hyengine - 面向移动端的高性能通用编译/解释引擎

一 背景简介
二 设计简介
注:由于当前手机绝大多数都已支持 arm64,hyengine 仅支持 arm64 的 jit 实现。
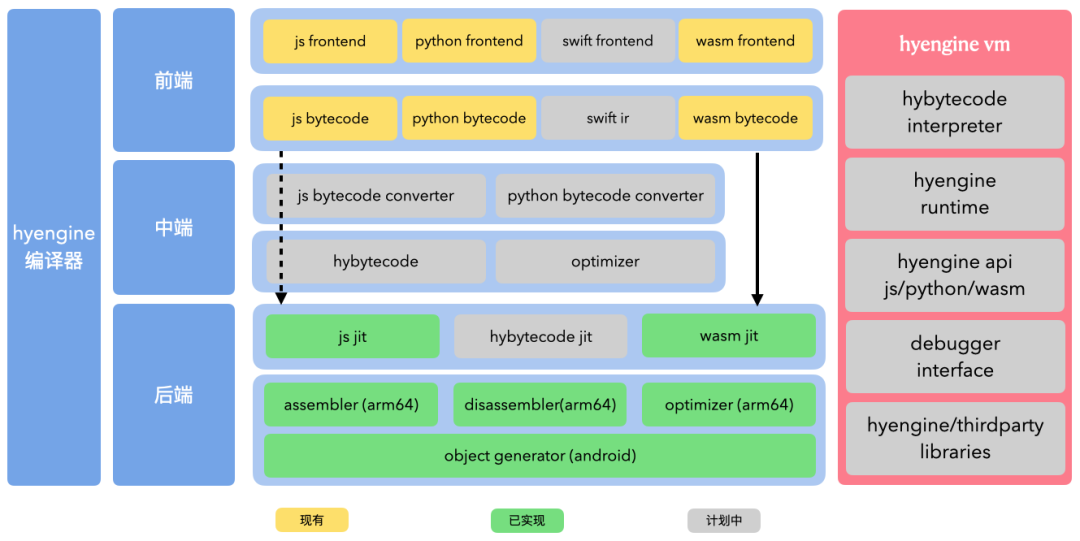
compiler 部分分为前端、中端、后端,其中前端部分复用现有脚本引擎的实现,比如 js 使用 quickjs,wasm 使用 emscripten,中端计划实现一套自己的字节码、优化器及字节码转换器,后端实现了 quickjs 和 wasm 的 jit 及汇编器和优化器。
vm 分为解释器、runtime、api、调试、基础库,由于人力有限,目前VM暂无完整的自有实现,复用quickjs/wasm3 的代码,通过实现一套自己的内分配器及gc,和优化现有runtime实现来提升性能。

注:本方案业界的方舟编译器和 graalvm 可能有一定相似度。
三 实现介绍
1 编译(compiler)部分
汇编器
汇编器的核心代码基于 golang 的 arch 项目已有的指令数据根据脚本生成,并辅佐人工修正及对应的工具代码。
单个汇编代码示例如下:
// Name: ADC// Arch: 32-bit variant// Syntax: ADC <Wd>, <Wn>, <Wm>// Alias: // Bits: 0|0|0|1|1|0|1|0|0|0|0|Rm:5|0|0|0|0|0|0|Rn:5|Rd:5static inline void ADC_W_W_W(uint32_t *buffer, int8_t rd, int8_t rn, int8_t rm) { uint32_t code = 0b00011010000000000000000000000000; code |= IMM5(rm) << 16; code |= IMM5(rn) << 5; code |= IMM5(rd); *buffer = code;}
其中 IMM5 实现如下:
// 0a011f1a| adc w10, w8, wzr ADC_W_W_W(&buffer, R10, R8, RZR); assert(buffer == bswap32(0x0a011f1a));
反汇编器
#define IS_MOV_X_X(ins) \ (IMM11(ins 21) == IMM11(HY_INS_TEMPLATE_MOV_X_X >> 21) && \ IMM11(ins 5) == IMM11(HY_INS_TEMPLATE_MOV_X_X >> 5))
// e7031eaa| mov x7, x30assert(IS_MOV_X_X(bswap32(0xe7031eaa)));
wasm编译
其中核心的翻译的整体实现是一个大的循环 + switch,每遍历一个 opcode 即生成一段对应的机器码,代码示例如下:
M3Result h3_JITFunction(IH3JITState state, IH3JITModule hmodule, IH3JITFunction hfunction) { uint32_t *alloc = state->code + state->codeOffset; ...... // prologue // stp x28, x27, [sp, #-0x60]! // stp x26, x25, [sp, #0x10]! // stp x24, x23, [sp, #0x20] // stp x22, x21, [sp, #0x30] // stp x20, x19, [sp, #0x40] // stp x29, x30, [sp, #0x50] // add x20, sp, #0x50 STP_X_X_X_I_PR(alloc + codeOffset++, R28, R27, RSP, -0x60); STP_X_X_X_I(alloc + codeOffset++, R26, R25, RSP, 0x10); STP_X_X_X_I(alloc + codeOffset++, R24, R23, RSP, 0x20); STP_X_X_X_I(alloc + codeOffset++, R22, R21, RSP, 0x30); STP_X_X_X_I(alloc + codeOffset++, R20, R19, RSP, 0x40); STP_X_X_X_I(alloc + codeOffset++, R29, R30, RSP, 0x50); ADD_X_X_I(alloc + codeOffset++, R29, RSP, 0x50); ...... for (bytes_t i = wasm; i < wasmEnd; i += opcodeSize) { uint32_t index = (uint32_t)(i - wasm) / sizeof(u8); uint8_t opcode = *i; ...... switch (opcode) { case OP_UNREACHABLE: { BRK_I(alloc + codeOffset++, 0); break; }
case OP_NOP: { NOP(alloc + codeOffset++); break; } ...... case OP_REF_NULL: case OP_REF_IS_NULL: case OP_REF_FUNC: default: break; }
if (spOffset > maxSpOffset) { maxSpOffset = spOffset; }
} ...... // return 0(m3Err_none) MOV_X_I(alloc + codeOffset++, R0, 0); // epilogue // ldp x29, x30, [sp, #0x50] // ldp x20, x19, [sp, #0x40] // ldp x22, x21, [sp, #0x30] // ldp x24, x23, [sp, #0x20] // ldp x26, x25, [sp, #0x10] // ldp x28, x27, [sp], #0x60 // ret LDP_X_X_X_I(alloc + codeOffset++, R29, R30, RSP, 0x50); LDP_X_X_X_I(alloc + codeOffset++, R20, R19, RSP, 0x40); LDP_X_X_X_I(alloc + codeOffset++, R22, R21, RSP, 0x30); LDP_X_X_X_I(alloc + codeOffset++, R24, R23, RSP, 0x20); LDP_X_X_X_I(alloc + codeOffset++, R26, R25, RSP, 0x10); LDP_X_X_X_I_PO(alloc + codeOffset++, R28, R27, RSP, 0x60); RET(alloc + codeOffset++); ...... return m3Err_none;}
字节码生成机器码以 wasm 的 opcode i32.add 为例:
case OP_I32_ADD: { LDR_X_X_I(alloc + codeOffset++, R8, R19, (spOffset - 2) * sizeof(void *)); LDR_X_X_I(alloc + codeOffset++, R9, R19, (spOffset - 1) * sizeof(void *)); ADD_W_W_W(alloc + codeOffset++, R9, R8, R9); STR_X_X_I(alloc + codeOffset++, R9, R19, (spOffset - 2) * sizeof(void *)); spOffset--; break;}
这段代码会生成 4 条机器码,分别用于加载位于栈上 spOffset - 2 和 spOffset - 1 位置的两条数据,然后相加,再把结果存放到栈上 spOffset - 2 位置。由于 i32.add 指令会消耗 2 条栈上数据,并生成 1 条栈上数据,最终栈的偏移就要 -1。
上述代码生成的机器码及其对应助记形式如下:
f9400a68: ldr x8, [x19, f9400e69: ldr x9, [x19, 0b090109: add w9, w8, w9f9000a69: str x9, [x19,
以如下 fibonacci 的 c 代码:
uint32_t fib_native(uint32_t n) { if (n < 2) return n; return fib_native(n - 1) + fib_native(n - 2);}
parse | load module: 61 bytes parse | found magic + version parse | ** Type [1] parse | type 0: (i32) -> i32 parse | ** Function [1] parse | ** Export [1] parse | index: 0; kind: 0; export: 'fib'; parse | ** Code [1] parse | code size: 29 compile | compiling: 'fib'; wasm-size: 29; numArgs: 1; return: i32 compile | estimated constant slots: 3 compile | start stack index: 1 compile | 0 | 0x20 .. local.get compile | 1 | 0x41 .. i32.const compile | | .......... (const i32 = 2) compile | 2 | 0x49 .. i32.lt_u compile | 3 | 0x04 .. if compile | 4 | 0x20 .... local.get compile | 5 | 0x0f .... return compile | 6 | 0x0b .. end compile | 7 | 0x20 .. local.get compile | 8 | 0x41 .. i32.const compile | | .......... (const i32 = 2) compile | 9 | 0x6b .. i32.sub compile | 10 | 0x10 .. call compile | | .......... (func= 'fib'; args= 1) compile | 11 | 0x20 .. local.get compile | 12 | 0x41 .. i32.const compile | | .......... (const i32 = 1) compile | 13 | 0x6b .. i32.sub compile | 14 | 0x10 .. call compile | | .......... (func= 'fib'; args= 1) compile | 15 | 0x6a .. i32.add compile | 16 | 0x0f .. return compile | 17 | 0x0b end compile | unique constant slots: 2; unused slots: 1 compile | max stack slots: 7
0x107384000: stp x28, x27, [sp, #-0x60]! 0x107384004: stp x26, x25, [sp, #0x10] 0x107384008: stp x24, x23, [sp, #0x20] 0x10738400c: stp x22, x21, [sp, #0x30] 0x107384010: stp x20, x19, [sp, #0x40] 0x107384014: stp x29, x30, [sp, #0x50] 0x107384018: add x29, sp, #0x50 ; =0x50 0x10738401c: mov x19, x0 0x107384020: ldr x9, [x19] 0x107384024: str x9, [x19, #0x8] 0x107384028: mov w9, #0x2 0x10738402c: str x9, [x19, #0x10] 0x107384030: mov x9, #0x1 0x107384034: ldr x10, [x19, #0x8] 0x107384038: ldr x11, [x19, #0x10] 0x10738403c: cmp w10, w11 0x107384040: csel x9, x9, xzr, lo 0x107384044: str x9, [x19, #0x8] 0x107384048: ldr x9, [x19, #0x8] 0x10738404c: cmp x9, #0x0 ; =0x0 0x107384050: b.eq 0x107384068 0x107384054: ldr x9, [x19] 0x107384058: str x9, [x19, #0x8] 0x10738405c: ldr x9, [x19, #0x8] 0x107384060: str x9, [x19] 0x107384064: b 0x1073840dc 0x107384068: ldr x9, [x19] 0x10738406c: str x9, [x19, #0x10] 0x107384070: mov w9, #0x2 0x107384074: str x9, [x19, #0x18] 0x107384078: ldr x8, [x19, #0x10] 0x10738407c: ldr x9, [x19, #0x18] 0x107384080: sub w9, w8, w9 0x107384084: str x9, [x19, #0x10] 0x107384088: add x0, x19, #0x10 ; =0x10 0x10738408c: bl 0x10738408c 0x107384090: ldr x9, [x19] 0x107384094: str x9, [x19, #0x18] 0x107384098: mov w9, #0x1 0x10738409c: str x9, [x19, #0x20] 0x1073840a0: ldr x8, [x19, #0x18] 0x1073840a4: ldr x9, [x19, #0x20] 0x1073840a8: sub w9, w8, w9 0x1073840ac: str x9, [x19, #0x18] 0x1073840b0: add x0, x19, #0x18 ; =0x18 0x1073840b4: bl 0x1073840b4 0x1073840b8: ldr x8, [x19, #0x10] 0x1073840bc: ldr x9, [x19, #0x18] 0x1073840c0: add w9, w8, w9 0x1073840c4: str x9, [x19, #0x10] 0x1073840c8: ldr x9, [x19, #0x10] 0x1073840cc: str x9, [x19] 0x1073840d0: b 0x1073840dc 0x1073840d4: ldr x9, [x19, #0x10] 0x1073840d8: str x9, [x19] 0x1073840dc: mov x0, #0x0 0x1073840e0: ldp x29, x30, [sp, #0x50] 0x1073840e4: ldp x20, x19, [sp, #0x40] 0x1073840e8: ldp x22, x21, [sp, #0x30] 0x1073840ec: ldp x24, x23, [sp, #0x20] 0x1073840f0: ldp x26, x25, [sp, #0x10] 0x1073840f4: ldp x28, x27, [sp], #0x60 0x1073840f8: ret
优化器
0x10268cfb8 <+0>: stp x20, x19, [sp, #-0x20]! 0x10268cfbc <+4>: stp x29, x30, [sp, #0x10] 0x10268cfc0 <+8>: add x29, sp, #0x10 0x10268cfc4 <+12>: mov x19, x0 0x10268cfc8 <+16>: cmp w0, #0x2 0x10268cfcc <+20>: b.hs 0x10268cfd8 0x10268cfd0 <+24>: mov w20, #0x0 0x10268cfd4 <+28>: b 0x10268cff4 0x10268cfd8 <+32>: mov w20, #0x0 0x10268cfdc <+36>: sub w0, w19, #0x1 0x10268cfe0 <+40>: bl 0x10268cfb8 0x10268cfe4 <+44>: sub w19, w19, #0x2 0x10268cfe8 <+48>: add w20, w0, w20 0x10268cfec <+52>: cmp w19, #0x1 0x10268cff0 <+56>: b.hi 0x10268cfdc 0x10268cff4 <+60>: add w0, w19, w20 0x10268cff8 <+64>: ldp x29, x30, [sp, #0x10] 0x10268cffc <+68>: ldp x20, x19, [sp], #0x20 0x10268d000 <+72>: ret
为了缩小差距,是时候做一些优化了。
1)优化器的主要流程

需要把方法体拆分为块的原因之一在于,优化器可能会删除或者增加代码,这样跳转指令的跳转目标地址就会发生改变,需要重新计算跳转目标,拆成块后跳转目标比较容易计算。
在块拆分及优化 pass 的实现中,会用到前面提到反汇编器和汇编器,这也是整个优化器的核心依赖。
我们以前文中的代码的一部分为例子,做优化流程的介绍,首先是块拆分:
; --- code block 0 --- 0x107384048: ldr x9, [x19, #0x8] 0x10738404c: cmp x9, #0x0 ; =0x0 -- 0x107384050: b.eq 0x107384068 ; b.eq 6| | ; --- code block 1 ---| 0x107384054: ldr x9, [x19]| 0x107384058: str x9, [x19, #0x8]| 0x10738405c: ldr x9, [x19, #0x8]| 0x107384060: str x9, [x19]| 0x107384064: b 0x1073840dc| | ; --- code block 2 --- -> 0x107384068: ldr x9, [x19] 0x10738406c: str x9, [x19, #0x10]
; --- code block 0 --- 0x104934020: cmp w9, #0x2 ; =0x2 -- 0x104934024: b.hs 0x104934038 ; b.hs 5| | ; --- code block 1 ---| 0x104934028: mov x9, x20| 0x10493402c: mov x21, x9| 0x104934030: mov x20, x9| 0x104934034: b 0x104934068|| ; --- code block 2 --- -> 0x104934038: sub w22, w20, #0x2 ; =0x2
0x104934020: cmp w9, #0x2 ; =0x2 0x104934024: b.hs 0x104934038 ; b.hs 5 0x104934028: mov x9, x20 0x10493402c: mov x21, x9 0x104934030: mov x20, x9 0x104934034: b 0x104934068 0x104934038: sub w22, w20, #0x2 ; =0x2
2)关键优化之寄存器分配
寄存器分配有一些较为成熟的方案,常用的包括:基于 live range 的线性扫描内存分配,基于 live internal 的线性扫描内存分配,基于图染色的内存分配等。在常见 jit 实现,会采用基于 live internal 的线性扫描内存分配方案,来做到产物性能和寄存器分配代码的时间复杂度的平衡。
为了实现的简单性,hyengine 使用了一种非主流的极简方案,基于代码访问次数的线性扫描内存分配,用人话说就是:给代码中出现次数最多的栈偏移分配寄存器。
0x107384020: ldr x9, [x19] 0x107384024: str x9, [x19, #0x8] 0x107384028: mov w9, #0x2 0x10738402c: str x9, [x19, #0x10] 0x107384030: mov x9, #0x1 0x107384034: ldr x10, [x19, #0x8] 0x107384038: ldr x11, [x19, #0x10]
0x107384020: ldr x9, [x19] ; 偏移0没变 0x107384024: mov x20, x9 ; 偏移8变成x20 0x107384028: mov w9, #0x2 0x10738402c: mov x21, x9 ; 偏移16变成x21 0x107384030: mov x9, #0x1 0x107384034: mov x10, x20 ; 偏移8变成x20 0x107384038: mov x11, x21 ; 偏移16变成x21
0x102db4000: stp x28, x27, [sp, #-0x60]! 0x102db4004: stp x26, x25, [sp, #0x10] 0x102db4008: stp x24, x23, [sp, #0x20] 0x102db400c: stp x22, x21, [sp, #0x30] 0x102db4010: stp x20, x19, [sp, #0x40] 0x102db4014: stp x29, x30, [sp, #0x50] 0x102db4018: add x29, sp, #0x50 ; =0x50 0x102db401c: mov x19, x0 0x102db4020: ldr x9, [x19] 0x102db4024: mov x20, x9 0x102db4028: mov x21, #0x2 0x102db402c: mov x9, #0x1 0x102db4030: cmp w20, w21 0x102db4034: csel x9, x9, xzr, lo 0x102db4038: mov x20, x9 0x102db403c: cmp x9, #0x0 ; =0x0 0x102db4040: b.eq 0x102db4054 0x102db4044: ldr x9, [x19] 0x102db4048: mov x20, x9 0x102db404c: str x20, [x19] 0x102db4050: b 0x102db40ac 0x102db4054: ldr x9, [x19] 0x102db4058: mov x21, x9 0x102db405c: mov x22, #0x2 0x102db4060: sub w9, w21, w22 0x102db4064: mov x21, x9 0x102db4068: add x0, x19, #0x10 ; =0x10 0x102db406c: str x21, [x19, #0x10] 0x102db4070: bl 0x102db4070 0x102db4074: ldr x21, [x19, #0x10] 0x102db4078: ldr x9, [x19] 0x102db407c: mov x22, x9 0x102db4080: mov x23, #0x1 0x102db4084: sub w9, w22, w23 0x102db4088: mov x22, x9 0x102db408c: add x0, x19, #0x18 ; =0x18 0x102db4090: str x22, [x19, #0x18] 0x102db4094: bl 0x102db4094 0x102db4098: ldr x22, [x19, #0x18] 0x102db409c: add w9, w21, w22 0x102db40a0: mov x21, x9 0x102db40a4: str x21, [x19] 0x102db40a8: nop 0x102db40ac: mov x0, #0x0 0x102db40b0: ldp x29, x30, [sp, #0x50] 0x102db40b4: ldp x20, x19, [sp, #0x40] 0x102db40b8: ldp x22, x21, [sp, #0x30] 0x102db40bc: ldp x24, x23, [sp, #0x20] 0x102db40c0: ldp x26, x25, [sp, #0x10] 0x102db40c4: ldp x28, x27, [sp], #0x60 0x102db40c8: ret
3)关键优化之寄存器参数传递
0x102db4068: add x0, x19, #0x10 ; =0x10 0x102db406c: str x21, [x19, #0x10] 0x102db4070: bl 0x102db4070 0x102db4074: ldr x21, [x19, #0x10]
这里把 wasm 的栈作为放入 x0 , 第一个参数 x2 2直接放入 x1 ,方法调用后的返回值 x0 直接放入 x22 ,优化后代码如下:
0x1057e405c: add x0, x19, #0x10 ; =0x10 0x1057e4060: mov x1, x22 0x1057e4064: bl 0x1057e4064 0x1057e4068: mov x22, x0
同时将方法头部取参数的代码从:
0x102db4020: ldr x9, [x19] 0x102db4024: mov x20, x9
0x1057e4020: mov x20, x1
优化后最终完整的代码如下:
0x1057e4000: stp x28, x27, [sp, #-0x60]! 0x1057e4004: stp x26, x25, [sp, #0x10] 0x1057e4008: stp x24, x23, [sp, #0x20] 0x1057e400c: stp x22, x21, [sp, #0x30] 0x1057e4010: stp x20, x19, [sp, #0x40] 0x1057e4014: stp x29, x30, [sp, #0x50] 0x1057e4018: add x29, sp, #0x50 ; =0x50 0x1057e401c: mov x19, x0 0x1057e4020: mov x20, x1 0x1057e4024: mov x21, x20 0x1057e4028: mov x22, #0x2 0x1057e402c: mov x9, #0x1 0x1057e4030: cmp w21, w22 0x1057e4034: csel x9, x9, xzr, lo 0x1057e4038: mov x21, x9 0x1057e403c: cmp x9, #0x0 ; =0x0 0x1057e4040: b.eq 0x1057e404c 0x1057e4044: mov x21, x20 0x1057e4048: b 0x1057e409c 0x1057e404c: mov x22, x20 0x1057e4050: mov x23, #0x2 0x1057e4054: sub w9, w22, w23 0x1057e4058: mov x22, x9 0x1057e405c: add x0, x19, #0x10 ; =0x10 0x1057e4060: mov x1, x22 0x1057e4064: bl 0x1057e4064 0x1057e4068: mov x22, x0 0x1057e406c: mov x23, x20 0x1057e4070: mov x24, #0x1 0x1057e4074: sub w9, w23, w24 0x1057e4078: mov x23, x9 0x1057e407c: add x0, x19, #0x18 ; =0x18 0x1057e4080: mov x1, x23 0x1057e4084: bl 0x1057e4084 0x1057e4088: mov x23, x0 0x1057e408c: add w9, w22, w23 0x1057e4090: mov x22, x9 0x1057e4094: mov x20, x22 0x1057e4098: nop 0x1057e409c: mov x0, x20 0x1057e40a0: ldp x29, x30, [sp, #0x50] 0x1057e40a4: ldp x20, x19, [sp, #0x40] 0x1057e40a8: ldp x22, x21, [sp, #0x30] 0x1057e40ac: ldp x24, x23, [sp, #0x20] 0x1057e40b0: ldp x26, x25, [sp, #0x10] 0x1057e40b4: ldp x28, x27, [sp], #0x60 0x1057e40b8: ret
注:这个优化仅对方法体比较短且调用频繁的方法有显著跳过,方法体比较长的代码效果不明显。
4)关键优化之特征匹配
比如上面代码中的:
0x1057e404c: mov x22, x20 0x1057e4050: mov x23, #0x2 0x1057e4054: sub w9, w22, w23 0x1057e4058: mov x22, x9
0x104934038: sub w22, w20, #0x2 ; =0x2
5)优化结果
0x104934000: stp x24, x23, [sp, #-0x40]! 0x104934004: stp x22, x21, [sp, #0x10] 0x104934008: stp x20, x19, [sp, #0x20] 0x10493400c: stp x29, x30, [sp, #0x30] 0x104934010: add x29, sp, #0x30 ; =0x30 0x104934014: mov x19, x0 0x104934018: mov x20, x1 0x10493401c: mov x9, x20 0x104934020: cmp w9, #0x2 ; =0x2 0x104934024: b.hs 0x104934038 0x104934028: mov x9, x20 0x10493402c: mov x21, x9 0x104934030: mov x20, x9 0x104934034: b 0x104934068 0x104934038: sub w22, w20, #0x2 ; =0x2 0x10493403c: add x0, x19, #0x10 ; =0x10 0x104934040: mov x1, x22 0x104934044: bl 0x104934000 0x104934048: mov x22, x0 0x10493404c: sub w23, w20, #0x1 ; =0x1 0x104934050: add x0, x19, #0x18 ; =0x18 0x104934054: mov x1, x23 0x104934058: bl 0x104934000 0x10493405c: add w9, w22, w0 0x104934060: mov x22, x9 0x104934064: mov x20, x9 0x104934068: mov x0, x20 0x10493406c: ldp x29, x30, [sp, #0x30] 0x104934070: ldp x20, x19, [sp, #0x20] 0x104934074: ldp x22, x21, [sp, #0x10] 0x104934078: ldp x24, x23, [sp], #0x40 0x10493407c: ret
quickjs 编译
quickjs 的编译流程和 wasm 类似,只是对 opcode 的实现上会稍微复杂一些,以OP_object为例:
// *sp++ = JS_NewObject(ctx); // if (unlikely(JS_IsException(sp[-1]))) // goto exception;case OP_object: { MOV_FUNCTION_ADDRESS_TO_REG(R8, JS_NewObject); MOV_X_X(NEXT_INSTRUCTION, R0, CTX_REG); BLR_X(NEXT_INSTRUCTION, R8); STR_X_X_I(NEXT_INSTRUCTION, R0, R26, SP_OFFSET(0)); CHECK_EXCEPTION(R0, R9); break;}
#define MOV_FUNCTION_ADDRESS_TO_REG(reg, func) \{ \ uintptr_t func##Address = (uintptr_t)func; \ MOVZ_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address), LSL, 0); \ if (IMM16(func##Address >> 16) != 0) { \ MOVK_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address >> 16), \ LSL, 16); \ } else { \ NOP(NEXT_INSTRUCTION); \ } \ if (IMM16(func##Address >> 32) != 0) { \ MOVK_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address >> 32), \ LSL, 32); \ } else { \ NOP(NEXT_INSTRUCTION); \ } \ if (IMM16(func##Address >> 48) != 0) { \ MOVK_X_I_S_I(NEXT_INSTRUCTION, reg, IMM16(func##Address >> 48), \ LSL, 48); \ } else { \ NOP(NEXT_INSTRUCTION); \ } \ }
#define EXCEPTION(tmp) \ tmp, CTX_REG, HYJS_BUILTIN_OFFSET(0)); \ MOV_X_I(NEXT_INSTRUCTION, R0, SP_OFFSET(0)); \ BLR_X(NEXT_INSTRUCTION, tmp);
#define CHECK_EXCEPTION(reg, tmp) \ tmp, ((uint64_t)JS_TAG_EXCEPTION<<56)); \ CMP_X_X_S_I(NEXT_INSTRUCTION, reg, tmp, LSL, 0); \ B_C_L(NEXT_INSTRUCTION, NE, 4 * sizeof(uint32_t)); \ EXCEPTION(tmp)
同样是 fibonacci 的实现,wasm 的 jit 产物代码只有 32 条,而 quickjs 的有 467 条!!!又想起了被汇编所支配的恐惧。
注:这么指令源于对 builtin 的调用、引用计数、类型判断。后面 vm 优化将引用计数干掉后代码量减少到 420 条。
2 引擎(vm)部分
在之前对某业务js代码的性能分析后发现,超过 50% 的性能开销在内存分配及 gc 上,为此引擎部分将主要介绍对 quickjs 的内存分配和 gc 优化,部分 runtime 的 builtin 的快路径、inline cache 目前优化占比不高,仅做少量介绍。
内存分配器 hymalloc
1)实现简介
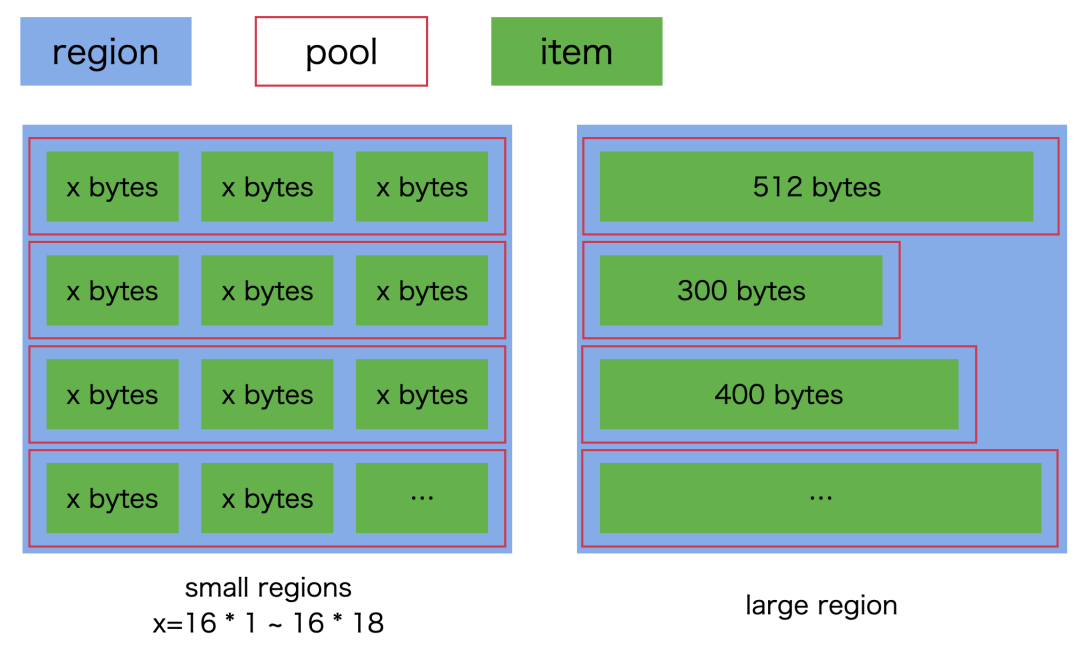
每个区可包含多个池(pool),每个池里面可包含多个目标大小的条目(item)。large region 比较特殊,每个 pool 里只有 1 个条目。在向系统申请内存时,按 pool 来做申请,之后再将 pool 拆分成对应的 item。
每个 small region 初始化有一个池,池的大小可配置,默认为 1024 个 item;large region 默认是空的。
区/块/池的示意图如下:
// hymalloc itemstruct HYMItem { union { HYMRegion* region; // set to region when allocated HYMItem* next; // set to next free item when freed }; size_t flags; uint8_t ptr[0];};
// hymalloc poolstruct HYMPool { HYMRegion *region; HYMPool *next; size_t item_size;};
region 的空闲 item 链表示意图如下:
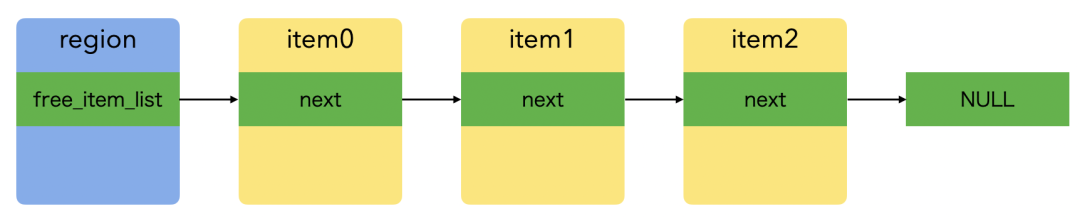
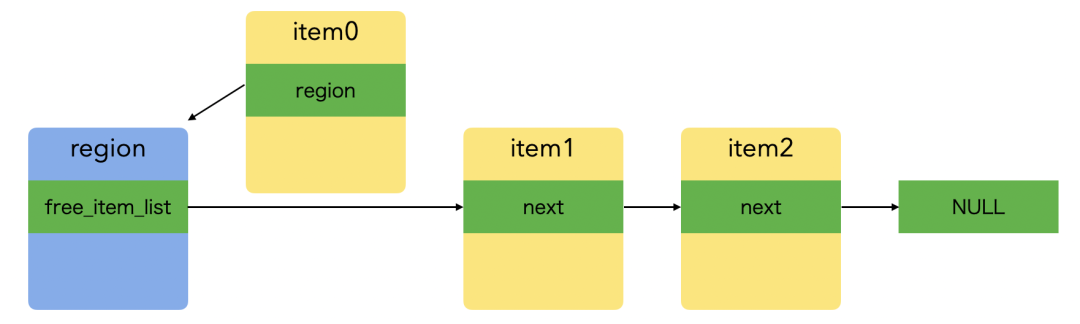
static void* _HYMallocFixedSize(HYMRegion *region, size_t size) { // allocate new pool, if no free item exists if (region->free_item_list == NULL) { // notice: large region's item size is 0, use 'size' instead size_t item_size = region->item_size ? region->item_size : size; int ret = _HYMAllocPool(region, region->pool_initial_item_count, item_size); if (!ret) { return NULL; } } // get free list item head, and set region to item's region HYMItem *item = region->free_item_list; region->free_item_list = item->next; item->region = region; item->flags = 0; return &item->ptr;}
void HYMFree(void *ptr) { HYMItem *item = (HYMItem *)((uint8_t *)ptr - HYM_ITEM_SIZE_OVERHEAD); // set item as head of region's free item list HYMRegion *region = item->region; HYMItem *first_item_in_region = region->free_item_list; region->free_item_list = item; item->next = first_item_in_region;
}
2)内存 compact + update
但从客户端的使用场景来看,运行代码的内存用量本身不高,compact + update 完整组合的实现复杂度较高,性价比不足。后续根据实际业务的使用情况,再评估实现完整 compact + update 的必要性。
3)hymalloc 的局限性
而且虽然 hymalloc 提供了 compact 方法来释放空闲的内存,但由于按照 pool 来批量申请内存,只要 pool 中有一个 item 被使用,那么这个 pool 就不会被释放,导致内存不能被完全高效的释放。
另外,考虑到内存被复用的概率,large region 的内存会默认按 256bytes 对齐来申请,同样可能存在浪费。
上述问题可以通过设定更小的 pool 的默认 item 数量,及更小的对齐尺寸,牺牲少量性能,来减少内存浪费。
后续可以引入更合理的数据结构,以及更完善的 compact + update 机制,来减少内存浪费。
垃圾回收器 hygc
为了实现 hyengine 对 quickjs 性能优化,减少 gc 在整体耗时种的占比,减少 gc 可能导致的长时间运行停止。参考 v8 等其他先进引擎的 gc 设计思路,实现一套适用于移动端业务的,轻量级、高性能、实现简单的 gc。
注:本实现仅仅针对于 quickjs,后续可能会衍生出通用的 gc 实现。
注:为了保障业务体验不出现卡顿,需要将 gc 的暂停时间控制在 30ms 内。
1)常用垃圾回收实现
-
引用计数
-
给每个对象加一个引用数量,多一个引用数量 +1,少一个引用数量 -1,如果引用数量为 0 则释放。 -
-
弊端:无法解决循环引用问题。 -
-
mark sweep
-
遍历对象,标记对象是否有引用,如果没有请用则清理掉。 -
-
拷贝 gc
-
遍历对象,标记对象是否有引用,把有引用的对象拷贝一份新的,丢弃所有老的内存。
-
三色标记 gc
-
遍历对象,标记对象是否有引用,状态比单纯的有引用(黑色)和无引用(白色)多一个中间状态标记中/不确定(灰色),可支持多线程。
2)hygc 的业务策略
-
无 gc
-
运行期不触发 gc 操作。 -
-
待代码完全运行完毕销毁 runtime 时做一次 full gc 整体释放内存。 -
-
闲时 gc
-
运行期不触发 gc 操作,运行结束后在异步线程做 gc。 -
-
代码完全运行完毕销毁 runtime 时做一次 full gc 整体释放内存。 -
-
默认 gc
-
运行期会触发 gc。 -
-
代码完全运行完毕销毁 runtime 时做一次 full gc 整体释放内存。
3)hygc 的实现方案
hygc 的三色标记流程(单线程版本):


注:令人悲伤的是,由于 mark 和垃圾回收仍然只在单独一个线程完成,这里只用到了两种颜色做标记,灰色实际上没用到。后续优化让 hygc 实现和 quickjs 原本的 gc 能够共存,让 gc 的迁移风险更低。
4)hygc 的局限性
此问题后续也将根据实际情况,判断是否进行方案优化来解决。
其他优化举例
1)global 对象的 inline cache
global inline cache 的数据结构如下:
typedef struct { JSAtom prop; // property atom int offset; // cached property offset void *obj; // global_obj or global_var_obj} HYJSGlobalIC;
具体代码实现如下:
case OP_get_var: { // 73 JSAtom atom = get_u32(buf + i + 1); uint32_t cache_index = hyjs_GetGlobalICOffset(ctx, atom); JSObject obj; JSShape shape;
LDR_X_X_I(NEXT_INSTRUCTION, R8, CTX_REG, (int32_t)((uintptr_t)&ctx->global_ic - (uintptr_t)ctx)); ADD_X_X_I(NEXT_INSTRUCTION, R8, R8, cache_index * sizeof(HYJSGlobalIC)); LDP_X_X_X_I(NEXT_INSTRUCTION, R0, R9, R8, 0); CBZ_X_L(NEXT_INSTRUCTION, R9, 12 * sizeof(uint32_t)); // check cache exsits LSR_X_X_I(NEXT_INSTRUCTION, R1, R0, 32); // get offset LDR_X_X_I(NEXT_INSTRUCTION, R2, R9, (int32_t)((uintptr_t)&obj.shape - (uintptr_t)&obj)); // get shape ADD_X_X_I(NEXT_INSTRUCTION, R2, R2, (int32_t)((uintptr_t)&shape.prop - (uintptr_t)&shape)); // get prop LDR_X_X_W_E_I(NEXT_INSTRUCTION, R3, R2, R1, UXTW, 3); // get prop LSR_X_X_I(NEXT_INSTRUCTION, R3, R3, 32); CMP_W_W_S_I(NEXT_INSTRUCTION, R0, R3, LSL, 0); B_C_L(NEXT_INSTRUCTION, NE, 5 * sizeof(uint32_t)); LDR_X_X_I(NEXT_INSTRUCTION, R2, R9, (int32_t)((uintptr_t)&obj.prop - (uintptr_t)&obj)); // get prop LSL_W_W_I(NEXT_INSTRUCTION, R1, R1, 4); // R1 * sizeof(JSProperty) LDR_X_X_W_E_I(NEXT_INSTRUCTION, R0, R2, R1, UXTW, 0); // get value B_L(NEXT_INSTRUCTION, 17 * sizeof(uint32_t));
MOV_FUNCTION_ADDRESS_TO_REG(R8, HYJS_GetGlobalVar); MOV_X_X(NEXT_INSTRUCTION, R0, CTX_REG); MOV_IMM32_TO_REG(R1, atom); MOV_X_I(NEXT_INSTRUCTION, R2, opcode - OP_get_var_undef); MOV_X_I(NEXT_INSTRUCTION, R3, cache_index); BLR_X(NEXT_INSTRUCTION, R8);
CHECK_EXCEPTION(R0, R9);
STR_X_X_I(NEXT_INSTRUCTION, R0, R26, SP_OFFSET(0)); i += 4; break;}
2)builtin 的快路径优化
以 Array.indexOf 的实现为例:
static JSValue hyjs_array_indexOf(JSContext *ctx, JSValueConst func_obj, JSValueConst obj, int argc, JSValueConst *argv, int flags){ ......
res = -1; if (len > 0) {
...... fast path if (JS_VALUE_GET_TAG(element) == JS_TAG_INT) { for (; n < count; n++) { if (JS_VALUE_GET_PTR(arrp[n]) == JS_VALUE_GET_PTR(element)) { res = n; goto done; } } goto property_path; } slow path for (; n < count; n++) { if (js_strict_eq2(ctx, JS_DupValue(ctx, argv[0]), arrp[n]), JS_EQ_STRICT)) { res = n; goto done;e } } ...... } done: return JS_NewInt64(ctx, res);
exception: return JS_EXCEPTION;}
四 优化结果
1 wasm 性能
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注:coremark hyengine jit 耗时是 llvm 编译版本的约 3 倍,原因在于对计算指令优化不足,后续可在优化器中对更多计算指令进行优化。
注:上述测试编译优化选项为 O3。
2 js性能
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注:从业务 case 上可以看出,vm 优化所带来的提升远大于目前 jit 带来的提升,原因在于 jit 目前引入的优化方式较少,仍有大量的优化空间。另外 case 1 在 v8 上,jit 比 jitless 带来的提升也只有 30% 左右。在 jit 的实现中,单项的优化单来可能带来的提升只有 1% 不到,需要堆几十上百个不同的优化,来让性能做到比如 30% 的提升,后续会更具性能需求及开发成本来做均衡选择。
五 后续计划
后续计划主要分为 2 个方向:性能优化、多语言支持,其中性能优化将会持续进行。
性能优化点包括:
-
编译器优化,引入自有字节码支持。 -
优化器优化,引入更多优化pass。 -
自有 runtime,热点方法汇编实现。
六 参考内容
-
wasm3: https://github.com/wasm3/wasm3 -
quickjs: https://bellard.org/quickjs/
-
v8: https://chromium.googlesource.com/v8/v8.git -
javascriptcore: https://opensource.apple.com/tarballs/JavaScriptCore/
-
golang/arch: https://github.com/golang/arch -
libmalloc: https://opensource.apple.com/tarballs/libmalloc/
-
Trash talk: the Orinoco garbage collector: https://v8.dev/blog/trash-talk -
JavaScript engine fundamentals: Shapes and Inline Caches:https://mathiasbynens.be/notes/shapes-ics
-
cs143: https://web.stanford.edu/class/cs143/ -
C in ASM(ARM64):https://www.zhihu.com/column/c_142064221
热烈欢迎志同道合之士加入我们,联系邮箱:zhibing.lwh#alibaba-inc.com(发送邮件时,请把#替换成@)
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月5日
相关主题


相关VIP内容
相关资讯