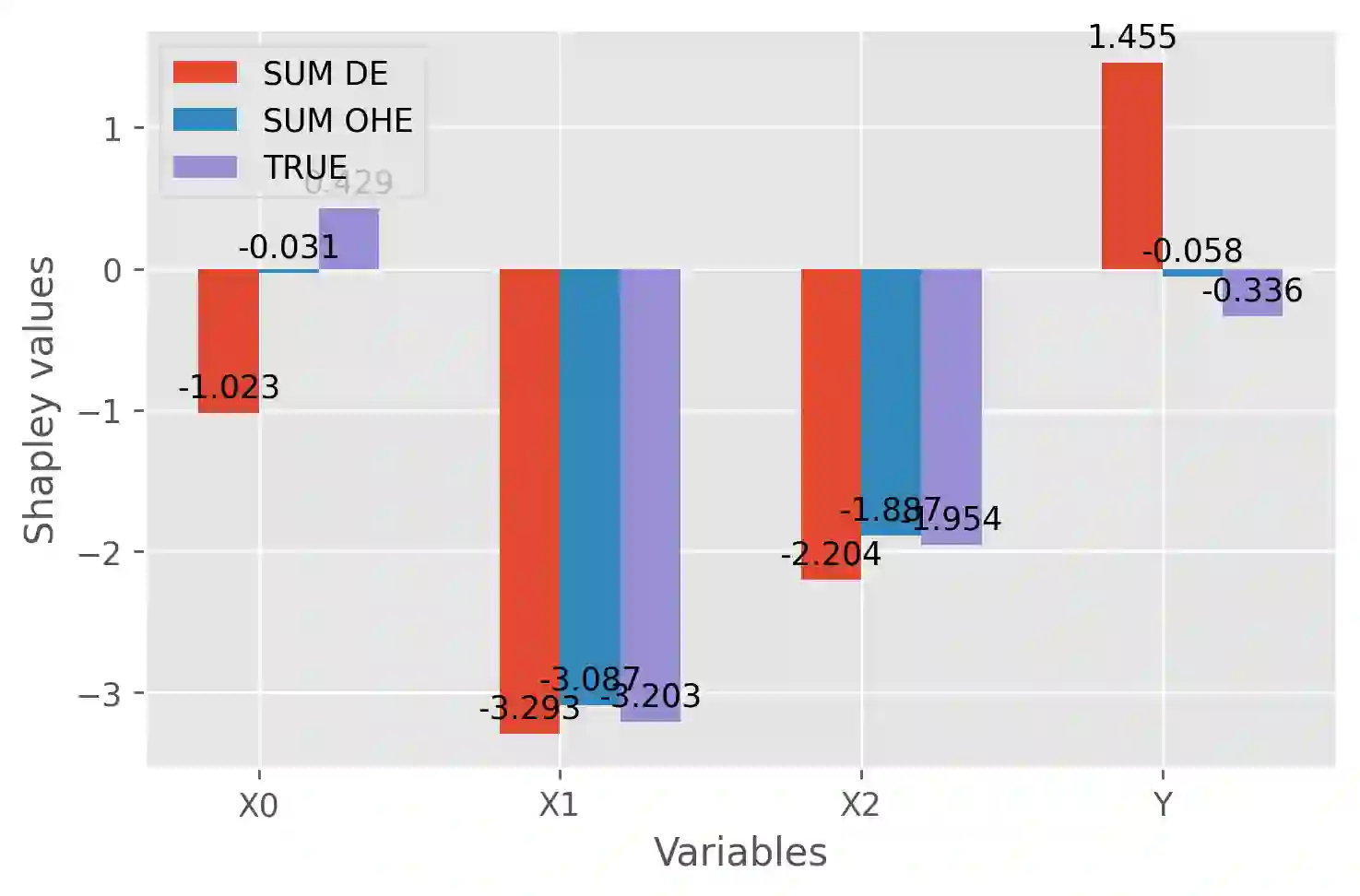
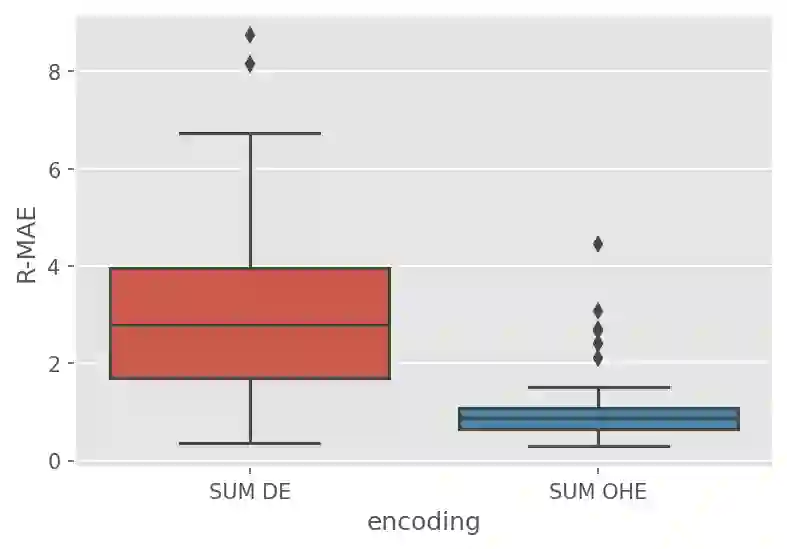
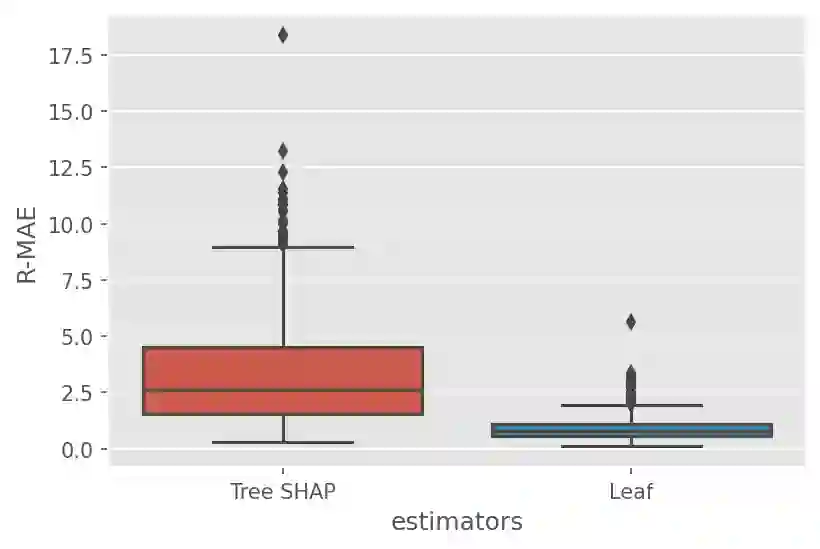
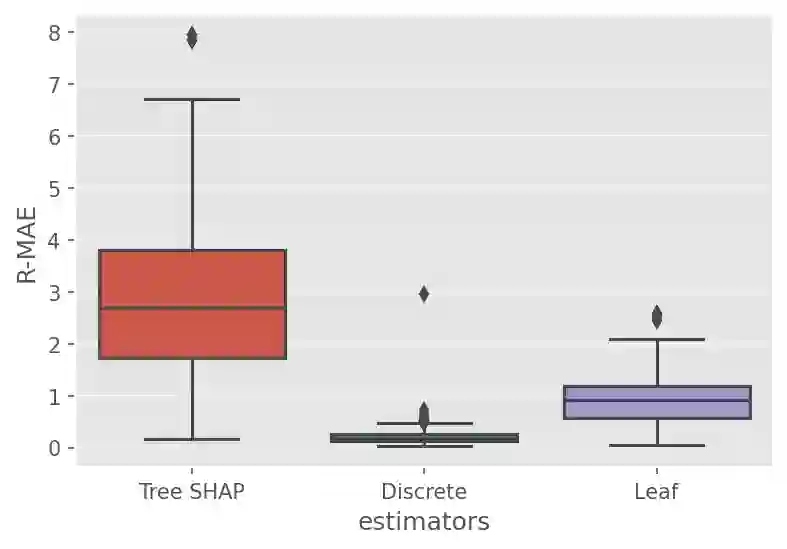
Although Shapley Values (SV) are widely used in explainable AI, they can be poorly understood and estimated, which implies that their analysis may lead to spurious inferences and explanations. As a starting point, we remind an invariance principle for SV and derive the correct approach for computing the SV of categorical variables that are particularly sensitive to the encoding used. In the case of tree-based models, we introduce two estimators of Shapley Values that exploit efficiently the tree structure and are more accurate than state-of-the-art methods. For interpreting additive explanations, we recommend to filter the non-influential variables and to compute the Shapley Values only for groups of influential variables. For this purpose, we use the concept of "Same Decision Probability" (SDP) that evaluates the robustness of a prediction when some variables are missing. This prior selection procedure produces sparse additive explanations easier to visualize and analyse. Simulations and comparisons are performed with state-of-the-art algorithm, and show the practical gain of our approach.
翻译:虽然在可解释的人工智能中广泛使用光谱值(SV),但是这些光谱值(SV)可能会被错误地理解和估计,这意味着其分析可能导致虚假的推论和解释。作为一个起点,我们提醒SV的惯性原则,并得出计算对所用编码特别敏感的绝对变量的正确方法。在树基模型中,我们引入两个光谱值估计器,这些光谱值有效利用了树结构,并且比最先进的方法更准确。在解释添加解释时,我们建议过滤非隐含变量,只对有影响力的变量组群计算光谱值。为此,我们使用“相同决定概率”的概念来评估某些变量缺失时预测的稳健性。我们之前的筛选程序产生稀有的添加解释,便于可视化和分析。为了解释,我们用最先进的算法进行模拟和比较,并展示我们方法的实际收益。