Kaggle前1%参赛者经验:ML竞赛中常被忽视的特征工程技术
创造力一直是人类进化的本质。数千年来,人类已经在历史长河中发掘了不少奇妙发现,而这种行为的起源契机可能是第一个轮子开始滚动,或是某个疯狂想法背后的思维火花崩现。从石器时代到今天,创造力始终倍受赞赏,而它也确实也给我们带来了源源不断的进步动力。
现如今,各个领域正在丰富创造力的内涵,其中,数据科学应该是最欢迎它的领域之一:从零假设、数据预处理、构建模型——创造性洞察力在其中发挥着重要作用。

摄影:Franki Chamaki
一位Kaggle大师曾对我说:
你解决问题的次数越多,你对某些想法、挑战的理解就越深,你会发现某些东西对于特定问题会有奇效。
放在竞赛实践中,这种经验在特征工程上表现得尤为明显。所谓特征工程,指的就是从数据中抽取包含大量信息的特征,方便模型易于学习的过程。
为什么特征工程如此重要?
现在数据科学的许多初学者都“迷信”LGBM和XGBoost,因为它们的效果确实好,准确率很高。相应的,传统的线性回归和KNN开始淡出人们的视野。
但在某些情况下,线性回归的效果其实不一定比GBM树差,甚至有时还更好。以我个人的经历为例,线性回归模型在曾在不少竞赛中帮助我取得优势。
统计学家乔治·博克有一句话,被不少统计学从业者奉为圭臬:
所有的模型都是错误的,但其中有些是有用的。
这意味着模型只有在发现某些和目标变量有重大关系的特征时,它才是强大的。而这就是特征工程发挥作用的地方——我们设计、创建新特征,以便模型从中提取重要相关性。
之前我参加过DataHack的一个竞赛,内容是用数据集预测电力消耗。通过热图和探索性数据分析,我绘制了以下这幅图:
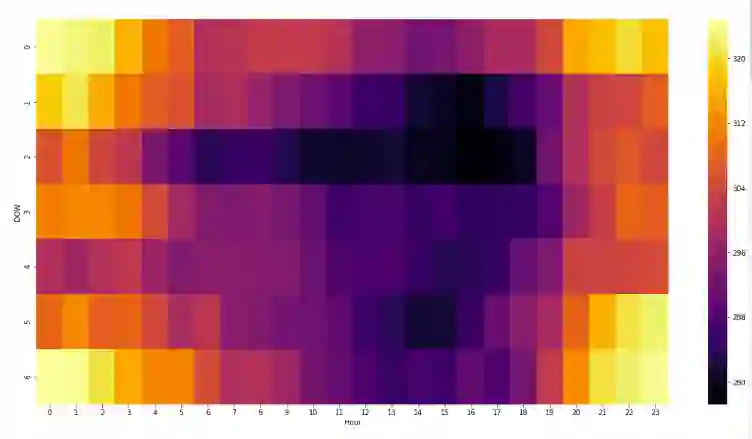
热图的纵坐标DOW表示一周7天,横坐标则是一天24小时。很明显,周末整天的用电情况和工作日深夜的用电情况十分类似。由此,我创建了一个特征——weekend proximity,它不仅提高了模型得分,还帮我最终赢得了比赛。
因此,在机器学习竞赛中善用创造力十分重要,下面是几个大家都知道但不常用的特征工程技巧,其中部分还有些旁门左道:
把数据转换成图像
Meta-leaks
表征学习特征
均值编码
转换目标变量
把数据转换成图像
Kaggle上有一个微软恶意软件分类挑战,它的数据集包含一组已知的恶意软件文件,对于每个文件,原始数据包含文件二进制内容的十六进制表示。此前,参赛者在网上从没接触过类似的数据集,而他们的目标是开发最优分类算法,把测试集中的文件放到各自所属的类别中。
比赛进行到最后,“say NOOOOO to overfittttting”赢得了第一名,他们的制胜法宝是把原始数据的图像表示作为特征。
我们把恶意文件的字节文档看成黑白图像,其中每个字节的像素强度在0-255之间。然而,标准图像处理技术与n-gram等其他特征不兼容。所以之后,我们从asm文件而不是字节文件中提取黑白图像。
下图是同一恶意软件的字节图像、asm图像对比:

字节图像(左)asm图像(右)
asm文件是用汇编语言写成的源程序文件。这个团队发现把asm文件转成图像后,图像的前800-1000个像素的像素强度可以作为分类恶意软件的一个可靠特征。
虽然他们表示并不知道为什么这么做会奏效,因为单独使用这个特征并不会给分类器性能带来明显变化,但当它和其他n-gram特征一起使用时,性能提升效果就很显著了。
把原始数据转换成图像,并把像素作为特征。这是Kaggle竞赛中出现的令人惊叹的特征工程之一。
元数据泄露
当处理过的特征在没有应用任何机器学习的情况下,可以非常完美地解释目标时,这可能发生了数据泄露。
最近Kaggle上的一个竞赛——桑坦德客户价值预测挑战赛发生了数据泄露,参赛者只需对行和列的序列做蛮力搜索,最终就能很好地解释目标。
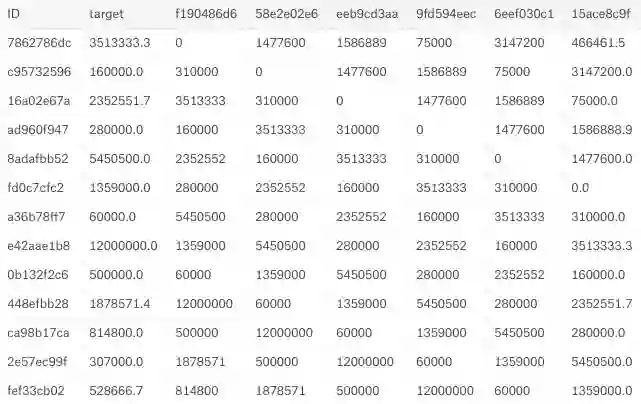
桑坦德的数据泄露
如上图所示,目标变量明显泄漏到了f190486列中。事实上,我没有用任何机器学习就得到了0.57分,这在排行榜上是个高分。在竞赛截止日期前二十天左右,主持竞赛的桑坦德银行终于发现了这个问题,但他们最终还是决定继续比赛,让参赛者假设这是一个数据属性。
虽然这种错误非常罕见,但如果只是想在竞赛中取得好排名,你可以在一开始从文件名、图像元数据以及序号等特征中尝试提取模式。请注意,这种做法本身对实际的数据科学问题没有作用。
比起在IDA和其它特征上花费大量时间,如果你真的每次都认真做探索性数据分析了(EDA),你可能会因此发现竞赛“捷径”。
表征学习特征
对于资历较老的数据科学参赛者,他们对基础特征工程技巧肯定十分熟悉,比如Label Encoding、one-hot编码、Binning等等。然而,这些方法非常普通,现在每个人都知道它们该怎么用。
为了从人群中脱颖而出,为了在排行榜上占据更高的名次,我们需要发掘一些聪明的方法,比如自编码器。自编码器能从数据样本中进行无监督学习,这意味着算法直接从训练数据中捕捉最显著的特征,无需其他特征工程。
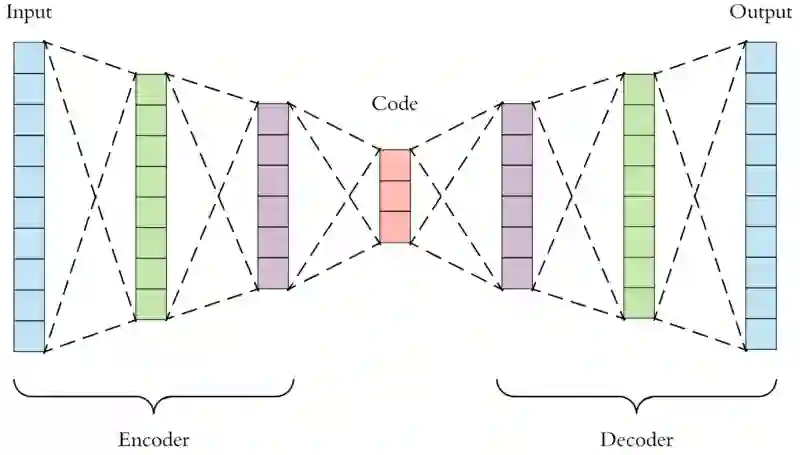
自编码器
自编码器只是给定一个表征学习模型,它学习输入,然后生成输入本身。 例:这就像给一个人看一张关于猫的图像,然后要求他在一段时间后画出自己看到的那只猫。
直觉是学习过程中提取到的最佳观察特征。在上面这个例子中,人类肯定会画两只眼睛、三角形的耳朵和胡须。然后后面的模型会把这些直觉作为分类的重要依据。
均值编码
均值编码其实还是很常见的,这是一种非常适合初学者的技巧,能在解决问题的同时提供更高的准确性。如果我们用训练数据中的目标值替换分类值,这叫Target Encoding;如果我们用平均数这样的统计量度来对分类值进行编码,这就叫均值编码(Mean Encoding)。
下面是一个示例,我们需要基于每类目标变量的value_counts,通过标签数量、目标变量编码标签。
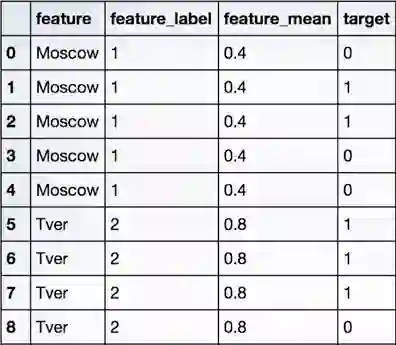
其中,featurelabel是scikit-learn编码的标签,featuremean就是莫斯科标签下的真实目标数量/莫斯科标签下的目标总数,也就是2/5=0.4。
同理,对于Tver标签——
m=Tver标签下的真实目标数量=3
n=Tver标签下的目标总数=4
相应的,Tver编码就是m/n=3/4=0.75(约等于0.8)
问:为什么均值编码优于其他编码方法? 答:如果数据具有高基数类别属性,那么相比其他编码方法,均值编码是更简单高效的一种方案。
数据分析中经常会遇到类别属性,比如日期、性别、街区编号、IP地址等。绝大部分数据分析算法是无法直接处理这类变量的,需要先把它们先处理成数值型量。如果这些变量的可能值很少,我们可以用常规的one-hot编码和label encoding。
但是,如果这些变量的可能值很多,也就是高基数,那么在这种情况下,使用label encoding会出现一系列连续数字(基数范围内),在特征中添加噪声标签和编码会导致精度不佳。而如果使用的是one-hot编码,随着特征不断增加,数据集的维数也在不断增加,这会阻碍编码。
因此,这时均值编码是最好的选择之一。但它也有缺点,就是容易过拟合和导致数据泄露,所以使用时要配合适当的正则化技术。
用CV loop工具进行正则化
Regularization Smoothing
Regularization Expanding mean
转换目标变量
严格意义上来说,这不属于特征工程。但是,当我们拿到一个高度偏斜的数据时,如果我们不做任何处理,最后模型的性能肯定会受影响。

目标分布
如上图所示,这里的数据高度偏斜,如果我们把目标变量转成log(1+目标)格式,那么它的分布就接近高斯分布了。
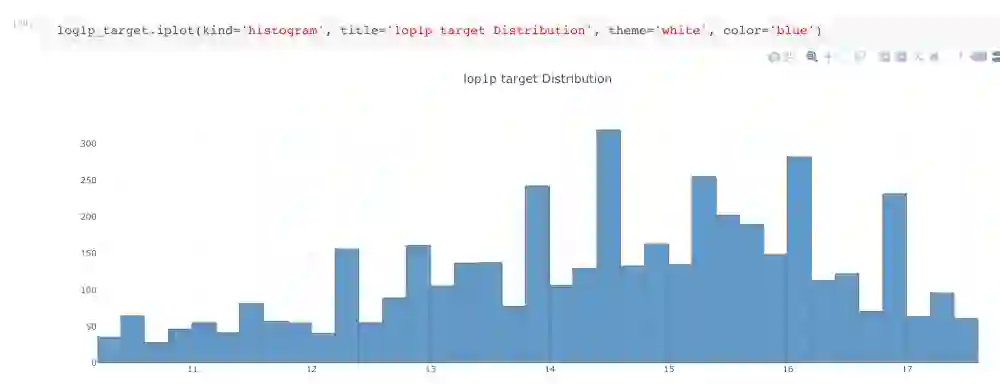
需要注意的是,提交预测值时,我们需要进行转换:predictions = np.exmp1(log_predictions)。
以上就是我的经验,希望本文对你有帮助!
原文地址:medium.com/ml-byte/rare-feature-engineering-techniques-for-machine-learning-competitions-de36c7bb418f






