学习 | Word2Vec的迁移实践:Tag2Vec
编辑:菜鸟的机器学习
作者:段石石
链接:cloud.tencent.com/developer/article/1006090
前言
互联网中,对于一个内容实体建模,如新闻、商品等,通常有两个方向:第一、content-based,如该文章类别、文章标题、关键字、作者、新闻字数等等信息,这些属于从内容上描述文章信息;第二、action-based,即从用户与内容之间的各种不同行为来建模用户的关系。
今天我们就来重点关注下基于用户行为的内容表示的一些有意思的东西。
协同过滤
协同过滤相信很多做推荐的人经常接触的一个算法,是一个经典的集体智慧的算法:在大量的人群行为数据中收集信息,得到大部分人群的统计结论来表示人群中的某种趋势,或者我们称为共性的部分。
为帮助理解,这里简单举几个例子:比如我等屌丝程序员,大部分会是下面这种情况:
除了程序员的装扮,程序员的timeline很多时候也是下面这个特点:

特点人群,会更大几率对他相关或者有兴趣的内容产生行为。同理,转换下用户和内容的彼此身份,如果某个内容,被相似的人群产生行为是否能够说明这些内容有一些实体会引起这一类人群的兴趣,这就是action-based的假设前提,action-based和content-based属于一个硬币的两面,应该综合考虑才能算是比较合理的某个内容实体的表征方式。

很显然一些公共的信息如一个出生湖北武汉、年纪29岁的未婚女演员,并不能表征她是刘亦菲,但是如果加上她的action信息,她参演过功夫之王、铜雀台、四大名捕等等,那就八九不离十了。
基于用户的协同过滤
一句话描述基于用户的协同过滤,就是找到和目标用户最相似的用户,然后把该用户产国的物品,收集为候选列表,过滤掉已产生行为的物品,并考虑用户相似度为权重,进行加权排序。大体如下所示:
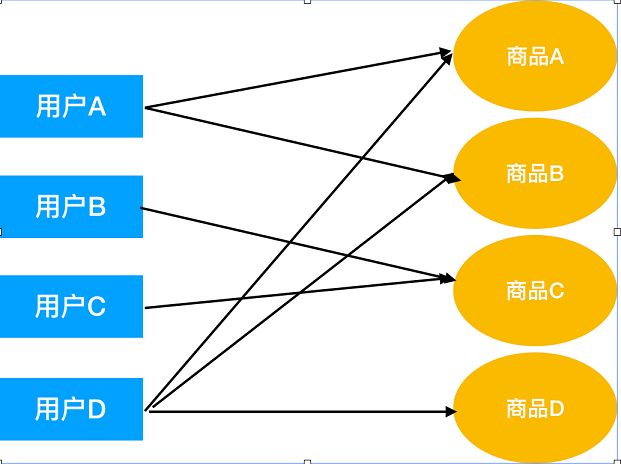
对用户A进行推荐,因为与用户行为相速度较大[1,1,0,0]与[1,1,0,1],其相似度为sim(A,D),B、C用户[0,0,1,0],其相似度为sim(B, C),其值为0,所以最终对用户A的推荐为商品D。
基于Item的协同过滤
一句话描述基于Item的协同过滤就是计算Item的相似度,然后推荐用户已购买的商品相似度比较大的物品。
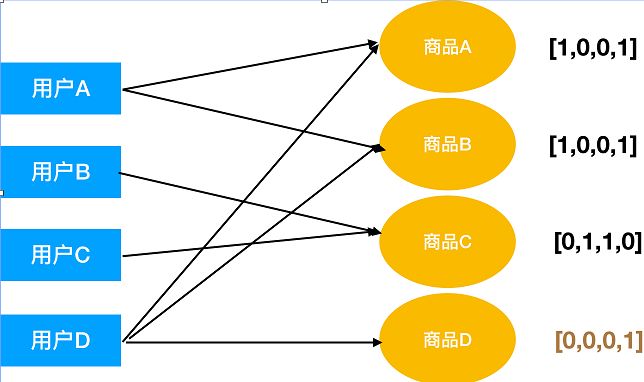
很明显商品D与商品A和商品B的相似度都比较高,过滤掉已产生行为商品,对用户A推荐商品D。
基于模型的协同过滤
基于模型的协同过滤方法,大体是用模型来替代比较粗糙的相似度计算方式,这里描述下比较经典的Matrix Factorization,前面基于用户和Item的方法在实际场景中会出现数据稀疏、计算复杂的问题,MF是一个比较好的方法,采用了矩阵分解的思路,将原始的用户对Item的行为矩阵转换为两个dense矩阵用来表示用户、Item的隐向量表示,然后在隐向量空间来度量用户或者Item的相似度。
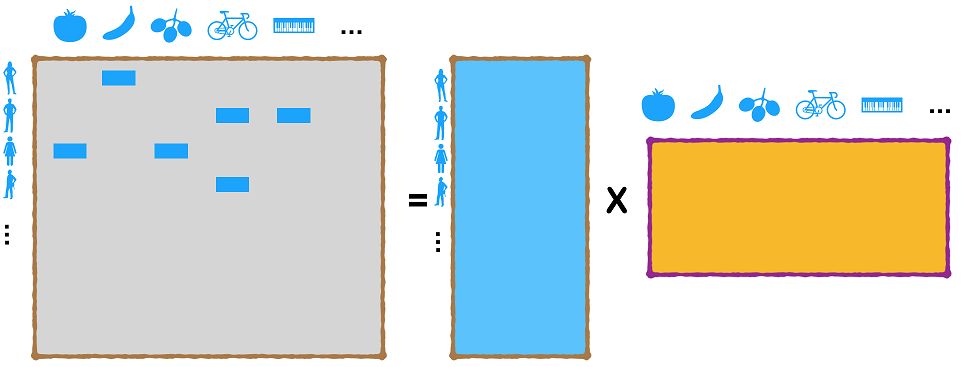
等号左边的矩阵记录了不同用户对不同商品的行为分布,通常在实际的系统中,矩阵很大,而且通常十分稀疏,MF方法就是将这个矩阵分解为两个比较小的矩阵,分别为用户和Item的隐向量矩阵,然后利用这些隐形量矩阵计算用户对Item的偏好分数,或者计算Item与Item或者用户与用户之间的相似性,在不同场景下来进行各种需求的计算。
利用Word2Vec建模共现关系
前面提到了使用协同过滤来建模,得到action_based的方式,那么是否有其他的方法呢? 回归到数据来源,用户对各种不同的行为如果组成一个有一个的序列,如果我能建模序列内,元素之间的相似度,是不是就能很好的表征这些元素。好吧,大家可能发现了,这tm不就是Word2Vec吗?每个序列不就是Word2Vec的语料语句吗?是的,就是这样, 其实说了前面许多,什么协同过滤,Matrix Factorization,就是想引出这个,使用Word2Vec来建模Action数据,下面我将详细描述,我是怎么在实际数据中做这些尝试的。
Word2Vec原理
Word2Vec的原理,有很多文章都讲过了,这里就不详细描述了,想进一步了解的可以去Google一下, 这里一句话解释下:利用cbow或skip-gram收集窗口上下文信息,来建模词与词之间的共现关系。
Tag2Vec尝试
用于阅读资讯相关内容,通常在一个有效时间内,如一个session,所有文章会形成一个文章序列,通常文章与Tag词的映射,(何为Tag?如黄忠垃圾?)
这盘《王者荣耀》竟打了195分钟,手机充三次电!这篇文章可能就会提取到王者荣耀这个Tag词),形成Tag词的序列,收集到有效用户的所有行为,即可拿到所有Tag词的序列,这个序列中包含了用户在阅读比如Tag词为王者荣耀后,更可能去阅读王者荣耀英雄的数据如李白、诸葛亮的文章内容,也就是说在一个序列内,其共现概率应该比较高,那么其向量化后的相似度也应该更大,这个是content-based可能需要话很大力气才能建模的。OK,话不多说,我们用实际数据实验一下。
数据收集
一个Session数据的收集理论上应该包括Tag词序列,还有先后关系,才能比较合理的建模一个可用的Tag2Vec模型,但是,数据收集难度问题。
我们这里使用的是用户每天在Tag词上的行为序列,也没考虑Tag词的先后,所以这里其实有一个风险,可能达不到我们预先想要的类似Word2Vec的结果,因为Word2Vec理论上是有一个window size限制,然后窗口了上下文来和中间词做一个推断,其实质是一个分类问题(正样本为中间词,负样本为窗口外词), 所以其实这里如果没有时间先后,还有窗口太大为天,本身在模型上是有风险的,但是,又稍微一想,其实语义的依赖关系本身就也有可能不在windows size内,随机性的顺序,丢失的信息应该不多,考虑了很多,和小伙伴也讨论,感觉问题不大,直接先上看看,最后的数据如下:
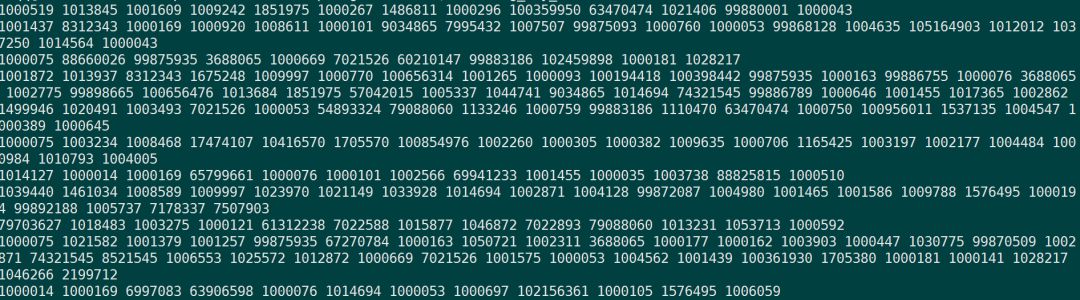
需要说明的是:这里的数据做过基本的去脏处理,包括设置阈值、排除行为过少的用户,大概能拿到500w+的数据。
模型训练
利用开源工具Gensim实现Word2Vec很容易,只需要几行就可以完成:

Tag2Vec结果
这里对Tag2Vec做一些展示:

以下是一些例子,感觉还是蛮有意思的:

如王者荣耀,相似度最高的是天美工作室, 然后就是很多相关的英雄以及一些主播信息,还有一些有意思的如宋喆、车晓、张静初、郑则仕,这类看起来相关性不大的实体,应该是因为看王者荣耀的小伙伴们更偏向于娱乐化的新闻,因此更优可能露出车晓、张静初、宋喆这些娱乐圈人物。
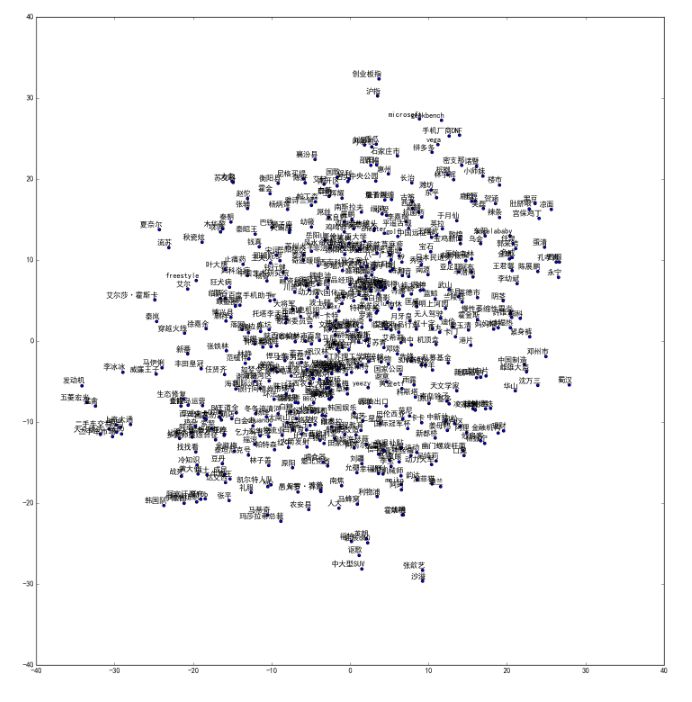
500个Tag的t-sne分布:
Tag2Vec如何使用?
Tag2Vec产生的向量表示,原则上可以用来表征Tag词,由于数据来源于Action,可以加上Content-based的数据,然后放在诸如CTR模型,在文章点击率预估,又或者模型的部分Feature,提升模型准确性;还可以在一些相关文章推荐时,通过Tag2Vec来找出其他相关的Tag,推荐这些Tag的文章;甚至可以和word2vec相同的用法,作为embedding的一种初始化表示,在任务中retrain这些参数。






