专访 | 先声教育CTO秦龙:有限的算法与无限的新意
机器之心原创
作者:邱陆陆
「在教育领域做好,不是说要把某一个特定算法做到极致,而是如何把相对成熟的技术与教育的结合做好。」
《连线》杂志在总结 2017 年人工智能领域学术研究现状时,提到了一个担忧,即当前大多数人工智能技术的发展都极度依赖极少数核心创新算法的支持,换句话说,算法这事,也会有「僧多粥少」的问题。的确,神经网络不是卷积神经网络就是循环神经网络,处理的对象总逃不过语音、图像、文本,而顺理成章的应用思路也就智能音箱、人脸识别这么几个。因此尚未完全成规模的浅滩市场里已经挤进了太多的重磅鲨鱼型选手,蓝海好像只是一个幻觉,海水一直是深红色。
我带着对这一观点的认同接触到了秦龙,先声教育 CTO,然后感受到了这家名字里面甚至没出现「智能」或者「科技」字样的公司带来的惊喜:工程师们堪称「鬼斧神工」地把我们如数家珍的算法变出了花样,然后给出了一个既充分利用了现阶段的技术发展水平,同时具有不错的可扩展性的发展路径。
换句话说,他们的算法既能够顺利落地,在当下解决实打实的需求,手握日均千万次的服务请求,同时一旦那些个 AI 算法今天画过的饼明天真的能充饥了,也能用同样的思路再提高一个台阶挑战更复杂的问题。
这就是「算法的新意」的重要性。
第一个新意来自对语音识别的逆向思维。
我们印象里的语音识别任务,是存在「用户就是上帝」的准则的:用户说话会带着天南地北的口音,所以开发语音输入法的团队要收集大量方言数据让模型「见多识广」;用户总是离着麦克风很远就开始发号施令,所以开发智能音箱的团队要布置麦克风阵列来解决「鸡尾酒会问题」。就算在标准数据集上,算法早就追上然后碾压了人类,我们一样会以「不会变通」,「不解决实际问题」为理由淡化它们的成就。
那么,有没有可能换一种思路,找一个不是「算法迁就善变的人类」,而是「人类模仿标准的算法」的情景,把不会出错、不搞特殊化的算法放在正确答案的位置,不知疲倦地给人类「找茬」?
先声告诉我们:有,这个答案叫做口语测评。
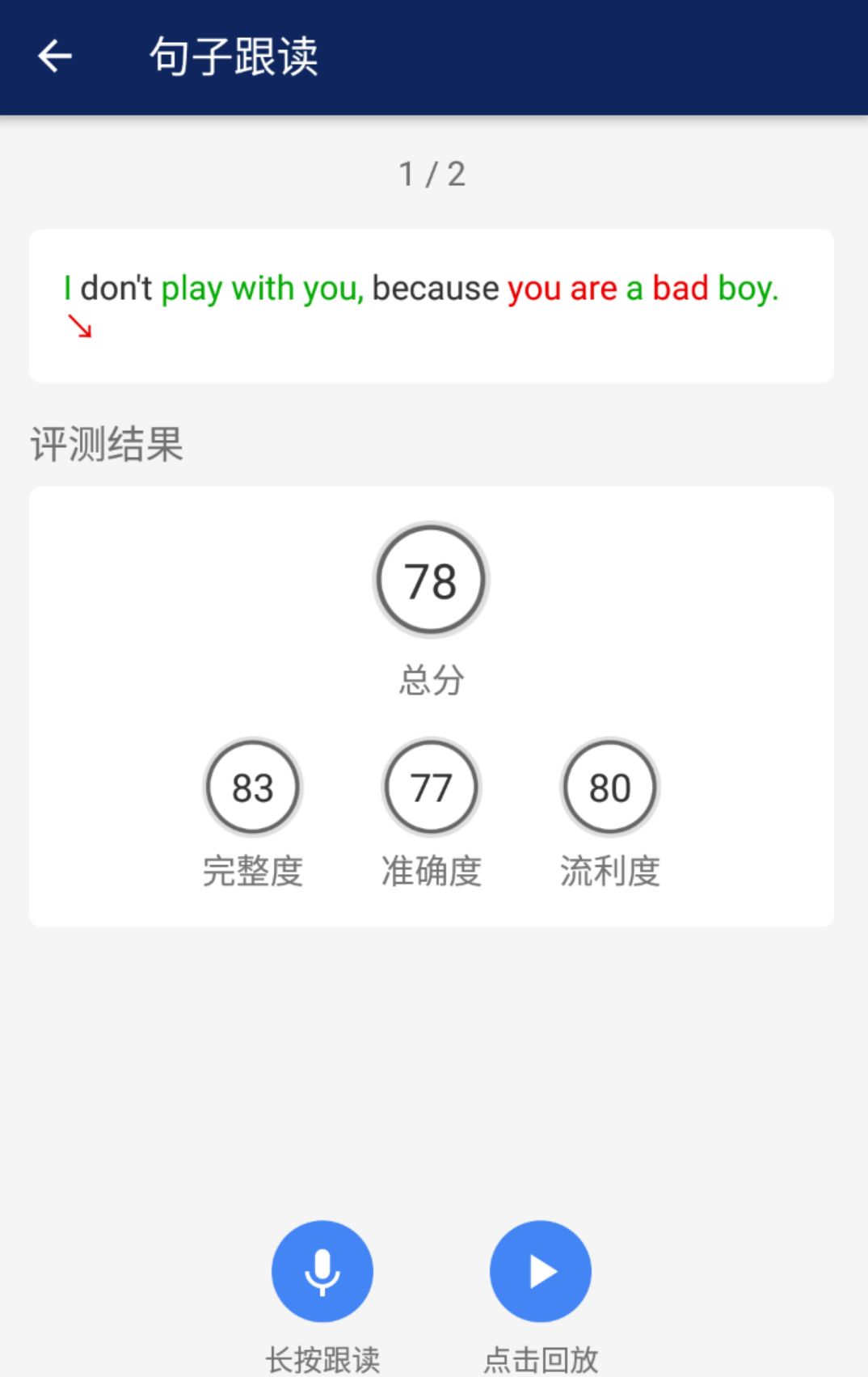
我带着雅思口语 8 分的自信试用了「句子跟读」功能,被算法轻松抓出了三处心服口服的错误:
开头的升降调错误,来自我「词汇量不足情绪来凑」的习惯性夸张语调。
中间的标红来自吞音连读,就像写惯了行书的人被强迫写正楷总是偷漏笔划。
特别扎心的是结尾那个「bad」:原来我发开元音不张嘴这个当年雅思主考官指出过的坏习惯,至今也没改掉!
是的,你可以批评 AI 不能「灵活应变」,却需要承认它永远「尽职尽责」,它或许做起小工「宛如智障」,但变身为老师却「有模有样」。
口语测评背后的神经网络和机器听写、智能音箱无异,都是基于 lstm RNN 的语音识别模型。评测过程里,系统会把声音切割到音素(phoneme)级别,首先判断「有没有」,即语音片段中是否含有所有音素,给出完整度得分;然后判断「对不对」,逐个对发音、重音(stress)位置以及语音语调的正确性进行软分类,给出准确度打分;最后在句子层面,对照单词时长的分布信息、词之间的停顿、总体的语速,给出流利度得分。经过这一整个流程,因此,这个音素级别的模型能够给你详细到音素水平的修改意见,字斟句酌地和你推敲发音。
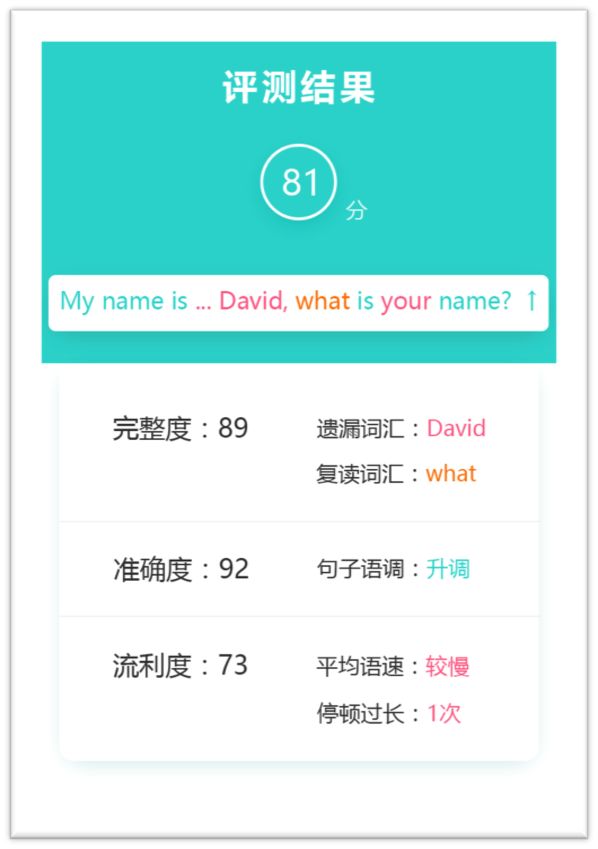
这里展示的仅仅是一个有确定性答案的客观题,再难一些的非确定性答案半开放性题目也可以类似处理。先声的业务针对 K12(Kindergarten to Grade 12,学龄前到高中)展开,其中非常典型的问题是中考的口头作文:
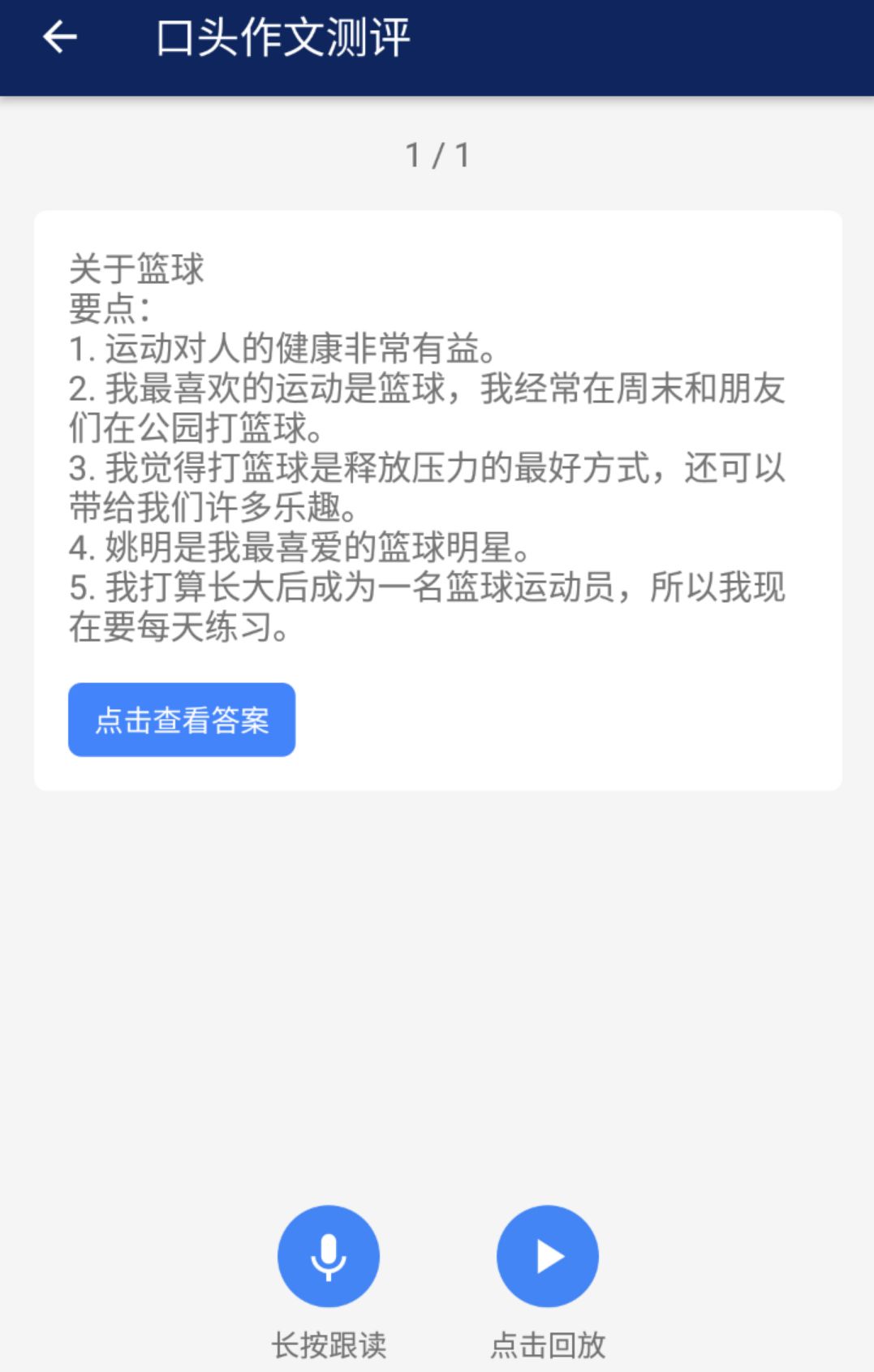
相比于跟读,口头作文还要在语音识别后加上自然语言处理程序,判断考生是否覆盖题目所要求的要点:除了在考生的答案里寻找标准答案关键词之外,也要用词嵌入(word embedding)寻找近义词和词组,比如标准答案是「Basketball is good for health.」,考生用了「Playing basketball is a healthy habit.」也一样应该得分。
第二个新意来自对机器翻译的另类利用。
其实「平行语料」并不一定局限于两种语言,只要是有对应关系的语句对,都可以用「编码器-解码器」的机器翻译思路来解。在学界,这个思路被扩展到了问答系统的设计,而先声选择了另一个奇妙的语言对:「有语法错误的句子」和「改掉了语法错误的正确句子」。于是,作文批改就这样变成了一个简化版的机器翻译问题。
之所以说是简化版,是因为作文批改中通常涉及的改动范围都比较小,没有机器翻译中由于不同语言的语法结构差异而产生的长句校准问题。所以,批改不需要注意力机制、甚至不需要非常消耗计算资源的深度神经网络,哪怕是传统的统计机器翻译(SMT),也能取得不错的效果。
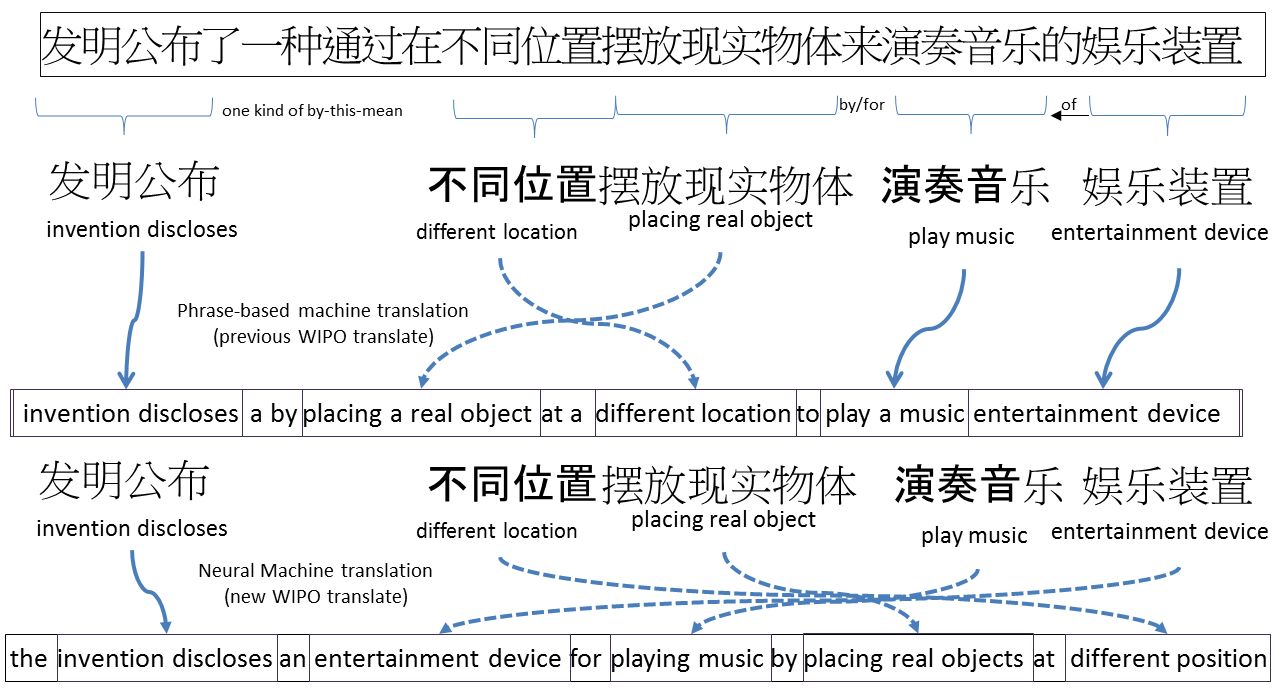
机器翻译中的长句校准问题
类比机器翻译系统的作文批改并不是唯一一种方式,类似自然语言处理,作文批改也有基于规则的做法和基于统计的 n-gram 做法。
基于规则的做法逻辑简单:看到名词就检查冠词情况,看到动词就检查时态情况,但是需要手写定义海量的规则,既不优雅也不高效,已经渐渐被摒弃。而基于统计的 n-gram 方法,是神经网络出现之前自然语言处理领域毋庸置疑的统治者,它的一种基本逻辑和完形填空很相似:挖掉由 n 个单词组成的子句中的一个,给定周围的语境,根据语料库,此处出现概率最高的单词是哪些?在写作批改里,这个逻辑变成了看看每一个词周围的语境,如果一个词出现的概率极低,低过了一定的阈值,那么系统就判定这个词错了,并将可能出现概率较高的词作为修改意见给出。

类比机器翻译的模型在可扩展性上可以碾压基于规则的模型,在可控性上也优于 n-gram 模型:如果发现了一处没有改过来的错误,只需要把它和正确的句子一起做成数据对,在下一次迭代过程里补充进训练集即可,神经网络可解释性的弱点就这样被完美地避开了。
不过,可解释性并不会成为秦龙的困扰,他坦言,做产品就是「简单粗暴」:「只要效果提升了,我不需要解释。无论是线性模型还是 lstm,哪种方法结果漂亮,我就认同哪个结果。我们不会因为 lstm 听起来高大上就要用这个,做产品的团队没有这种考虑。」
当然,基于翻译的模型的优点还有很多,可用数据多、语料库获取难度低,批改范围从语法是否正确扩展到用词是否地道,种种不一而足。
即使汇集如此多优点,在写作批改的路上,工程师们仍然有很长的路要走。语法并不是一篇作文的全部,比语法更重要的是逻辑与表达。考生陈述的观点是否扣题,论点是否得到了充分的论据支持,论据是否有足够清晰明确的表达,都是写作批改系统应该做到,而现有自然语言处理技术尚不能支持的地方。「现在我们还没办法通过一个简单的神经网络判断一个文章是否跑题,更别说分析逻辑性了。」
但是工程师永远不会被「研究尚不支持」这种理由捆住手脚。先声的团队尝试了多种方案之后,最后做了单独的模型类比阅读理解中的「话题模型」给作文的内容性打分,加权平均得到总评分。
除了引入更多的模型,业界的常见做法自然还有引入更多的数据。
「传统机器学习方法,例如线性回归和 SVM,饱受诟病的一点是数据量达到一定程度之后,模型复杂度继续提升已经没有用了。而相比之下,深度学习虽然在短期内需要大量数据,但是最终仍然会走向收敛。」秦龙说。
对于写作批改来说,「大数据」除了「大量文章」之外,还有另一个维度的指标需要满足,就是「大量话题」。每个话题下的大量文章好满足,而大量话题非常难实现。
采访前,秦龙分享给我一篇论文,是用一层卷积层(convolutional layer)、一层 lstm 、一层全连接时序均值(mean over time)的神经网络模型做写作批改。这是当前非常常见的一类论文批改实现方法,然而文中的模型每换一个话题就要重新训练一次、改一组参数。泛化能力之低,甚至无法跨过业界「可用」的门槛。「我们做了一些实验,把卷积层替换成词嵌入(word embedding),然后取多个词而不是一个词的词嵌入,lstm 变成双向等等,效果会好一点。」秦龙如是说,然而「好一点」距离理想中的模型还很遥远。
「假如有足够的数据,我们甚至能做出好的无参数(nonparamatric)算法。可以像 K 临近算法一样,把所有的训练数据归为 1-5 分 5 个类别,每个分数段都有在高维空间里有自己的中心。推理阶段只要计算每篇论文和每个分数段中心之间的距离,加权平均,就能得到很准确的判分。然而真实世界里的作文分数也是呈钟型分布的,5 分和 1 分的样本都很少,收集数据太难了。」
但是再难似乎也没对工程师造成什么消极的影响。他们仍然在有条不紊地迭代着已经成熟的语音测评系统,升级着日渐成熟的写作批改系统,然后计划着更多:
「除了测评类,我们也关注深度知识追踪(deep knowledge tracing)在自适应学习(adaptive learning)方面的应用,以及其他自然语言处理的方法在新题库构建方面的能力。」
最后,秦龙以这样一句话总结了先声的工作,「在教育领域做好,不是说要把某一个特定算法做到极致,而是如何把相对成熟的技术与教育的结合做好。」

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com