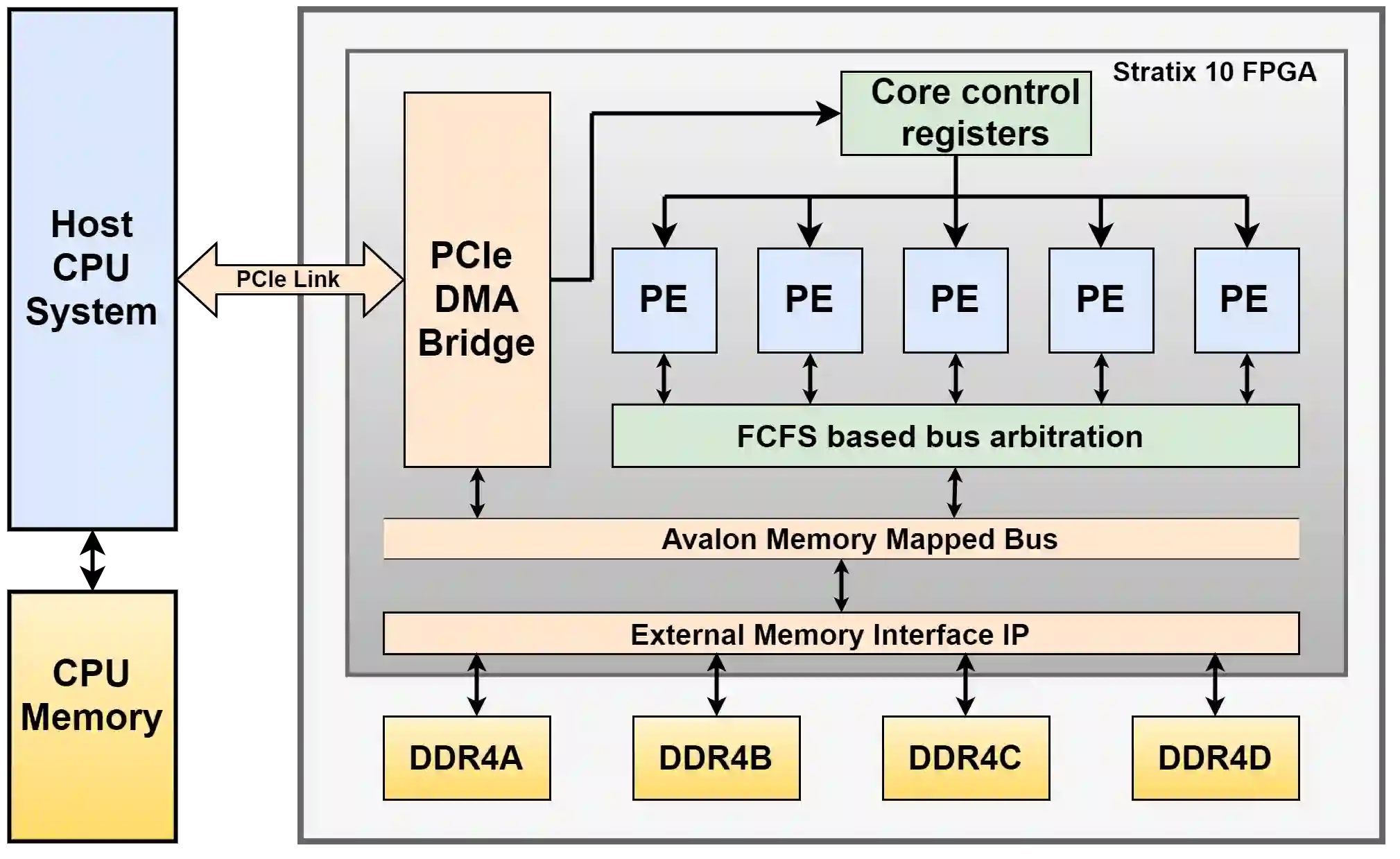
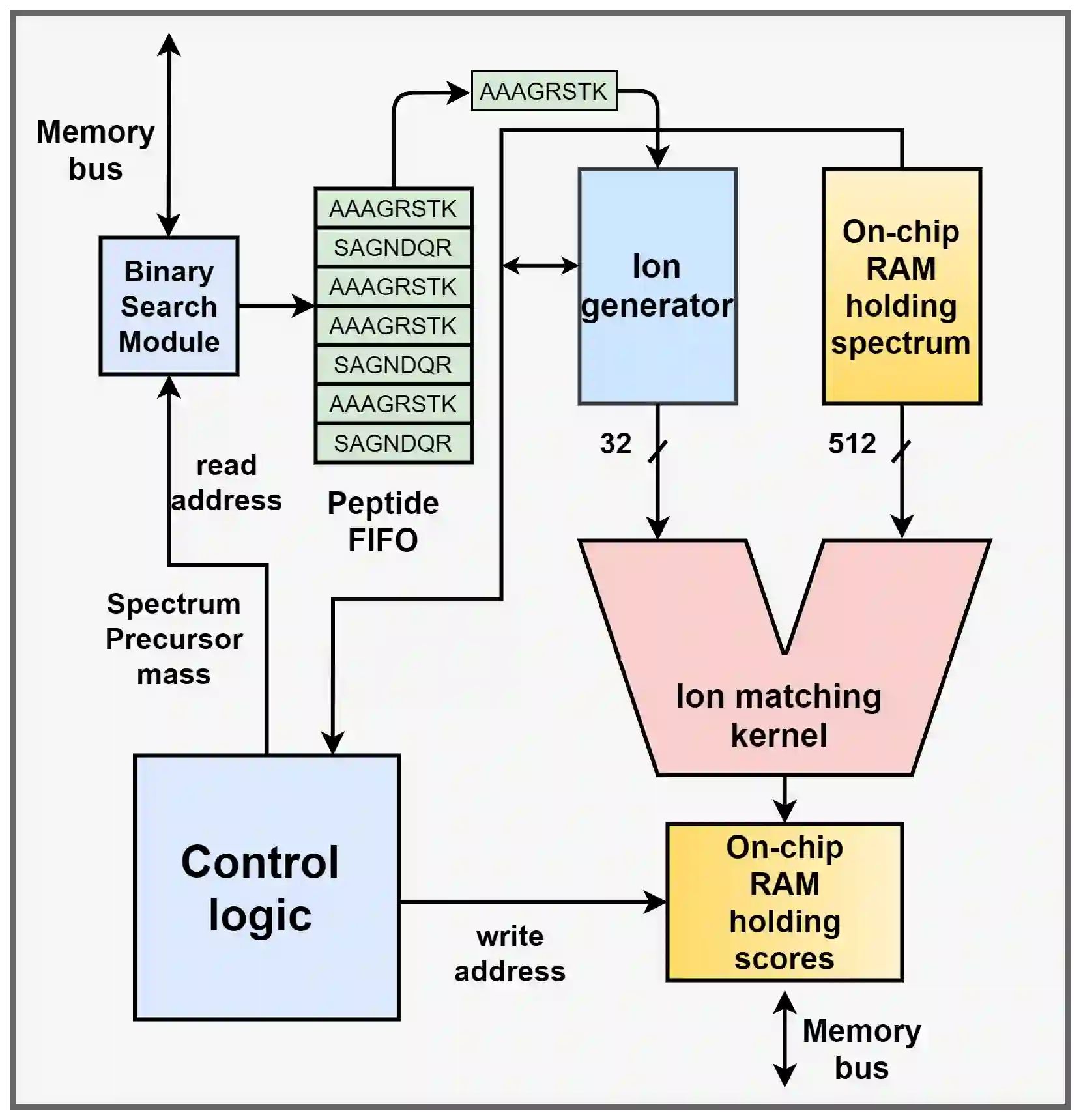
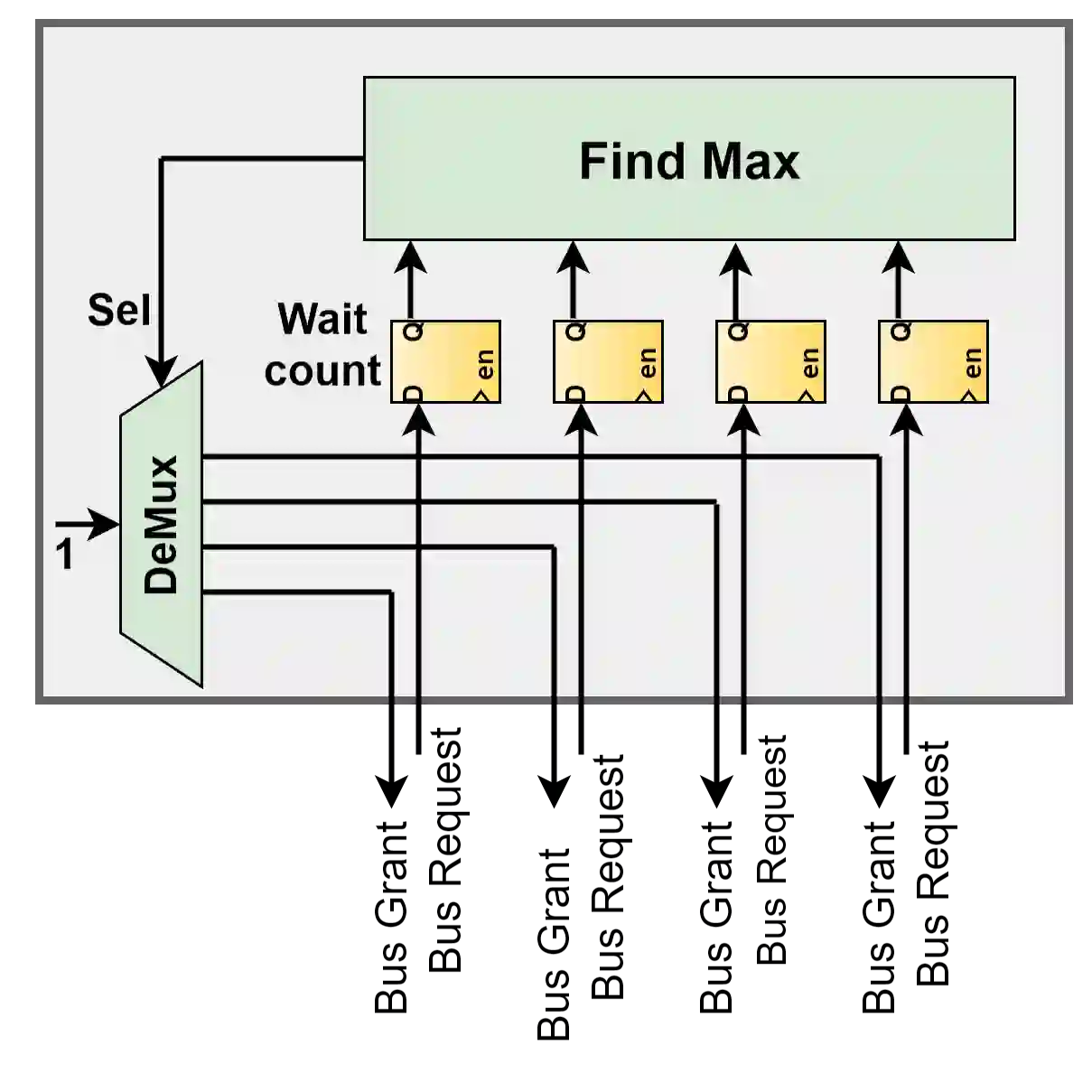
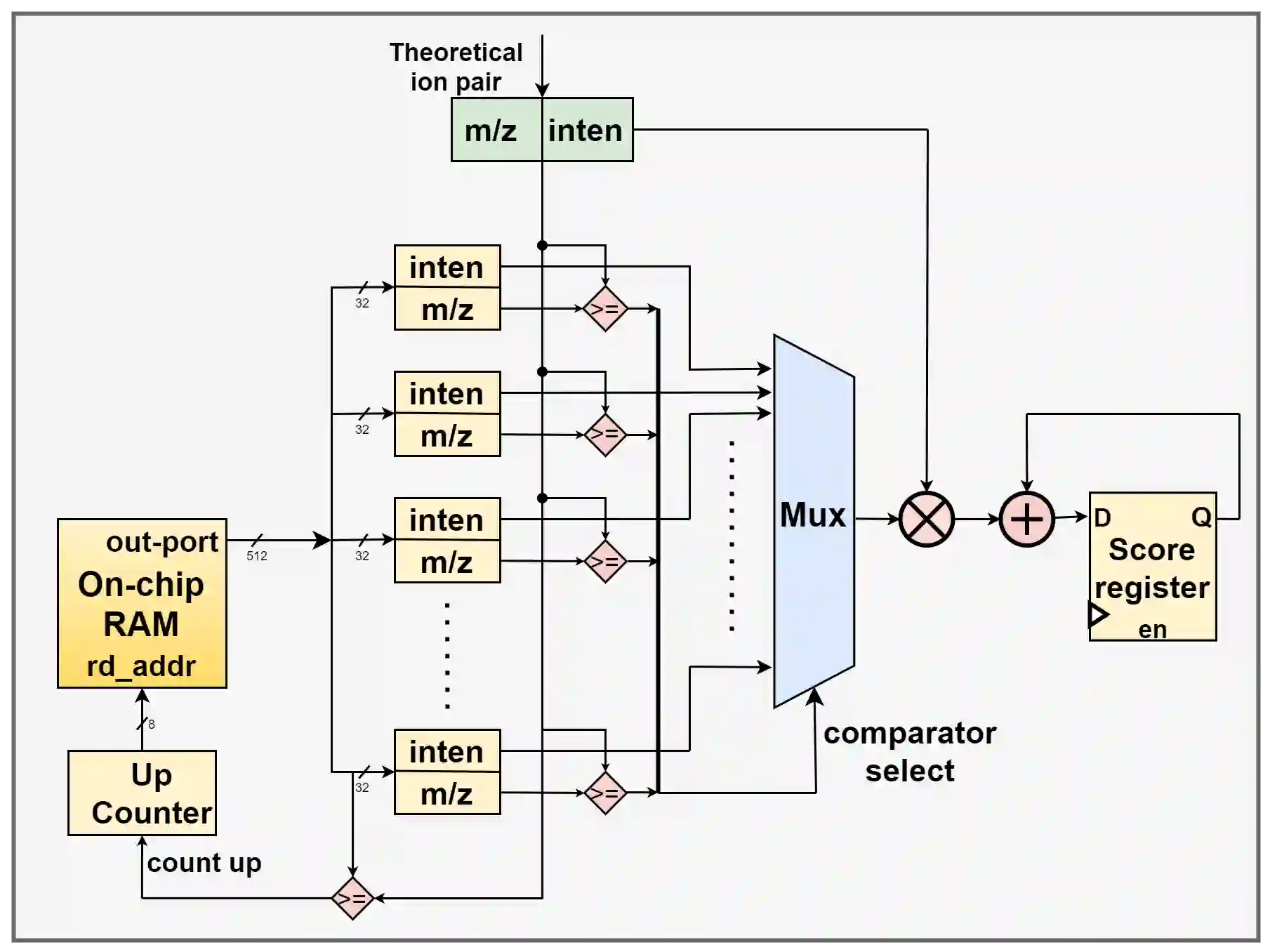
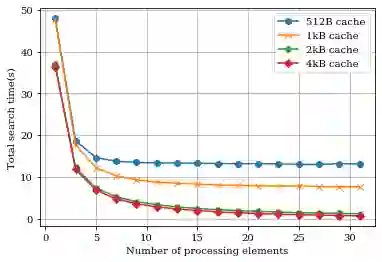
Database algorithms play a crucial part in systems biology studies by identifying proteins from mass spectrometry data. Many of these database search algorithms incur huge computational costs by computing similarity scores for each pair of sparse experimental spectrum and candidate theoretical spectrum vectors. Modern MS instrumentation techniques which are capable of generating high-resolution spectrometry data require comparison against an enormous search space, further emphasizing the need of efficient accelerators. Recent research has shown that the overall cost of scoring, and deducing peptides is dominated by the communication costs between different hierarchies of memory and processing units. However, these communication costs are seldom considered in accelerator-based architectures leading to inefficient DRAM accesses, and poor data-utilization due to irregular memory access patterns. In this paper, we propose a novel communication-avoiding micro-architecture to compute cross-correlation based similarity score by utilizing efficient local cache, and peptide pre-fetching to minimize DRAM accesses, and a custom-designed peptide broadcast bus to allow input reuse. An efficient bus arbitration scheme was designed, and implemented to minimize synchronization cost and exploit parallelism of processing elements. Our simulation results show that the proposed micro-architecture performs on average 24x better than a CPU implementation running on a 3.6 GHz Intel i7-4970 processor with 16GB memory.
翻译:数据库算法通过从质量光谱测量数据中找出蛋白质,在系统生物学研究中发挥着关键作用。许多数据库搜索算法通过计算每个稀有实验频谱和候选理论频谱矢量的相似分数而产生巨大的计算成本。能够产生高分辨率光谱测量数据的现代MS仪表技术需要与巨大的搜索空间进行比较,进一步强调了高效加速器的需要。最近的研究表明,评分和降压浸泡物的总体成本主要取决于记忆和处理单位不同等级之间的通信成本。然而,这些通信成本很少在基于加速器的建筑中被考虑,这些建筑导致DRAM访问效率低下,以及由于不规则的记忆存取模式导致数据利用不良。在本文中,我们提出一种新的通信支持微型结构,通过利用高效的本地缓存和浸渍前推法来最大限度地减少DRAM访问量,以及定制的浸泡式广播巴士以允许输入再利用。一个高效的公共汽车仲裁计划,导致DRAM访问效率低效率的DRAM访问权限,由于不规则的存取模式而导致数据利用差。在本文中,我们提出了一个新的通信支持微型结构,并实施了一个比我们平均同步的模拟的模拟的模拟进程。运行。