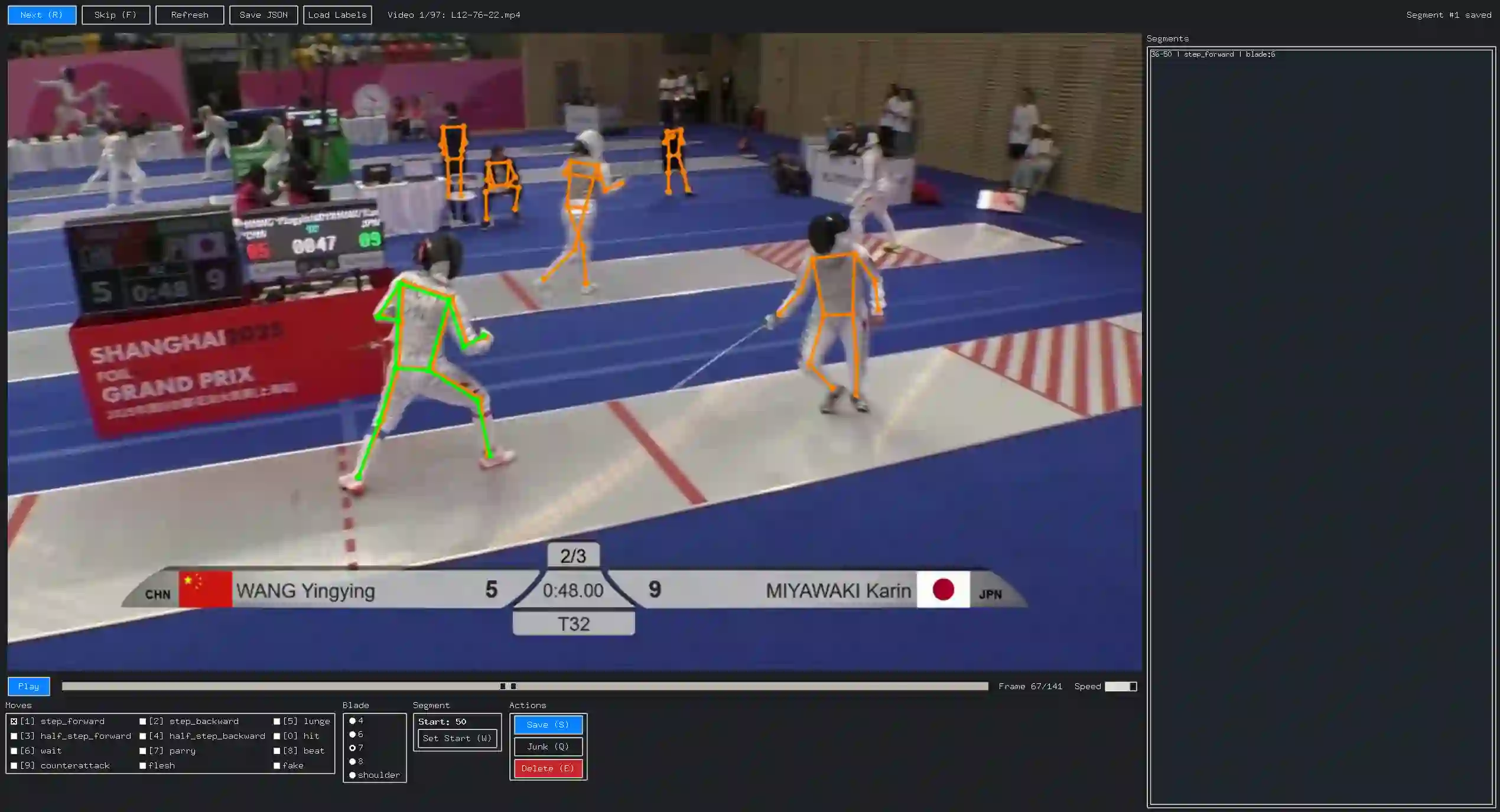
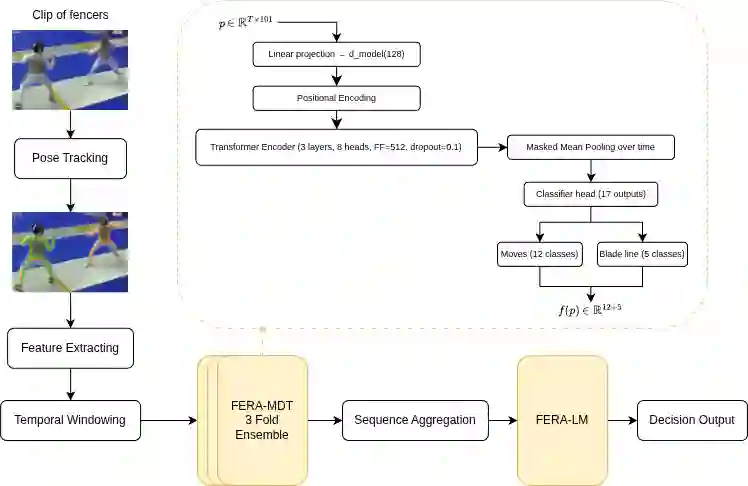
Many multimedia tasks map raw video into structured semantic representations for downstream decision-making. Sports officiating is a representative case, where fast, subtle interactions must be judged via symbolic rules. We present FERA (FEncing Referee Assistant), a pose-based framework that turns broadcast foil fencing video into action tokens and rule-grounded explanations. From monocular footage, FERA extracts 2D poses, converts them into a 101-dimensional kinematic representation, and applies an encoder-only transformer (FERA-MDT) to recognize per-fencer footwork, blade actions, and blade-line position. To obtain a consistent single-fencer representation for both athletes, FERA processes each clip and a horizontally flipped copy, yielding time-aligned left/right predictions without requiring a multi-person pose pipeline. A dynamic temporal windowing scheme enables inference on untrimmed pose tracks. These structured predictions serve as tokens for a language model (FERA-LM) that applies simplified right-of-way rules to generate textual decisions. On 1,734 clips (2,386 annotated actions), FERA-MDT achieves a macro-F1 of 0.549 under 5-fold cross-validation, outperforming BiLSTM and TCN baselines. Combined with FERA-LM, the full pipeline recovers referee priority with 77.7% accuracy on 969 exchanges. FERA provides a case-study benchmark for pose-based semantic grounding in a two-person sport and illustrates a general pipeline for connecting video understanding with rule-based reasoning.
翻译:许多多媒体任务将原始视频映射为结构化语义表示,以供下游决策使用。体育裁判是其中的典型应用场景,需要依据符号化规则对快速、细微的交互动作进行判罚。本文提出FERA(击剑裁判辅助系统),这是一种基于姿态的框架,可将广播级花剑击剑视频转化为动作标记及基于规则的解释说明。该系统从单目视频流中提取二维姿态,将其转换为101维运动学表征,并应用纯编码器Transformer模型(FERA-MDT)来识别每位运动员的步法动作、剑身动作及剑线位置。为获得两名运动员统一化的单人表征,FERA对每个视频片段及其水平翻转副本进行并行处理,无需多人姿态流程即可生成时间对齐的左右侧预测结果。动态时序窗口方案支持对未裁剪姿态轨迹进行推理。这些结构化预测结果将作为语言模型(FERA-LM)的输入标记,该模型通过简化的优先权规则生成文本判罚决策。在1,734个视频片段(含2,386个标注动作)的5折交叉验证中,FERA-MDT取得了0.549的宏观F1分数,优于BiLSTM和TCN基线模型。结合FERA-LM的完整流程在969次交锋中恢复了77.7%的裁判优先权判定准确率。FERA为双人运动中基于姿态的语义落地提供了案例研究基准,并展示了连接视频理解与规则推理的通用流程范式。