南开大学提出目标检测新Backbone网络模块:Res2Net | 技术头条


「2019 Python开发者日」,购票请扫码咨询 ↑↑↑
作者 | 高尚华、程明明等(南开大学)
译者 | 刘畅
编辑 | Jane
出品 | AI科技大本营(id:rgznai100)
【导读】去年,AI科技大本营为大家报道过南开大学媒体计算实验室在边缘检测和图像过分割的工作成果,不仅刷新了精度记录,算法也已经开源。今天要为大家再介绍该实验室的最新工作——Res2Net,一种在目标检测任务中新的 Backbone 网络模块。
ResNet 大家都很熟悉了,由何恺明等人于 2015 年提出,其强大的表征能力,让很多计算机视觉任务的性能得到了极大的提升。而南开大学的这项工作提出的新卷积网络构造方式,在多个视觉任务的基准数据集上(CIFAR10,ImageNet),与 baseline 模型进行了对比,优于现有的 SOTA 方法,更多的消融实验结果中也证明了作者方法的优势之处。此外,鉴于 Res2Net 已经在几个具有代表性的计算机视觉任务体现出了优越性,作者认为网络的多尺度表征能力是非常重要的。
下面,AI科技大本营就为大家介绍一下这项工作,大家可以深入研读后进行尝试~

摘要
在许多视觉任务中,多尺度的表示特征是非常重要的。最新的研究在不断的提升着 backbone 网络的多尺度表达能力,在多个任务上提高了算法性能。然而,大多数现有的深度学习方法是通过不同层的方式来表达多尺度特征。作者提出了一种新的卷积网络构造方式 Res2Net,通过在单个残差块里面构建层次化的连接实现。Res2Net 是在粒度级别上来表示多尺度特征并且增加了每层网络的感受野范围。它可以无缝插入现有的ResNet,ResNeXt等网络结构。并且在多个视觉任务的基准数据集上,与 baseline 模型进行了对比,发现它优于现有的 SOTA 方法。更多的消融实验结果证明了作者方法的优势之处。
引言
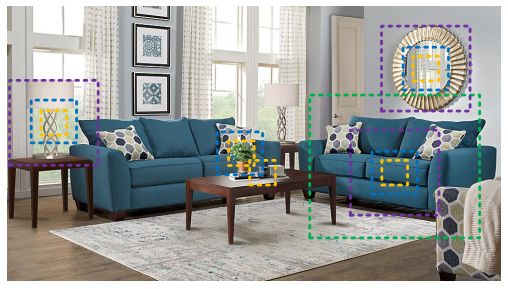
在多个视觉任务中,如图像分类,目标检测,动作识别,语义分割等,设计一个好的多尺度特征是非常重要的。有以下三点原因,第一,如上图所示,在一张图片里面,同一目标可能有不同的大小,比如图上的沙发。第二,待检测目标的上下文信息可能比它本身占的区域更多,例如,我们需要使用大桌子作为上下文信息来判断放在上面的是杯子还是笔筒。第三,从不同尺度的感知信息来理解如细粒度分类和语义分割的任务是非常重要的。
因此,多尺度的特征在传统方法和深度学习里面都得到了广泛应用。通常我们需要采用一个大感受野的特征提取器来获得不同尺度的特征描述,而卷积神经网络通过一堆卷积层可以很自然的由粗到细多尺度的提取特征。如何设计更高效的网络结构是提升卷积神经网络性能的关键。
作者提出了一种简单有效的多尺度提取方法。与现有的增强单层网络多尺度表达能力的 CNNs 方法不同,它是在更细的粒度上提升了多尺度表征能力。
接下来我们再来看看 Res2Net 的架构与体系结构等内容:
Res2Net
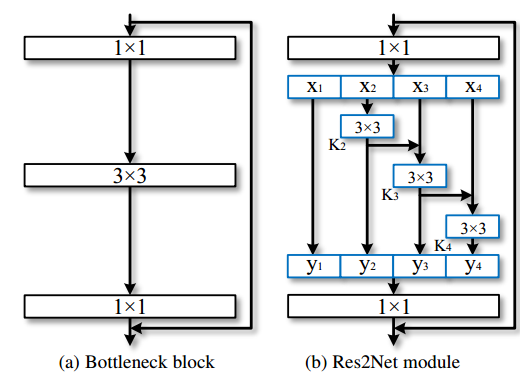
已有的许多工作都是采用的上图(a)作为其 basic block,因此作者希望找到一种能保持计算量不增加,却有更强多尺度特征提取能力的结构来替代它。如上图(b)所示,作者采用了更小的卷积组来替代 bottleneck block 里面的 3x3 卷积。具体操作如下,首先将 1x1 卷积后的特征图均分为 s 个特征图子集。每个特征图子集的大小相同,但是通道数是输入特征图的 1/s。对每一个特征图子集 X_i,有一个对应的 3x3 卷积K_i(), 假设 K_i() 的输出是 y_i。接下来每个特征图子集 X_i 会加上 K_i-1() 的输出,然后一起输入进 K_i()。为了在增大 s 的值时减少参数量,作者省去了 X_1 的 3x3 网络。因此,输出 y_i 可以用如下公式表示:
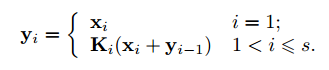
根据图(b),可以发现每一个 X_j(j<=i) 下的 3x3 卷积可以利用之前所有的特性信息,它的输出会有比 X_j 更大的感受野。因此这样的组合可以使 Res2Net 的输出有更多样的感受野信息。为了更好的融合不同尺度的信息,作者将它们的输出拼接起来,然后再送入 1x1 卷积,如上图(b)所示。
实验
作者提出的这个模块可以融合到现有的 CNNs 方法里面,如 ResNet, ResNeXt和DLA,为了公平的实验,作者仅仅将里面的模块替换为 Res2Net,并在基准数据集(CIFAR10,ImageNet)上对 Res2Net 进行了评估。
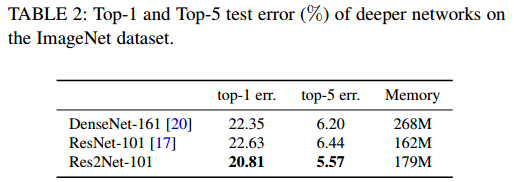
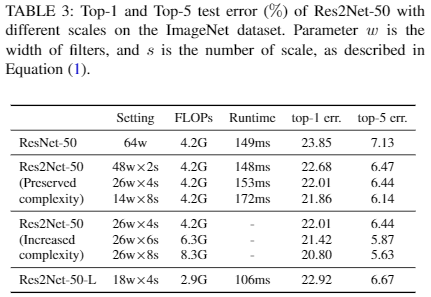
以ImageNet 为例,作者进行了多个对比实验,包括浅层和深层网络的对比,实验结果都显示基于 Res2Net 模块的网络性能更好。作者还探索了尺度大小对性能的影响,如表格 3 所示,其中 w 代表滤波器的宽度,s 代表尺度。
在 ImageNet 数据集上,浅层和深层网络的实验结果:
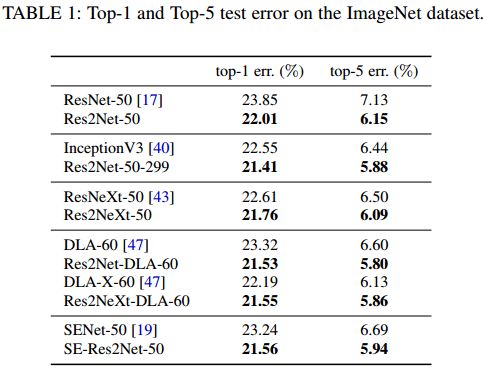
尺度大小对性能的影响:
在更多视觉任务上的实验结果均显示 Res2Net 模块可以显著的提升现有算法的指标。
下图是ResNet-50 和 Res2Net-50 在类激活映射的结果对比:

下图是 ResNet-101 和 Res2Net-101 在语义分割任务上的(可视化的)结果对比:

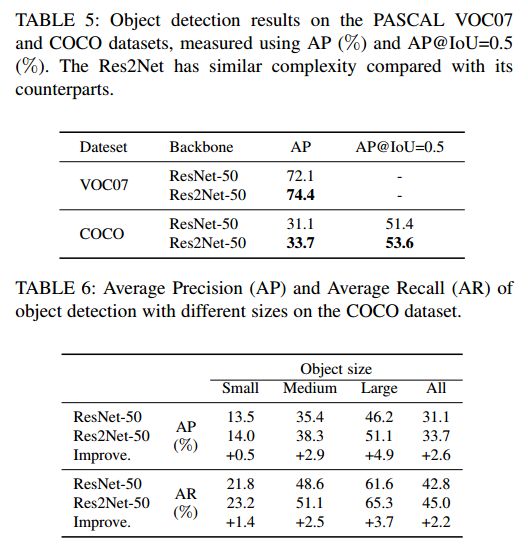
下图是 ResNet-50 和 Res2Net-50 在目标检测任务上的结果对比:
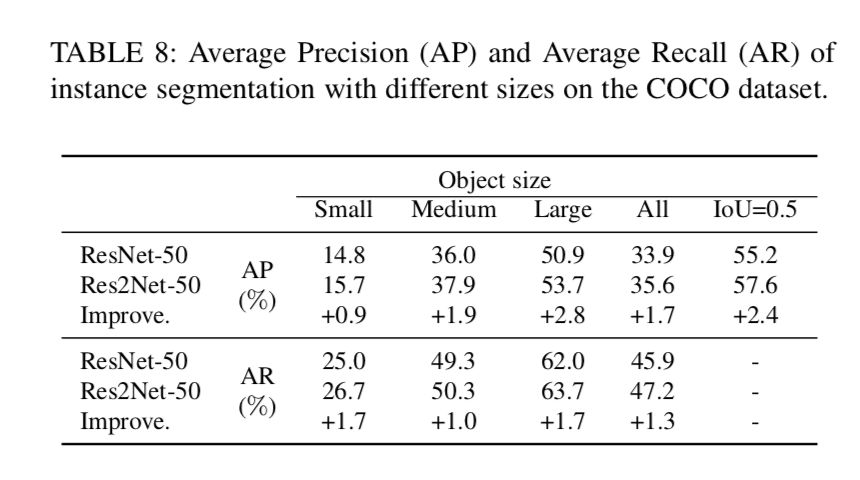
下图是 ResNet-50 和 Res2Net-50 在实例分割任务,COCO 数据集上的 AP 和 AR 两结果的对比:
结论
Res2Net 是一种简洁有效的模块,探索了 CNN 在更细粒度级别的多尺度表达能力。它揭示了 CNN 网络里面除了深度,宽度等现有维度之外,还可以有新的维度“尺度”。Res2Net 模块可以很容易地融合进 SOTA 的方法。在 CIFAR10 和 ImageNet 上图像分类的结果表明,使用 Res2Net 模块的网络比 ResNet,ResNeXt,DLA 等网络效果更好。鉴于Res2Net已经在几个具有代表性的计算机视觉任务体现出了优越性,作者认为网络的多尺度表征能力是非常重要的。
最后,放送一下论文地址:
https://arxiv.org/pdf/1904.01169.pdf
(本文为 AI大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
定了!人社部等发布13项新职业,AI、无人驾驶、电竞上榜
首发 | 13篇京东CVPR 2019论文!你值得一读~ 技术头条
争论不休的TF 2.0与PyTorch,到底现在战局如何了? | 技术头条

❤点击“阅读原文”,查看历史精彩文章。
