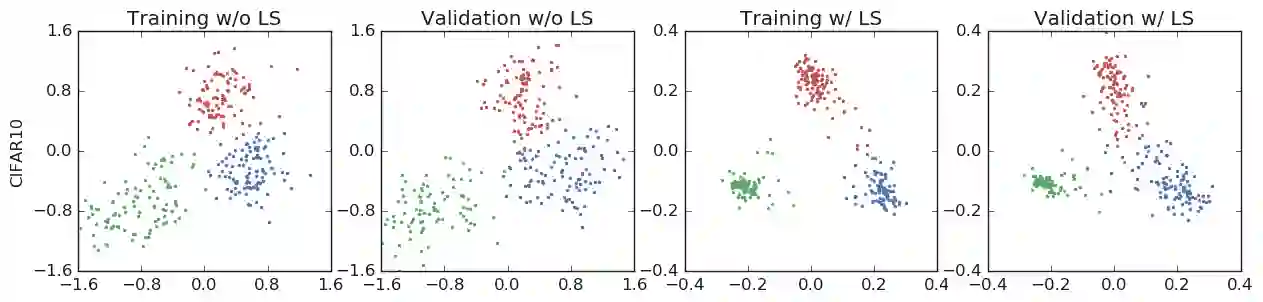
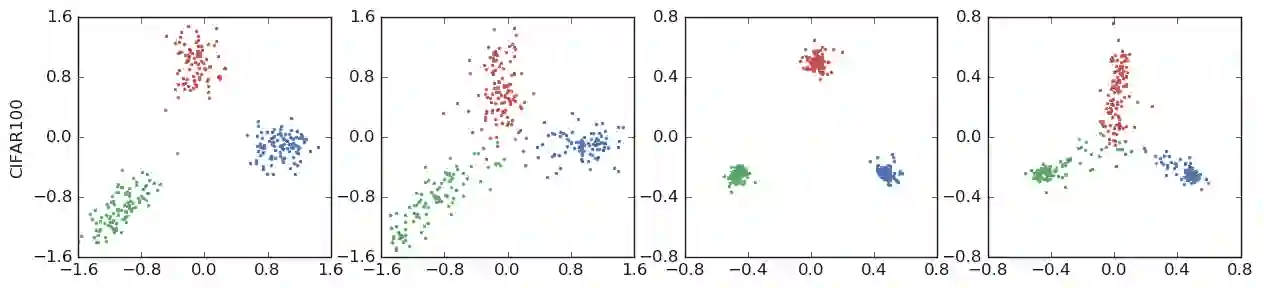
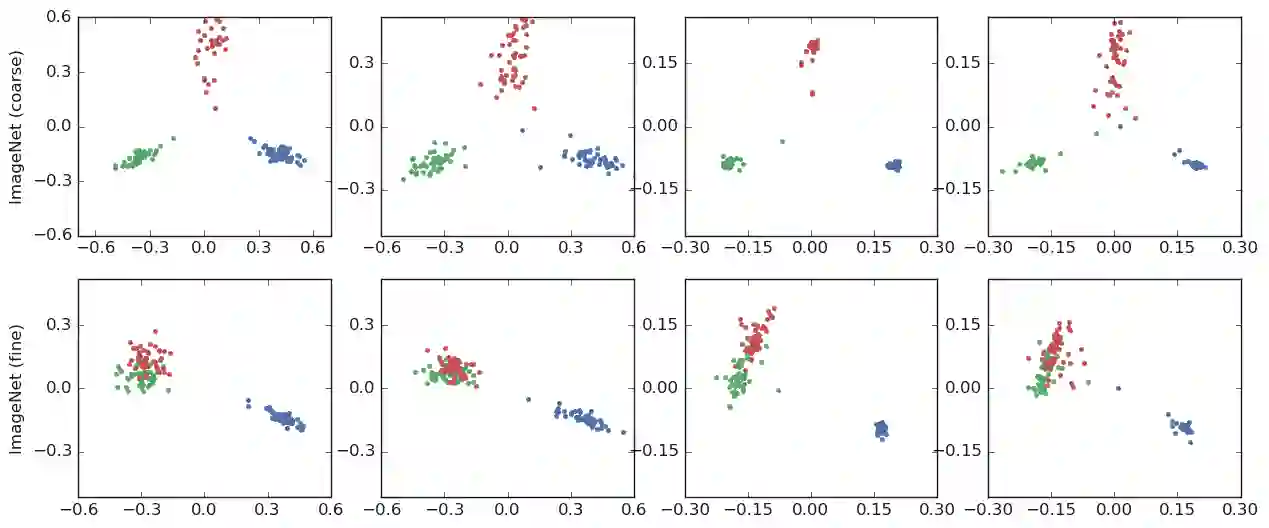
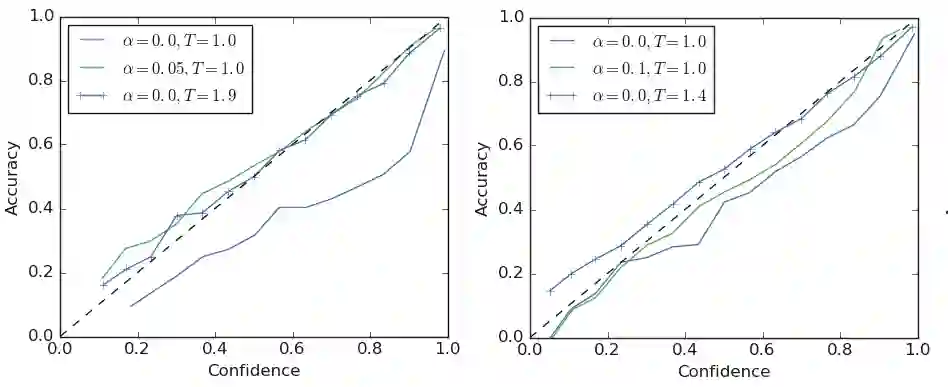
The generalization and learning speed of a multi-class neural network can often be significantly improved by using soft targets that are a weighted average of the hard targets and the uniform distribution over labels. Smoothing the labels in this way prevents the network from becoming over-confident and label smoothing has been used in many state-of-the-art models, including image classification, language translation and speech recognition. Despite its widespread use, label smoothing is still poorly understood. Here we show empirically that in addition to improving generalization, label smoothing improves model calibration which can significantly improve beam-search. However, we also observe that if a teacher network is trained with label smoothing, knowledge distillation into a student network is much less effective. To explain these observations, we visualize how label smoothing changes the representations learned by the penultimate layer of the network. We show that label smoothing encourages the representations of training examples from the same class to group in tight clusters. This results in loss of information in the logits about resemblances between instances of different classes, which is necessary for distillation, but does not hurt generalization or calibration of the model's predictions.
翻译:多级神经网络的普及和学习速度通常可以通过使用硬目标的加权平均值和标签统一分布的软目标来大大改进。 平滑标签使网络不会过于自信和标签平滑在许多最先进的模型中使用, 包括图像分类、 语言翻译和语音识别。 尽管标签平滑被广泛使用, 但是仍然很难理解。 我们在这里的经验显示, 除了改进一般化之外, 标签平滑会改进模型校准, 从而大大改进光束搜索。 但是, 我们还观察到, 如果教师网络受过标签平滑的培训, 知识蒸馏到学生网络的效果要低得多。 为了解释这些观察, 我们直观地看到, 标签平滑会如何改变网络侧面层所学到的演示。 我们显示, 标签平滑会鼓励将同一班级的培训实例展示到紧凑的组中。 这导致不同班级之间对相似点的对数的对数丢失, 这对于蒸馏是必要的, 但不会妨碍模型预测的概括化或校准。