from various static and dynamic malware detection methods to enable generalized robustness when faced with code obfuscations. Using a dataset of nearly 30,000 PDF files containing both malware and benign samples, we show that our holistic approach maintains a high detection rate (99.92%) of PDF malware and even detects new malicious files created by simple methods that remove the obfuscation conducted by malware authors to hide their malware, which are undetected by most antiviruses.
翻译:PDF文件对需要现代威胁情报平台来有效分析和描述PDF恶意软件的身份和行为的各种安全组织构成严重威胁。最先进的方法使用机器学习(ML)来学习PDF恶意软件特征的特征。然而,ML模型往往容易被规避攻击,其中对手模糊恶意软件代码以避免被反病毒检测。在本文中,我们为PDF恶意软件的检测找到了一个简单而有效的整体方法,利用对恶意软件的信号和统计分析。这包括将各种静态和动态恶意软件探测方法中的或孔格空间模型结合起来,以便在面临代码模糊时能够普遍保持稳健。我们使用包含恶意软件和良性样本的近30 000个PDF文件数据集,我们表明我们的综合方法保持了PDF恶意软件软件的高度检测率(99.92%),甚至检测出通过简单方法产生的新的恶意文件,这些方法可以消除恶意软件作者为隐藏恶意软件所制造的错误软件而制造的迷惑,而大多数抗病毒都无法察觉到这些软件。