提升机器学习训练数据多样性,增加医学应用可训练数据量
文 / Google Health 软件工程师 Timo Kohlberger 和 Yuan Liu
机器学习 (ML) 在医学成像方面的进步帮助医生可以给出更好的诊断,这在一定程度上得益于对详细标记的大型数据集的使用。
进步
https://ai.googleblog.com/search/label/Health
但在现实中,由于隐私顾虑、合作机构的患者数量较少,或是研究方向为罕见病领域等原因,数据集规模常常会受到限制。
此外,为确保 ML 模型能够很好地泛化,这些模型需要包含一系列子组(如在不同的皮肤类型、依照一定人口统计比例或不同的成像设备等)的训练数据。在这种情况下, “其中每个组合的子组的规模也要足够大(如:使用 C 类成像设备拍摄的患有 B 类皮肤病的 A 类型皮肤人群)” 的类似要求往往显得很不切实际。
今天,我们在这里与大家分享两个项目,这两个项目旨在提升 ML 训练数据的多样性,同时增加医学应用可用训练数据量。
第一个项目是生成合成皮肤病变图像的可配置方法,能够扩大罕见皮肤类型和症状的覆盖范围。第二个项目是使用合成图像作为训练数据来研发 ML 模型,从而更好地解释在不同成像设备上生成的不同生物组织类型。
生成各种皮肤症状图像
在于 NeurIPS 2019 机器学习促进健康 (Machine Learning for Health, ML4H) 研讨会上发表的论文《DermGAN:与病理学相结合的临床皮肤图像合成生成》(DermGAN: Synthetic Generation of Clinical Skin Images with Pathology) 中,我们解决了由消费者级相机拍摄的皮肤病学图像(去识别化的)中与数据多样性有关的问题。
NeurIPS 2019 机器学习促进健康
https://ml4health.github.io/2019/pages/papers.htmlDermGAN:与病理学相结合的临床皮肤图像合成生成
https://arxiv.org/abs/1911.08716
-
罕见皮肤症状的成像数据表征缺乏 某些 Fitzpatrick 皮肤类型的数据量较少。
Fitzpatrick 皮肤类型涵盖 I 型(“苍白皮肤,易晒伤,但从不晒黑”)到 VI 型(“深棕色皮肤,从不晒伤”)六种皮肤,数据集通常包含“边界”处相对较少的案例。由于缺乏标准化的照明、对比度和视野、背景变化(如家具和衣服)和皮肤的微小细节(如毛发和皱纹),在上述的这两种情况下目标图像的信噪比通常较低,从而加重数据缺乏问题。
边界”处相对较少的案例
https://arxiv.org/abs/1910.13268
为增加皮肤图像的多样性,我们开发了一个名为 DermGAN 的模型,由该模型生成的皮肤图像可展现预定义(如皮肤症状、位置和基础皮肤颜色)特征。DermGAN 使用图像到图像的转化方法,基于 pix2pix 生成对抗网络 (GAN) 架构,学习从一种图像到另一种图像的基础映射。
pix2pix
http://openaccess.thecvf.com/content_cvpr_2017/papers/Isola_Image-To-Image_Translation_With_CVPR_2017_paper.pdf
DermGAN 输入真实图像及表示真实图像基础特征(例如皮肤症状、病变位置和皮肤类型)的相应预生成语义图,并据此生成具有要求特征的新合成示例。生成器基于 U-Net 架构,但为了减少棋盘效应,我们将反卷积层替换为调整大小层,然后进行卷积。为了提高合成图像(尤其是病理区域内)的质量,我们引入了自定义损失。DermGAN 的 判别器 组件仅用于训练,而 生成器 既在视觉方面,也在增强用于皮肤症状分类器的训练数据集这一用途方面进行评估。
U-Net
https://arxiv.org/abs/1505.04597-
棋盘效应
https://distill.pub/2016/deconv-checkerboard/
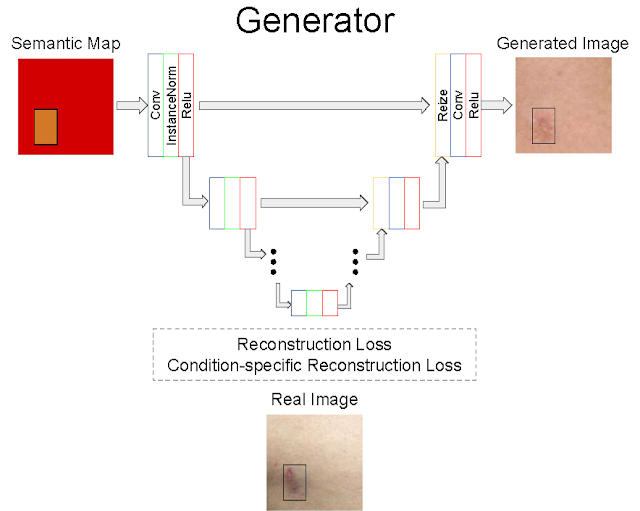
DermGAN 的生成器组件概览。该模型使用注有皮肤症状的规模和位置(较小的橙色矩形)的 RGB 语义图(红色框),输出真实的皮肤图像。彩色边框表示多种神经网络层,如卷积层和 ReLU。跳跃连接与 U-Net 类似,使信息能够以合适的规模传播
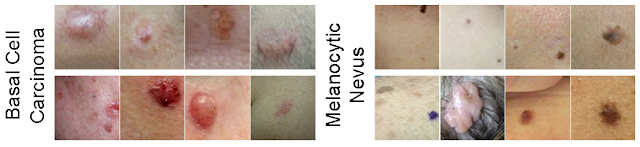
上排展示的是生成的合成示例,下排展示的是基底细胞癌(左)和黑素细胞痣(右)的真实图像。更多示例,请参阅我们的论文
除了生成视觉效果逼真的图像外,我们的方法还可以生成皮肤症状或皮肤类型的图像,这些图像的皮肤状况或类型较为少见,且皮肤病图像数据较少。
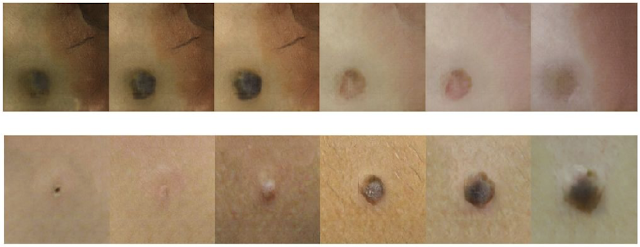
DermGAN 可以生成具有不同皮肤类型(上排,通过改变输入皮肤颜色)和不同病变面积(下排,通过改变输入病变面积)的皮肤图像(此案例中均为黑素细胞痣)。由于输入皮肤颜色改变,病变外观也随之改变,从而与不同皮肤类型的病变外观相符
早期结果表明,使用生成的图像作为训练皮肤病分类器的额外数据,可能会改善对黑色素瘤等罕见病的检测效果。但是,我们还需要进行更多研究,探索如何最好地利用这种生成图像,从而更普遍地提升罕见皮肤类型和症状的检测准确度。
在各种扫描仪上生成具有不同标签的病理学图像
医学图像的焦点质量对准确诊断非常重要。焦点质量差会导致假阳性 (False Positives) 和假阴性 (False Negatives),即使其他方面都使用基于 ML 的精确转移性乳腺癌检测算法中也是如此。
转移性乳腺癌检测算法
https://ai.googleblog.com/2018/10/applying-deep-learning-to-metastatic.html
由于图像采集过程相对复杂,很难确定病理学图像是否对焦。数字化的全载玻片成像的完整图像也可能聚焦较差,并且由于这种图像是由数千个视野较小的图像拼接而成,部分子区域也有可能有不同的焦点属性。这使得采取人工手动检查聚焦质量的方法变得不切实际,并促使我们研究能够自动检测焦点质量较差的图像以及定位失焦 (out-of-focus) 区域的方法。识别焦点质量较差的区域可能会实现重新扫描,或为改善扫描过程中使用的聚焦算法提供机会。
在发表于《病理信息学杂志》(Journal of Pathology Informatics) 的《全载玻片图像焦点质量:自动评估和对 AI 癌症检测的影响》(Whole-slide image focus quality: Automatic assessment and impact on AI cancer detection) 一文中, 我们介绍了第二个项目。针对焦点质量问题,我们开发了一种评估去识别化大型十亿像素病理学图像的方法。
病理信息学杂志
http://www.jpathinformatics.org/aboutus.asp全载玻片图像焦点质量:自动评估和对 AI 癌症检测的影响
http://www.jpathinformatics.org/article.asp?issn=2153-3539;year=2019;volume=10;issue=1;spage=39;epage=39;aulast=Kohlberger
这一方法涉及使用表示不同组织类型和载玻片扫描仪光学属性的半合成训练数据训练卷积神经网络。但是,开发这种基于 ML 的系统的关键难点在于缺乏标记数据,即难以对焦点质量进行可靠分级,且没有可用的标记数据集。
由于焦点质量会影响图像的微小细节,在特定扫描仪中收集的任何数据都无法代表其他扫描仪,使用的扫描仪在物理光学系统、使用捕获的图像图块重新创建大型病理学图像所用的拼接过程、白平衡和后处理算法等方面可能都有所不同,从而加剧这一问题。鉴于此,我们开发了全新的多步系统,用于生成展示真实失焦特征的合成图像。
我们将收集训练数据的过程分解为多个步骤。第一步是从各种扫描仪上收集图像并标记对焦区域。这步比确定图像失焦程度简单,而且可以由非专家人员完成。
接下来,我们生成合成失焦图像,这一步的灵感来源于获取真正的失焦图像前发生的一系列事件:首先是发生光学模糊效应,然后传感器收集光子(这一过程会添加传感器噪声),最后软件压缩添加噪声。
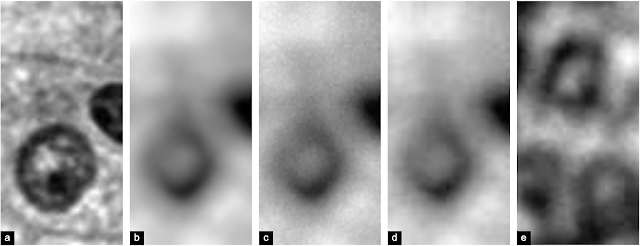
显示逐步失焦图像生成的图像序列。图像以灰度显示,以便强调步骤间的差异。首先,收集对焦图像 (a),然后添加散景效果生成模糊图像 (b)。接下来,添加传感器噪声模拟真实的图像传感器 (c),最后添加 JPEG 压缩模拟后采集软件处理引入的锐利边缘 (d)。e 为真正的失焦图像,可用于比较
我们的研究表明,为每个步骤建模对在各种扫描仪上获得最佳结果至关重要,值得注意的是,我们还在真实数据中检测出了惊人的失焦模型:
-
每个步骤建模
http://www.jpathinformatics.org/viewimage.asp?img=JPatholInform_2019_10_1_39_272775_t13.jpg
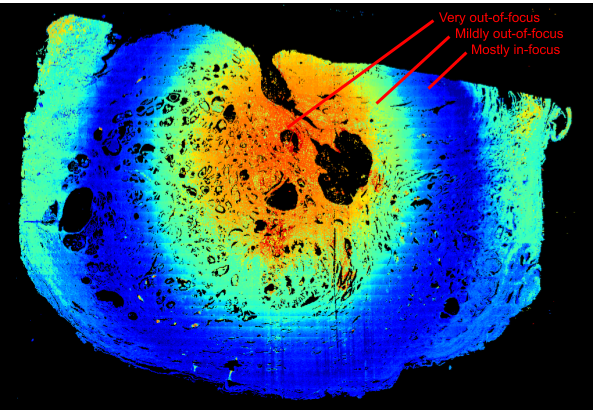
生物组织切片上的有趣失焦模式示例:(蓝色区域是模型识别的对焦区域,而以黄色、橙色或红色突出显示的区域则为失焦区域) 中心坚硬的“石头”将周围的生物组织引起的,导致了此处的焦点渐变(用同心圆表示:红色/橙色的失焦区域周围是轻微失焦的绿色/青色区域,然后是蓝色的聚焦环形区域)
影响及未来展望
尽管用于开发 ML 系统的数据量常被视为基本瓶颈,我们还是提出了生成合成数据的技术,可用于增加 ML 模型 训练 数据的多样性,从而提高 ML 处理更多样化的数据集的能力。
但我们应该注意,这些方法不适合 验证 数据,以防偏见 (如 ML 模型 只 在合成数据方面表现出色)。为确保无偏、统计严格的评估,尽管逆概率加权等技术(如我们研究将 ML 用于胸部 X 光时使用的技术)可能也有用,但我们仍然需要足够的数据量和多样性充足的真实数据。
逆概率加权
https://www.bmj.com/content/352/bmj.i189我们研究将 ML 用于胸部 X 光
https://pubs.rsna.org/doi/10.1148/radiol.2019191293
我们将继续探索其他途径,以便更有效地通过去识别化数据提升数据多样性,以减少在开发用于医疗保健的 ML 模型过程中,对大型数据库的需求。
致谢
这些项目是多学科团队的努力成果,其中包括软件工程师、研究人员、临床医生和跨职能贡献者。这些项目的主要贡献者包括 Timo Kohlberger、Yun Liu, Melissa Moran、Po-Hsuan Cameron Chen、Trissia Brown、Jason Hipp、Craig Mermel、Martin Stumpe、Amirata Ghorbani、Vivek Natarajan、David Coz 和 Yuan Liu。作者还要感谢 Daniel Fenner、Samuel Yang、Susan Huang、Kimberly Kanada、Greg Corrado 和 Erica Brand 提出的宝贵建议、Google Health 皮肤病和病理学团队成员提供的支持,以及 Ashwin Kakarla 和 Shivamohan Reddy Garlapati 团队在图像标记方面的帮助。
更多 AI 相关阅读:



