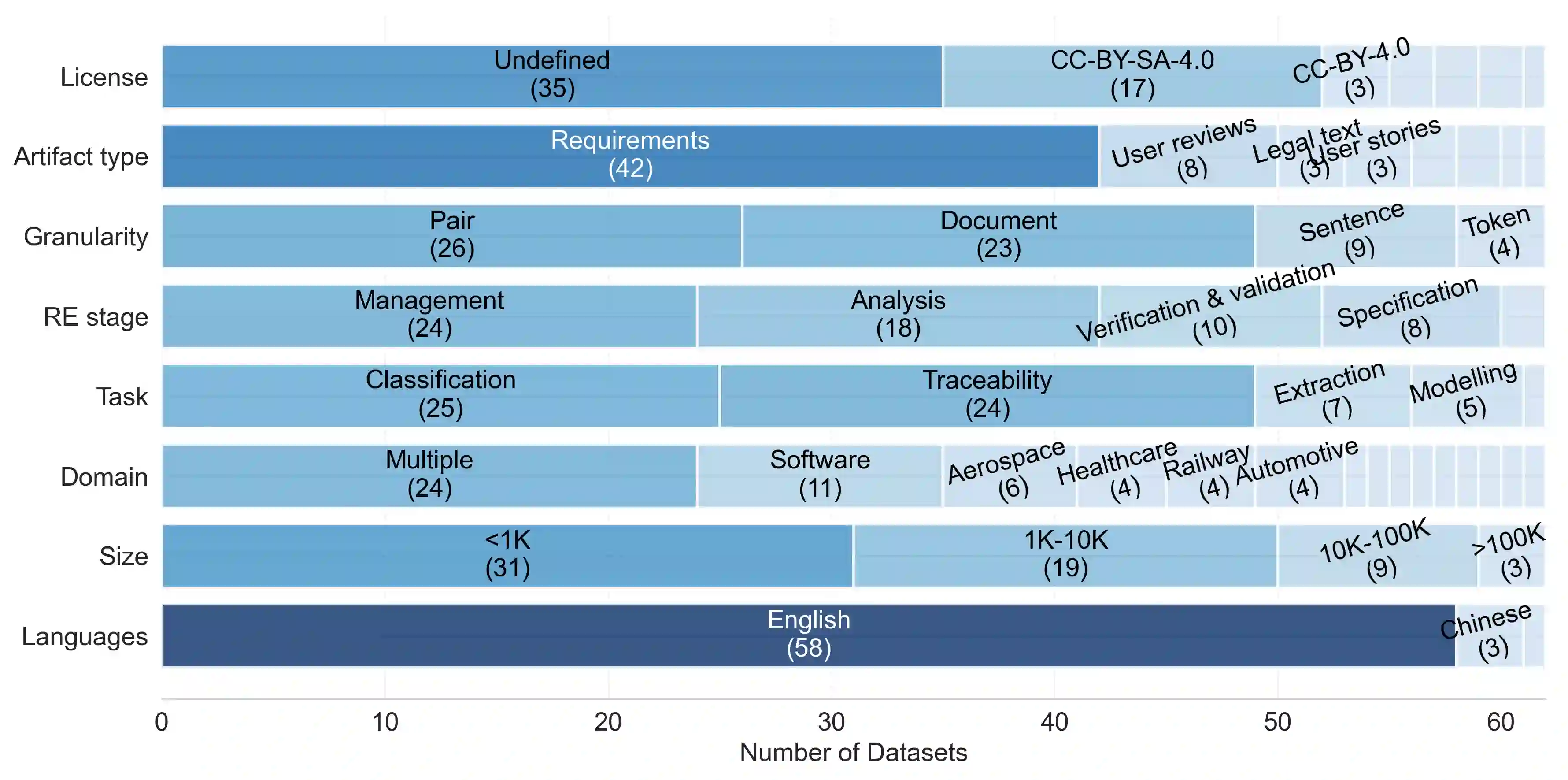
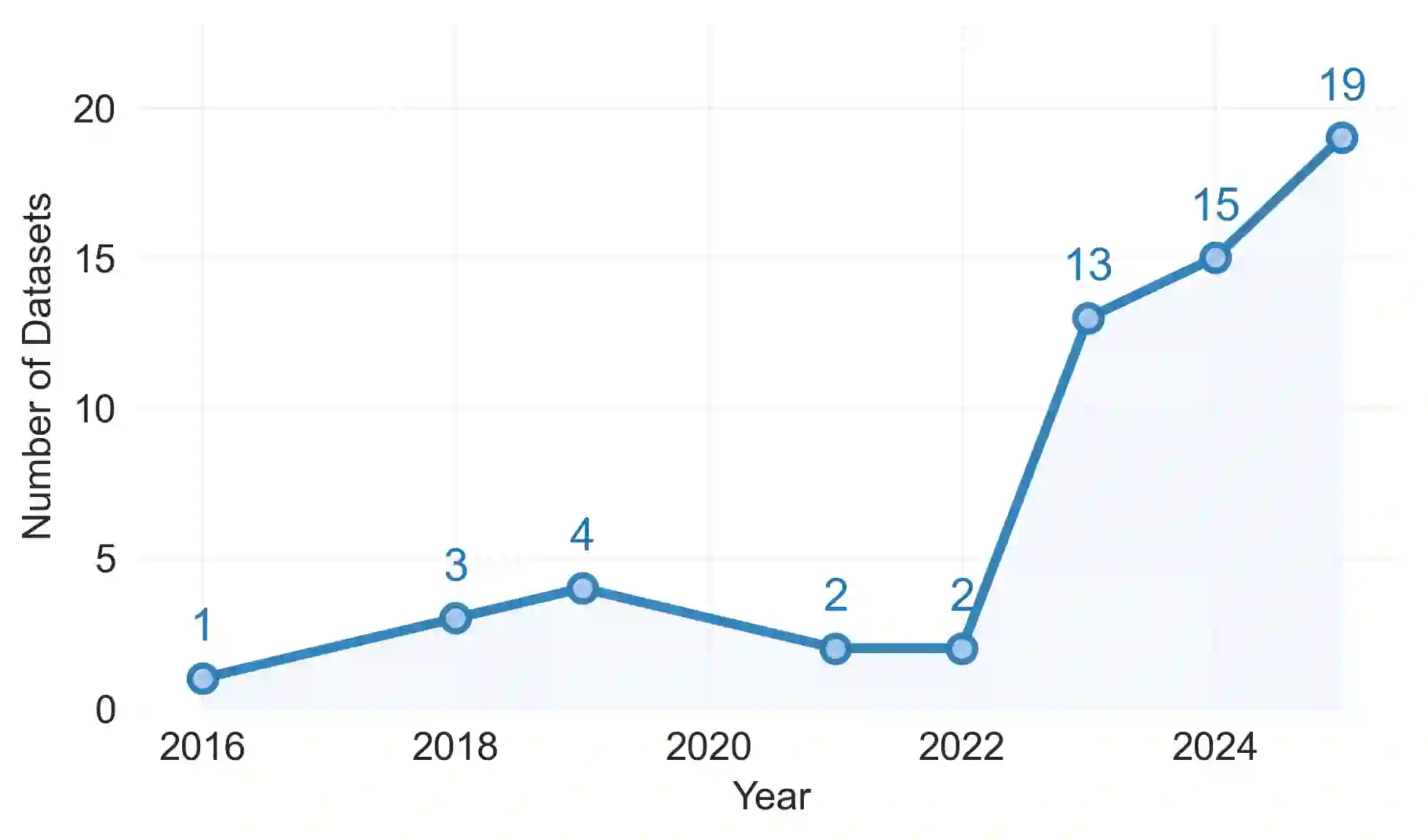
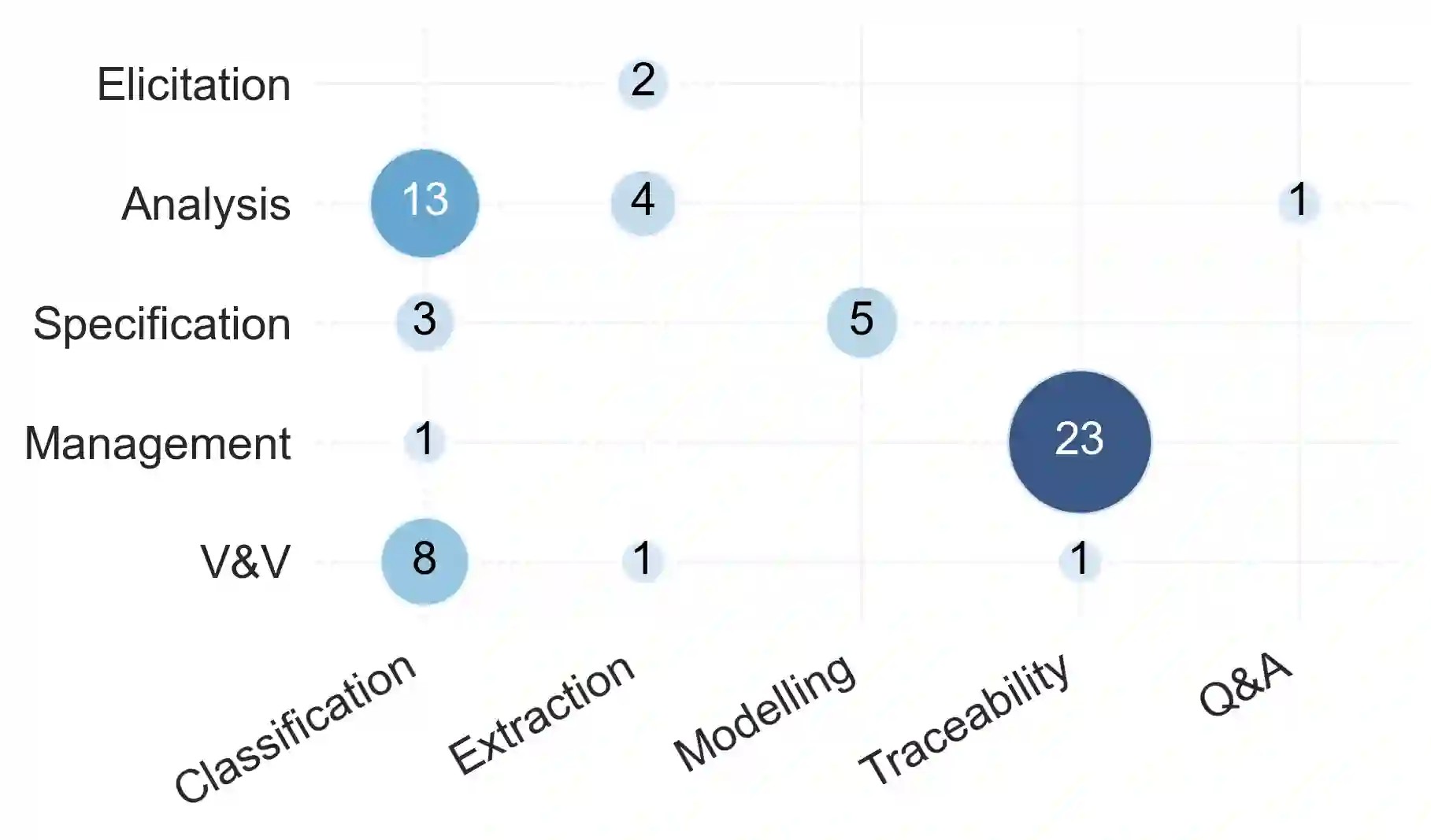
[Context] Large Language Models (LLMs) rely on domain-specific datasets to achieve robust performance across training and inference stages. However, in Requirements Engineering (RE), data scarcity remains a persistent limitation reported in surveys and mapping studies. [Question/Problem] Although there are multiple datasets supporting LLM-based RE tasks (LLM4RE), they are fragmented and poorly characterized, limiting reuse and comparability. This research addresses the limited visibility and characterization of datasets used in LLM4RE. We investigate which public datasets are employed, how they can be systematically characterized, and which RE tasks and dataset descriptors remain under-represented. [Ideas/Results] To address this, we conduct a systematic mapping study to identify and analyse datasets used in LLM4RE research. A total of 62 publicly available datasets are referenced across 43 primary studies. Each dataset is characterized along descriptors such as artifact type, granularity, RE stage, task, domain, and language. Preliminary findings show multiple research gaps, including limited coverage for elicitation tasks, scarce datasets for management activities beyond traceability, and limited multilingual availability. [Contribution] This research preview offers a public catalogue and structured characterization scheme to support dataset selection, comparison, and reuse in LLM4RE research. Future work will extend the scope to grey literature, as well as integration with open dataset and benchmark repositories.
翻译:[背景] 大型语言模型(LLMs)在训练和推理阶段依赖领域特定数据集以实现鲁棒性能。然而,在需求工程(RE)领域,调查与图谱研究持续报告数据稀缺仍是主要限制。[问题] 尽管存在多个支持基于LLM的RE任务(LLM4RE)的数据集,但它们呈现碎片化且特征描述不足,限制了复用性与可比性。本研究针对LLM4RE所用数据集可见度低、特征描述有限的问题展开研究。我们探究了哪些公共数据集被使用、如何系统化表征这些数据集,以及哪些RE任务与数据集描述符仍未被充分覆盖。[方法与结果] 为此,我们开展了系统性图谱研究以识别和分析LLM4RE研究中使用的数据集。通过对43项核心研究的梳理,共发现62个被引用的公开数据集。每个数据集均按制品类型、粒度、RE阶段、任务、领域和语言等描述符进行特征刻画。初步研究结果揭示了多个研究空白,包括需求获取任务覆盖有限、可追溯性之外的管理活动数据集稀缺,以及多语言数据资源不足。[贡献] 本研究成果预告提供了公共目录与结构化表征框架,以支持LLM4RE研究中的数据选择、比较与复用。后续研究将扩展至灰色文献范畴,并与开放数据集及基准测试库进行整合。