连载▍AlexNet结构详解(引用MrGiovanni博士)

接昨日《连载▍AlexNet网络结构模型论文翻译——中文版》。今天是第二篇。
说来惭愧,看了深度学习快五个月了,前几周的Paper Review上刚刚注意到AlexNet,那果断用啊,话说LeNet虽然好用,那也是快20年以前的网络结构了,AlexNet是2012年的结构,不管怎么说肯定好呀。贴一张网络结构的历史。

这个AlexNet就是我今天要讲的东西
说正经的。AlexNet是2012年ImageNet竞赛冠军获得者Alex Krizhevsky设计的,这个网络结构和LeNet有什么区别呢?

套路是一样的,先介绍一下深度学习的卷积神经网络(ConvNet)的组成吧。
这个不多说,学过信号的都大概知道卷积是个什么玩意儿,不懂的话可以参考额。。。别参考了,好好学基础知识去吧~要说明的一点是这个卷积的过程很好地模拟了人的视觉神经系统的过程,听老师说人眼看东西也就是一个卷积的过程哦,这个我可不能保证哦。
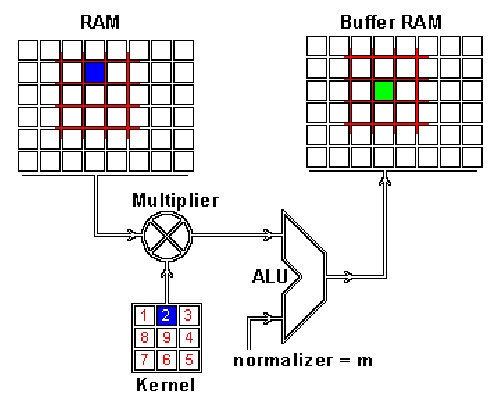
卷积的动态过程
降采样就是用一个值来代替一块区域,这个值可以是区域的平均值,最大值,最小值等等,反正有代表性就好了,这个层的目的就是减少数据量。
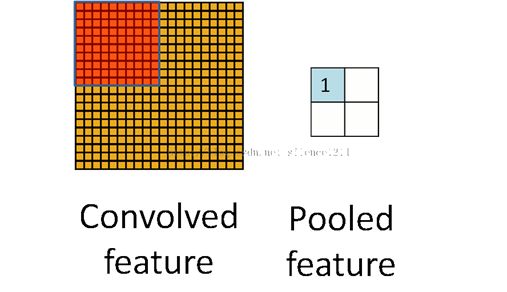
降采样过程
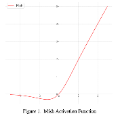
激活函数的作用是把卷积后的结果压缩到某一个固定的范围,这样可以一直保持一层一层下去的数值范围是可控的。比如一些常见的激活函数
sigmoid:控制在[0, 1]
tanh:控制在[-1, 1]
ReLU:控制在[0, 正无穷]
还有好多新的激活函数,这儿就不举例了,知道它们的作用就OK。
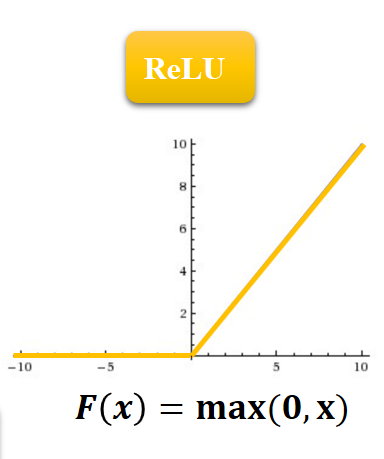
我用的是ReLU激活函数

没什么大不了的,就用了个公式来标准化一下
全连接层给人的感觉就是人工神经网络的那样,把所有的网络结点都用一些带权重的值连接起来。这个层一般出现在CNN的后面部分,这个层很长,可以作为图像的特征向量来用,也有论文是把全连接层放到SVM,RF,Adaboost,ANN等传统的分类器里头分类,来代替CNN最后的softmax层,那我也做过这个实验,得到的结果并不好,我不知道这些大牛是怎么弄的。这儿打个问号?
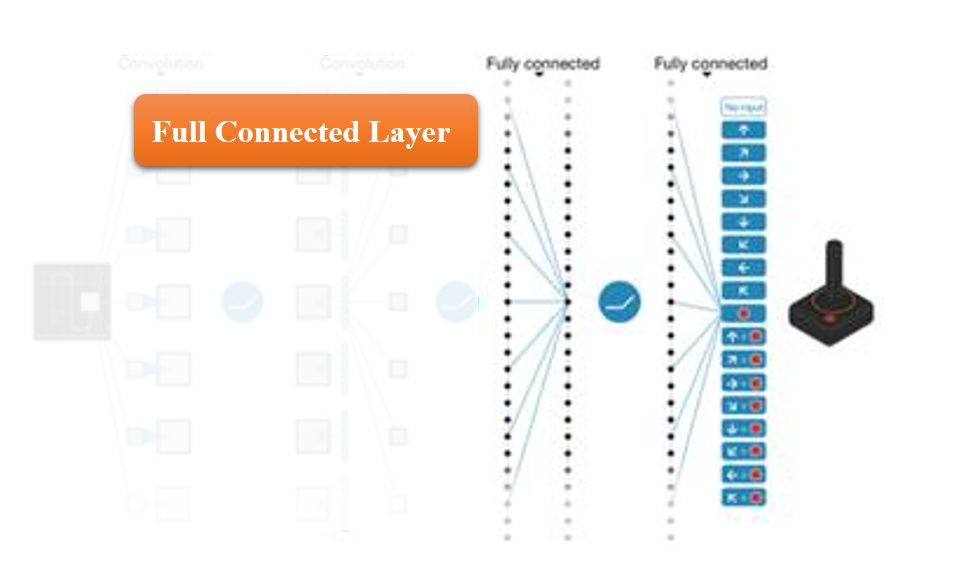
顾名思义,所有的结点都是连接起来的,这儿的权重会特别多,因为全连接了嘛
这个层我不知道怎么翻,反正作用就是把一些没用的结点给扔掉。
这个思路参考了人的大脑的实际运行状态,研究表明大脑在分析图像的过程中真正被激活的神经元并不多,具体哪些被激活靠得就是先前的学习,和留下来的记忆。那如果没有这个dropout层,我们的CNN在判断所有的图像是相当于所有的结点都激活了,这样和现实的情况不符,所以我们要模拟大脑,把一下没什么用的结点给扔掉。
这个层的作用是加快运算速度,防止过拟合,让网络更加的普适,更加有所谓的“鲁棒性”——装个逼,其实就是更好哈哈:)
实现的方法是设置一个阈值,如果这个结点与结点之间的权重高于这个值,那么说明这是强关系,我们保留,如果权重低于这个值,说明关系不大,我们把它扔掉得了。
这个实现方法说错了,特别感谢@hzzzol同学的指正,正确的解释应该是:
Dropout是在训练过程中以一定概率1-p将隐含层节点的输出值清0,而用bp更新权值时,不再更新与该节点相连的权值。什么意思,就是这个就是个概率问题,和权值的大小,激活程度无关哦,被抽中的结点无条件被丢掉。
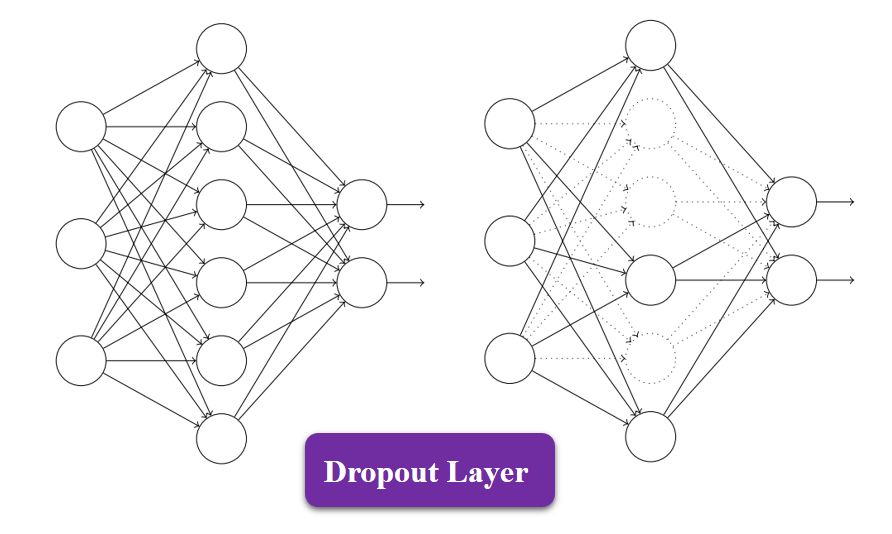
这个层常常出现在全连接层的地方,因为全连接层中的结点与结点连接太多了,消耗了CNN中绝大多数的内存资源,而这中间有一大部分是没有必要的。

你看,最后几层多浪费!
以上是对CNN的一个简单的阐述,当然啰,比较琐碎,一个完整的CNN结构是由多个1)卷积层,2)降采样层,3)激活函数层,4)标准化层,5)全连接层和6)扔掉层 有序地拼接而成的,那么又来了这个问题,LeNet和AlexNet的拼法到底有什么不同呢?
再次祭出这幅经典的LeNet图
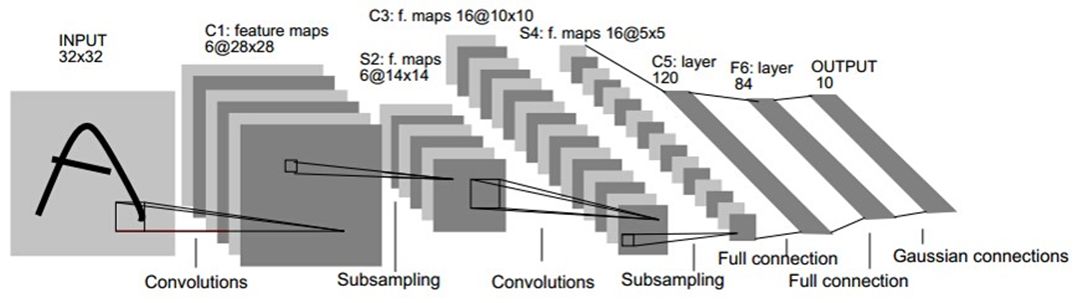
LeNet的成功应用案例是手写字体的识别,就是给一堆手写的阿拉伯数字,用网络来判断这是个什么字。应用的就是当时的邮局等地方,还有门牌号。其实传统的分类器已经可以做到很好的水平了(正确率在96%吧大概),那LeNet作为新起之秀,正确率达到了98%,那在当时就很有名啊,赚了好多好多钱呢,然后卷积神经网络的研究就开始火了呀。到了2012出现AlexNet,以卷积神经网络为核心的深度学习就开始烫了哈哈。
我们可以看到LeNet中有1)卷积层,2)降采样层(就是Subsampling),和3)全连接层,当然喽,应该是由激活函数层的,只是图中没有画,当时用的应该是sigmoid函数吧,反正现在不用了。你可以发现刚刚提到的扔掉层(dropout)和标准化层没有用诶,为什么呢,因为
当时还没有这个啊==b
可以注意到LeNet的:
输入尺寸是32*32像素
卷积层:3个
降采样层:2个
全连接层:1个
输出:10个类别(数字0-9的概率)
然后softmax根据网络输出,也就是这个图像是0-9的概率值大小来判断输入的是多少,比如输出的是个结点,4的值是0.9,其他都是0.001这样的,那么就是说这个输入的图像就是4了,然后根据这个输出的概率,我们可以排列一下输入图像输入某一类的概率值,从大到小,取3个比如,ImageNet竞赛的规则就是这三个里头有一个是对的就当你的网络预测是对的,不然就是预测错误。
我个人的感觉是AlexNet更强调了全连接层的作用,它用了两个全连接层,那么为了减少权重的数目,才引出了dropout这个概念,其他的区别其实不能叫做区别
输入尺寸:227*227像素(因为竞赛的需要)
卷积层:好多(因为输入尺寸的需要)
降采样层:好多(因为输入尺寸的需要)
标准化层:这个反正就是一个公式
输出:1000个类别(因为竞赛的需要)
这儿要说明一下:不要以为卷积层的个数、降采样层的个数、卷积核的尺寸、卷积核的个数这些网络细节会对最后的训练结果产生什么了不得的影响,这些就按照你的输入图像的尺寸来就行了。没有什么说头,你也可以去参考现在已经有的网络结构去设计,都可以的。这些参数大多都是手动调的,依据就是看看学习的结果如何。
放一下AlexNet的结构图
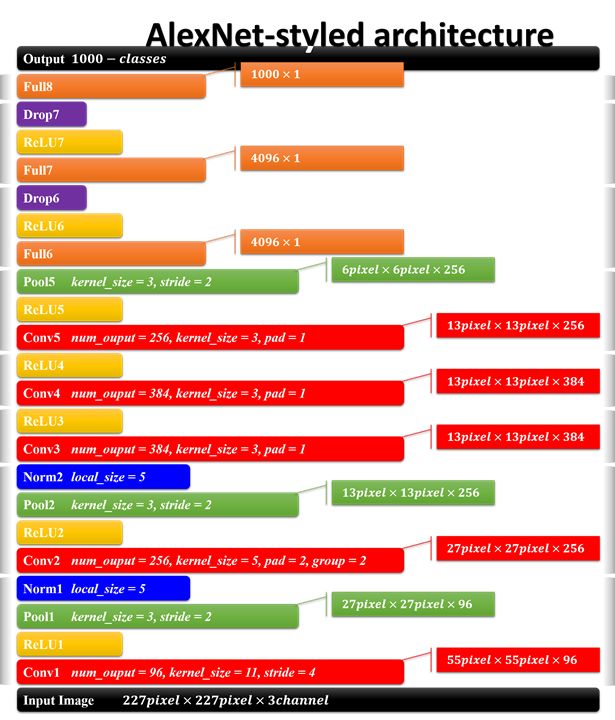
整体AlexNet结构图
卷积神经网络的结构并不是各个层的简单组合,它是由一个个“模块”有机组成的,在模块内部,各个层的排列是有讲究的。比如AlexNet的结构图,它是由八个模块组成的。
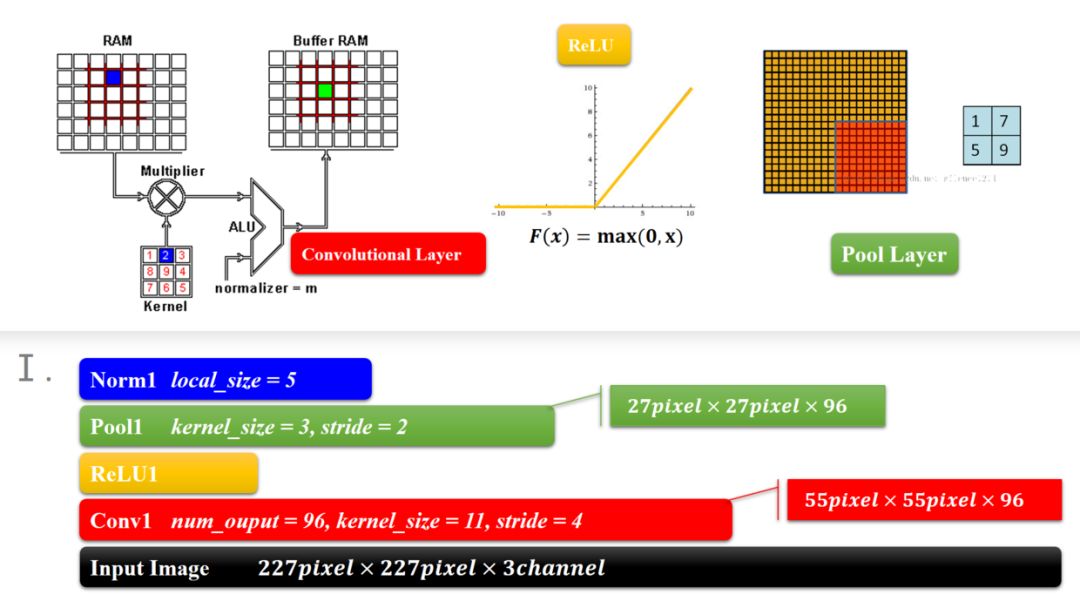
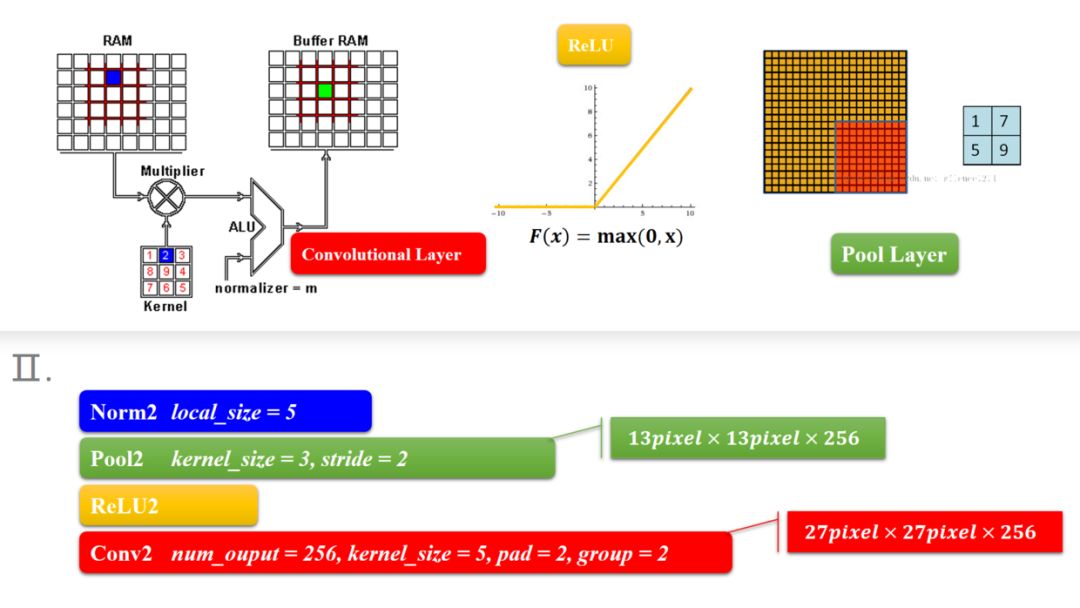
模块一和模块二是CNN的前面部分,
卷积-激活函数-降采样-标准化构成了一个计算模块,这个可以说是一个卷积过程的标配,CNN的结构就是这样,从宏观的角度来看,就是一层卷积,一层降采样这样循环的,中间适当地插入一些函数来控制数值的范围,以便后续的循环计算。
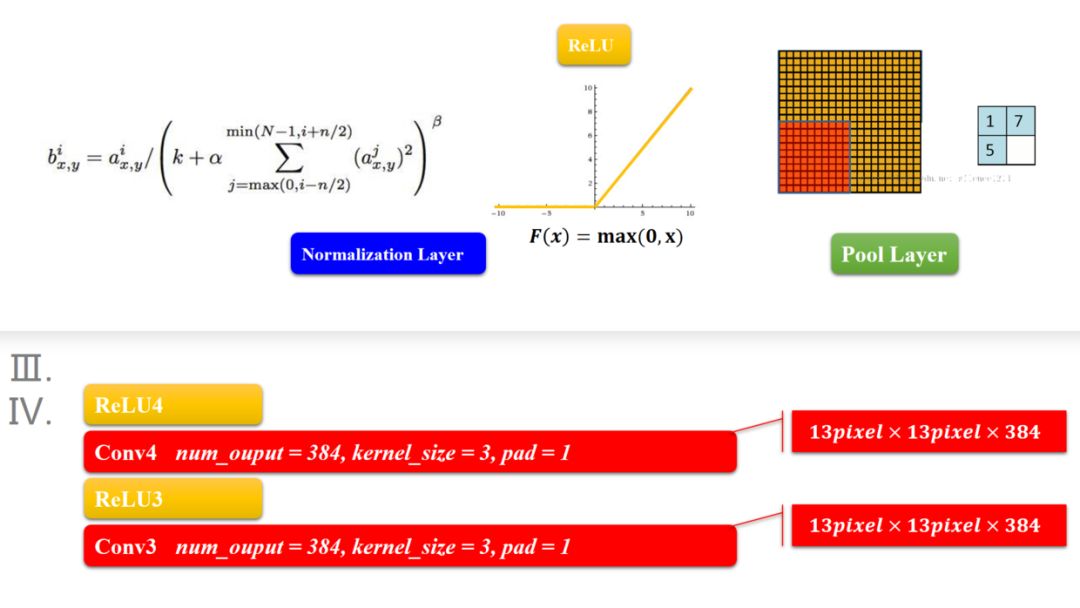
模块三和四也是两个卷积过程,差别是少了降采样,原因就跟输入的尺寸有关,特征的数据量已经比较小了,所以没有降采样,这个都没有关系啦。
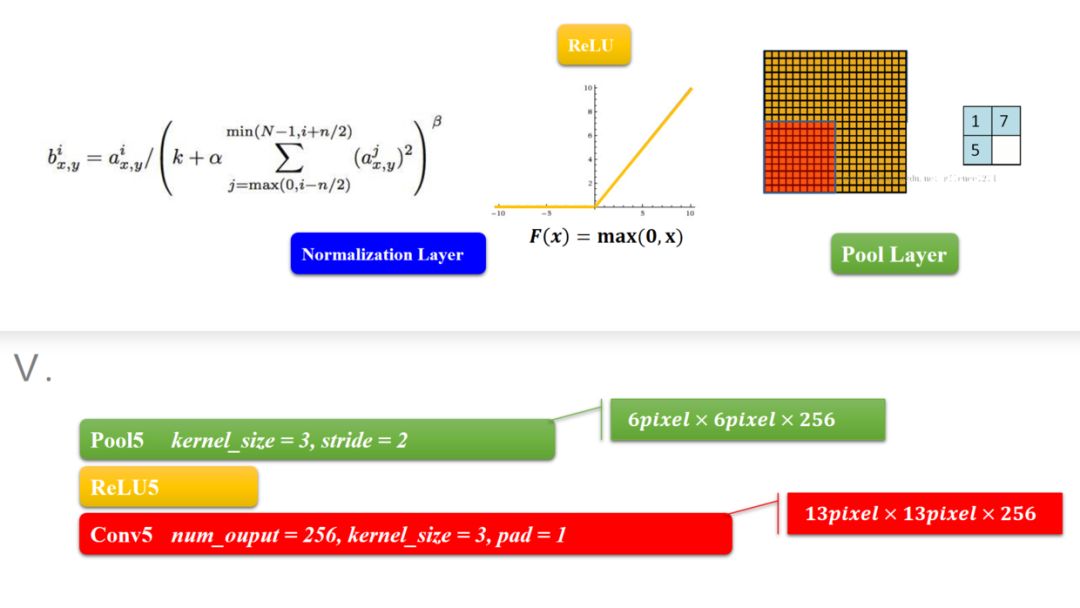
模块五也是一个卷积过程,和模块一、二一样事儿的,就是重复重复。好了,可以总结一下,模块一到五其实都是在做卷积运算,根据输入的图像尺寸在适当决定哪几层要用降采样。然后再加上一些必要的函数来控制数值,就可以了。模块五输出的其实已经是6\6的小块儿了(一般我设计都是到1\1的小块,由于ImageNet的图像大,所以6\6也正常的。)
为什么原来输入的227\227像素的图像会变成6\*6这么小呢,主要原因是归功于降采样,当然啰,卷积层也会让图像变小,如图,一层层的下去,图像越来越小
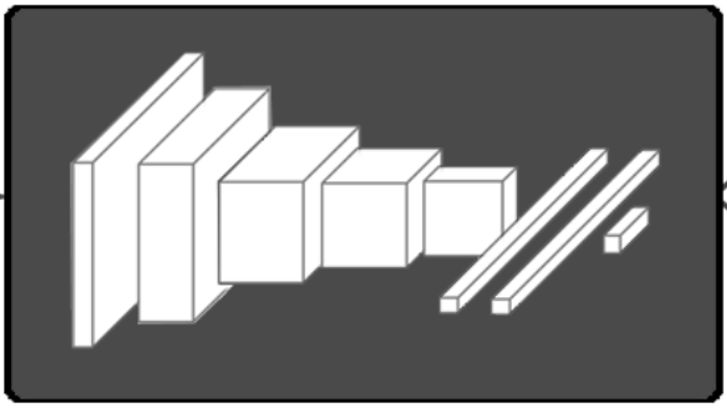
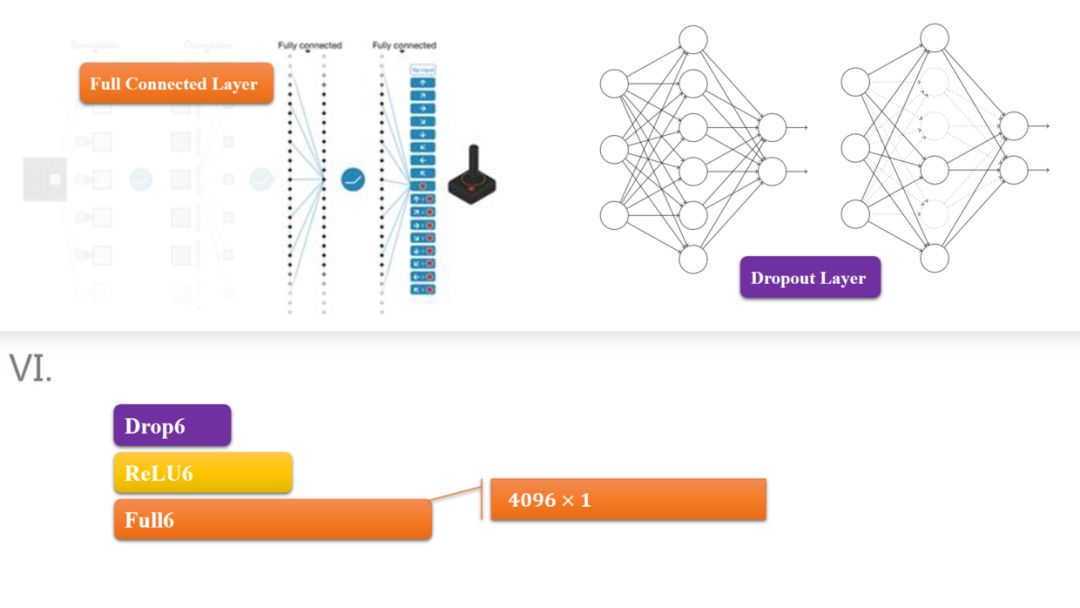
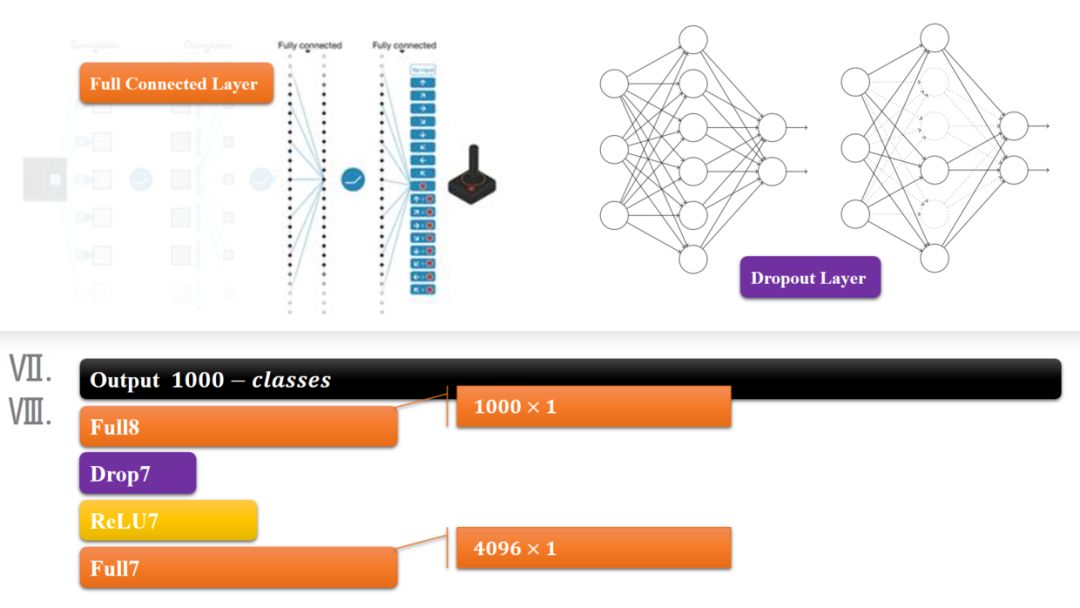
模块六和七就是所谓的全连接层了,全连接层就和人工神经网络的结构一样的,结点数超级多,连接线也超多,所以这儿引出了一个dropout层,来去除一部分没有足够激活的层,其实我记的没错的话这个思想在ANN里头早就有了。
模块八就是一个输出的结果,结合上softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。:)
实战案例
▍Python机器学习实践:随机森林算法训练及调参 (附代码)
▍Python实战 爬取万条票房数据分析2019春节档电影状况
▍教你用Python撩妹:微信推送天气早报/睡前故事/精美图片
▍用Python爬取数据来分析 2019年金三银四 Python就业行情

爱数据,爱技术,爱AI,36大数据社群(大数据交流、AI技术学习群、机器人研究、AI+行业、企业合作群)火热招募中,对大数据和AI感兴趣的小伙伴们。增加AI小秘书微信号:a769996688,说明身份即可加入。



长按识别二维码关注我们
欢迎投稿,投稿/合作:dashuju36@qq.com
如果您觉得文章不错,那就分享到朋友圈~