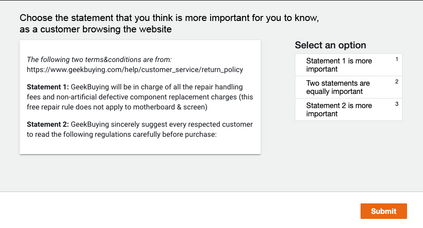
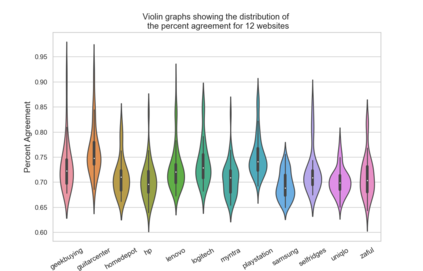
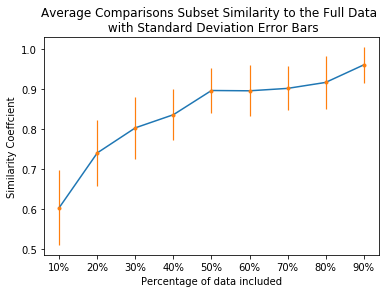
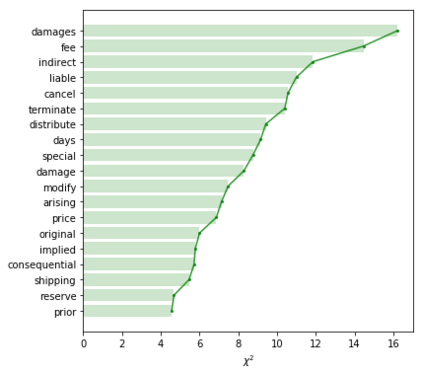
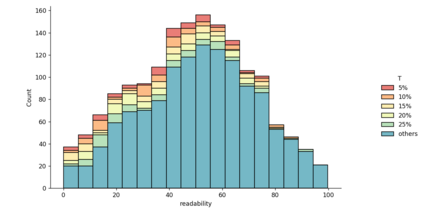
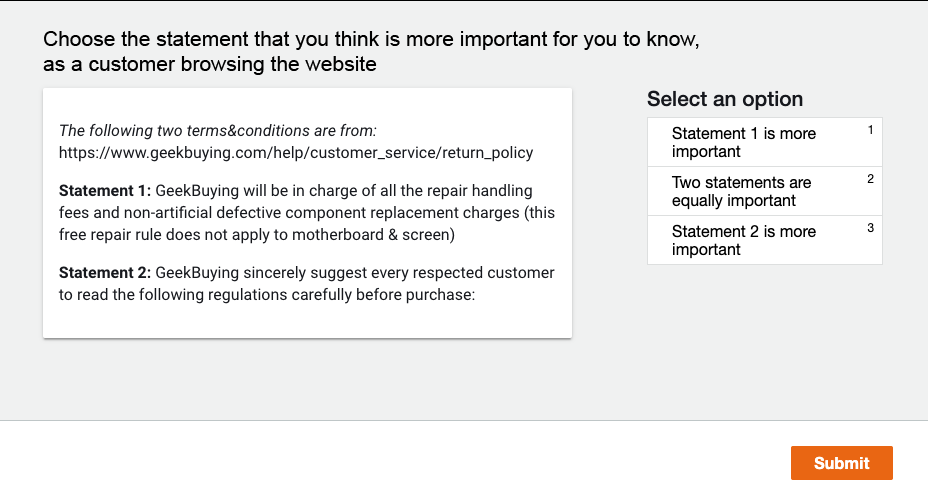
Terms and conditions (T&Cs) are pervasive on the web and often contain important information for consumers, but are rarely read. Previous research has explored methods to surface alarming privacy policies using manual labelers, natural language processing, and deep learning techniques. However, this prior work used pre-determined categories for annotations, and did not investigate what consumers really deem as important from their perspective. In this paper, we instead combine crowdsourcing with an open definition of "what is important" in T&Cs. We present a workflow consisting of pairwise comparisons, agreement validation, and Bradley-Terry rank modeling, to effectively establish rankings of T&C statements from non-expert crowdworkers on this open definition, and further analyzed consumers' preferences. We applied this workflow to 1,551 T&C statements from 27 e-commerce websites, contributed by 3,462 unique crowd workers doing 203,068 pairwise comparisons, and conducted thematic and readability analysis on the statements considered as important/unimportant. We found that consumers especially cared about policies related to after-sales and money, and tended to regard harder-to-understand statements as more important. We also present machine learning models to identify T&C clauses that consumers considered important, achieving at best a 92.7% balanced accuracy, 91.6% recall, and 89.2% precision. We foresee using our workflow and model to efficiently and reliably highlight important T&Cs on websites at a large scale, improving consumers' awareness
翻译:互联网上的条款和条件(T&Cs)在网上非常普遍,常常包含消费者的重要信息,但很少阅读。以前的研究探索了使用人工标签、自然语言处理和深层学习技巧来显示令人震惊的隐私政策的方法。然而,先前的工作使用预先确定的注释类别,没有从消费者的角度调查消费者真正认为什么重要。在本文中,我们把众包与开放定义结合起来,在T & Cs中“什么重要”的“什么重要”。我们提出了一个工作流程,包括对等比较、协议验证和布拉德利-Tery排名模型,以有效确定非专家人群工人对这一开放定义的T & C声明的排名,并进一步分析消费者偏好。我们将这一工作流程应用于27个电子商务网站的1 551个T & C声明,由3,462个独特的人群工人进行了203,068次对齐比对,并对被认为重要/不重要的言论进行了专题和可读性分析。我们发现,消费者特别关心与售后和金钱有关的政策,并且倾向于将更难理解的声明视为更重要。我们还将机器学习了91 %的准确性模型,在T&C的精确度上确定了我们为91%的精确的准确性网站。