机器学习模型中的 bug 太难找?DeepMind 呈上了三种好方法!

对抗测试、鲁棒学习和形式化验证。
AI 科技评论按:计算机编程发展至今,bug 和软件就一直如影随形。多年来,软件开发人员已经创建了一套在部署之前进行测试和调试的最佳方法,但这些方法并不适用于如今的深度学习系统。现在,机器学习的主流方法是基于训练数据集来训练系统,然后在另一组数据集上对其进行测试。虽然这样能够显示模型的平均性能,但即使在最坏的情况下,保证稳健或可被接受的高性能也是至关重要的。对此,DeepMind 发布文章介绍了能够严格识别和消除学习预测模型中的 bug 的三种方法:对抗测试(adversarial testing)、鲁棒学习(robust learning)和形式化验证(formal verification)。AI 科技评论编译如下。
机器学习系统默认设置的鲁棒性较差。一旦引入细微误差,那么即使在特定领域中表现优于人类的系统,可能连简单问题都解决不了。例如,考虑图像扰动的问题:如果在输入图像中加入少量经仔细计算的噪声,那么一个比人类更擅长做图像分类任务的神经网络就很容易将树懒误分类为赛车。

覆盖在典型图像上的对抗输入可能导致分类器将树懒错误地分类为赛车。两个图像在每个像素中最多相差 0.0078。第一张图像被归类为三趾树懒,置信度> 99%。第二张概率>99% 的图像被归类为赛车。
这不是一个全新的问题。计算机程序一直都存在 bug。几十年来,软件工程师从单元测试到形式化验证上装了很多技术工具包。这些方法在传统软件上运行良好,但是由于这些模型的规模问题和结构不完整(可能包含数亿个参数),因此采用这些方法来严格测试神经网络等机器学习模型是非常具有挑战性的。这就需要开发用于确保机器学习系统部署更可靠的新方法。
从程序员的角度来看,bug 就是所有不符合系统规范(即预期功能)的行为。作为「智能化」任务的一部分,我们需要对评估一致性的技术进行研究,即机器学习系统不仅要与训练集和测试集一致,还要与描述系统期望属性的规范列表一致。这些属性可能包括对输入中微小扰动的鲁棒性,避免灾难性故障的安全限制,或产生符合物理定律的预测。
我们共同致力于严格开发和部署与所需规格可靠一致的机器学习系统,在本文中,我们将讨论机器学习领域面临的三个重要技术挑战。
1、有效地测试与规范的一致性。我们探索有效的方法来测试机器学习系统是否与设计者和系统用户所期望的属性(例如不变性或鲁棒性)一致。这是用于显示模型可能与期望行为不一致的情况的一种方法,即在评估期间系统地搜索最坏情况的结果。
2、训练与规范一致的机器学习模型。即使有大量的训练数据,标准的机器学习算法训练出的预测模型也可以得出与具有鲁棒性和公平性的期望规范不一致的预测结果,这就要求我们重新考虑训练算法,要求这些算法不仅能够很好地拟合训练数据,还要能够符合预期规范。
3、形式化验证机器学习模型与规范的一致性。这需要这样一种算法,即对于所有有可能的输入,该算法都能证明模型的预测结果与规范之间是一致且可被证明的。虽然形式化验证领域几十年来一直在研究这种算法,尽管进展不错,但该方法并不能轻易地扩展到当今的深度学习系统。
· 测试与规格的一致性 ·
对抗样本的鲁棒性是深度学习中研究相对较好的一项工作。从这项工作中引申出的一个主要任务是评估强对抗样本的重要性,以及设计可以做有效分析的透明模型。在和业界其他研究者合作时,我们发现许多模型在面对弱对抗样本时看起来很稳健,然而,在面临更强的对抗因子时,模型显示出的对抗精确度基本为 0%(Athalye et al,2018,Uesato et al,2018,Carlini and Wagner,2017)。
虽然在监督学习下,大多数工作都关注一些罕见错误(其中以图片分类任务居多),但是将这些方法扩展到其他场景中也是一件需要关注的事情。在最近关于发现重大错误的对抗方法的研究中,我们将这些方法应用于测试强化学习的智能体,这些智能体主要被应用在对安全性要求很高的场景中。开发自主系统的一个挑战是,由于小错误可能会导致很严重的后果,因此我们容不得出现一点失误。
我们的目标是设计一个「攻击者」,以便我们提前检测到一些错误(例如,在受控环境中)。如果「攻击者」可以有效地识别给定模型的最坏情况输入,则能够让我们在部署模型之前捕捉到一些罕见失误。与图像分类器一样,面对一个弱的「攻击者」进行评估会在部署期间造成一种错觉,即这是安全的。这类似于「红队研判法(red teaming)的软件实践」,不过对恶意攻击者造成的失误进行了延展,同时还包括了自然出现的失误,例如泛化不足造成的失误。
针对于强化学习智能体的对抗测试,我们开发了两种互补的方法。首先,我们使用无导数优化来直接最小化智能体的预期回报。在第二部分中,我们学习了一种对抗价值函数,该函数根据经验预测哪些情况最有可能导致智能体失误。然后,我们使用学习好的函数进行优化,将评估重点放在最有问题的输入上。这些方法只构成了某个丰富且正在增长的潜在算法空间的一小部分,同时,对于严格评估智能体方面未来的发展,我们也感到非常激动。
相比于随机测试,这两种方法已经实现了很大的改善。使用我们的方法,可以在几分钟内检测到原需要花费数天才能发现甚至根本无法发现的失误(Uesato et al,2018b)。我们还发现,对抗测试会定性地发现我们智能体的行为和在随机测试集评估的预测结果之间存在的差异。特别是,使用对抗性环境构造,我们发现智能体在执行 3D 导航任务上的平均水平可与人类在同一任务上的表现相媲美,不过,它在十分简单的迷宫上却任务上,还不能够完整地找到目标(Ruderman et al,2018)。此外,这项工作还强调,我们需要设计的系统除了要能对抗「攻击者」,还要能够抵御自然失误。
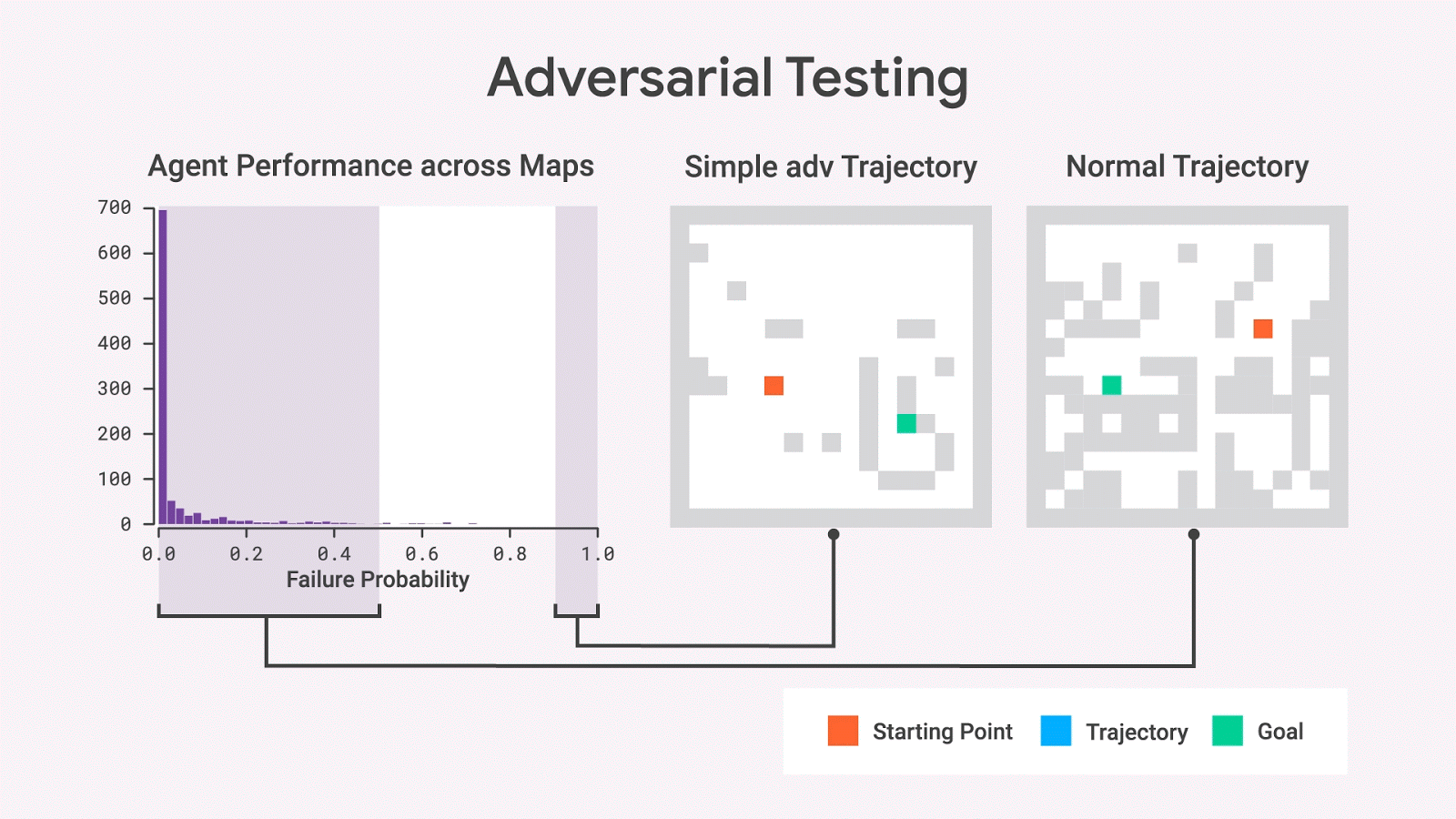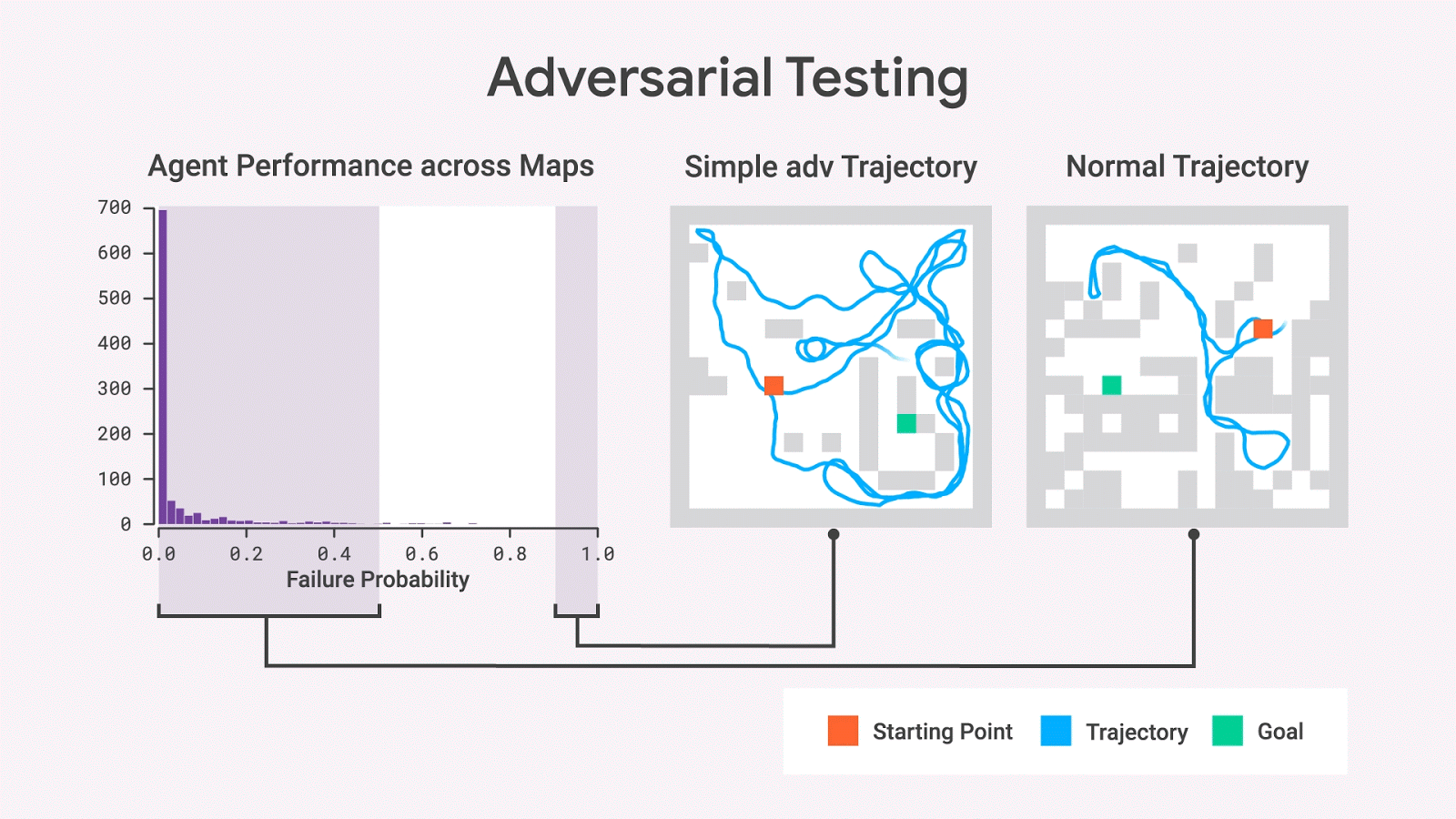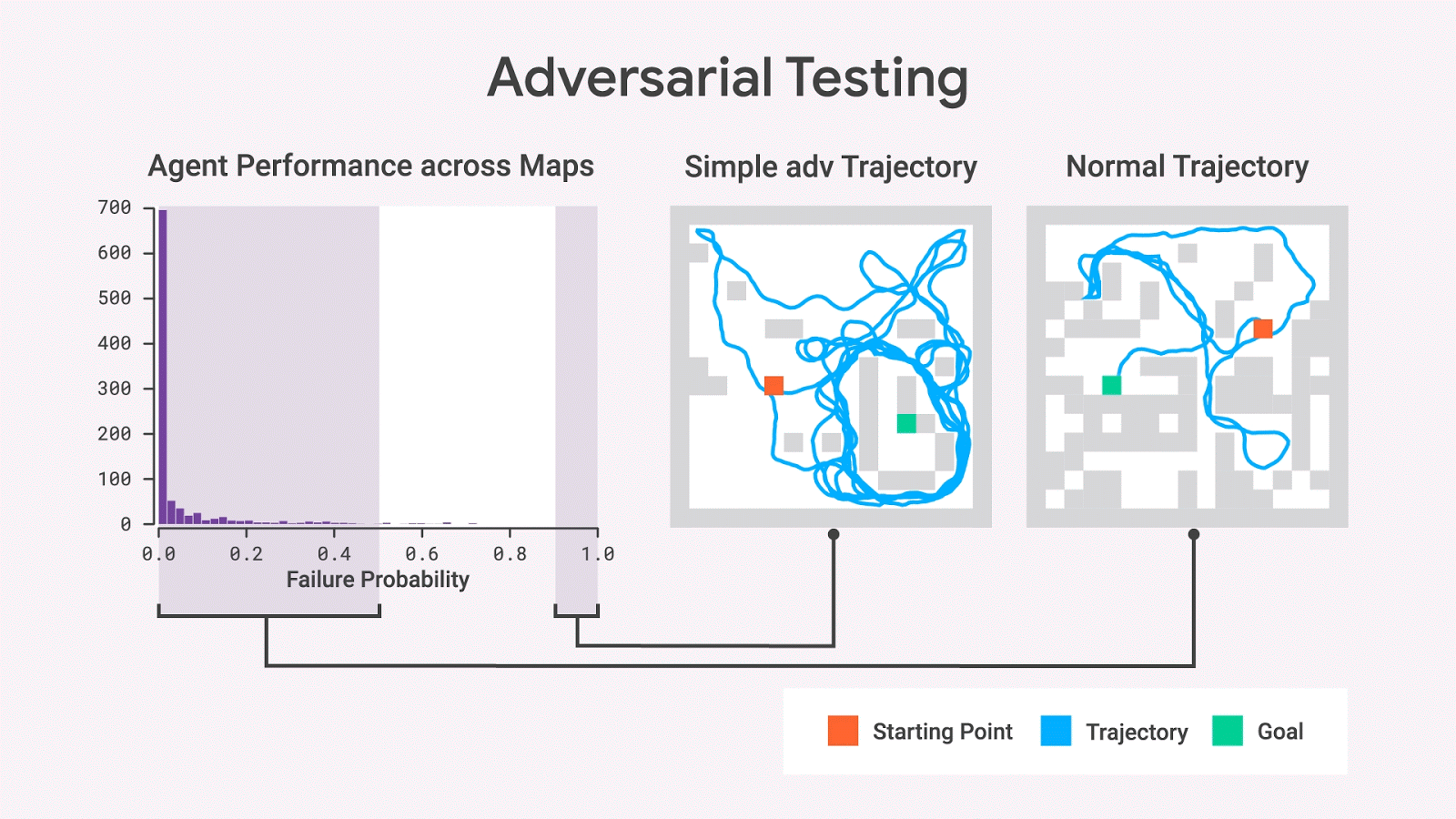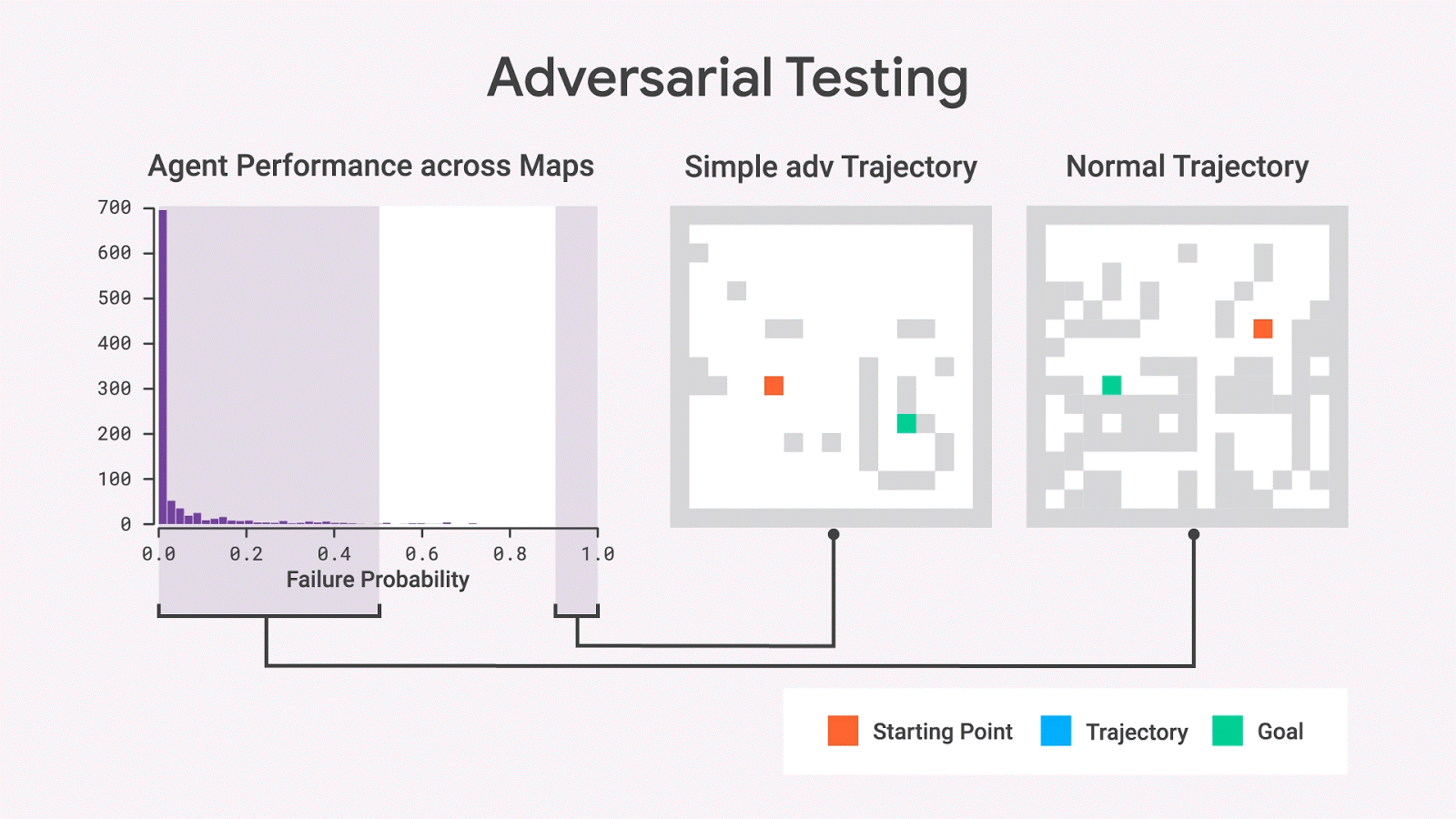
使用随机抽样,我们几乎从不观察具有高失败概率的地图,但是对抗测试表明这样的地图确实存在。即使在移除了许多墙壁,变成比原始地图更简单的地图后,这些地图上的失败概率依然很高。
· 训练与规范一致的模型 ·
对抗测试旨在找到违反规范的反例。因此,它往往会高估模型与这些规范的一致性。在数学上,规范是必须在神经网络的输入和输出之间保持的某种关系。这可以采用某些键输入和输出参数的上限和下限的形式。
受此观察的启发,一些研究人员(Raghunathan et al,2018; Wong et al,2018; Mirman et al,2018; Wang et al,2018),包括我们在 DeepMind 的团队(Dvijotham et al,2018; Gowal et al.,2018),研究了与对抗测试程序无关的算法(用于评估与规范的一致性)。这可以从几何学上理解,我们可以通过约束一组给定输入情况下的输出空间来约束与规范相差最大的情况(例如,使用间隔边界传播; Ehlers 2017,Katz et al,2017,Mirman et al,2018)。如果此区间相对于网络参数是可微分的并且可以快速计算,则可以在训练期间使用它。然后可以通过网络的每个层传播原始边界框。
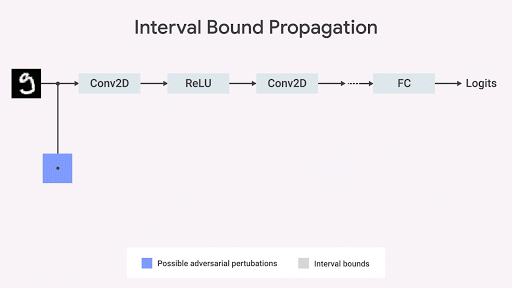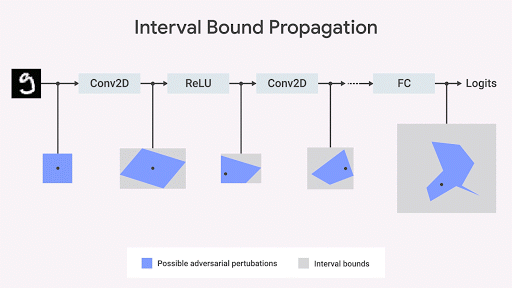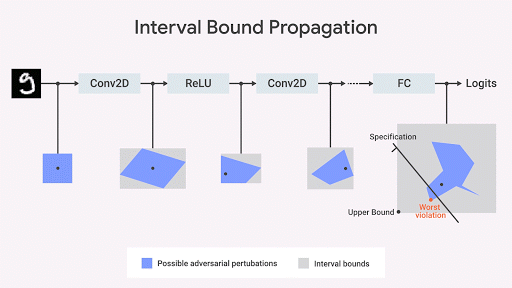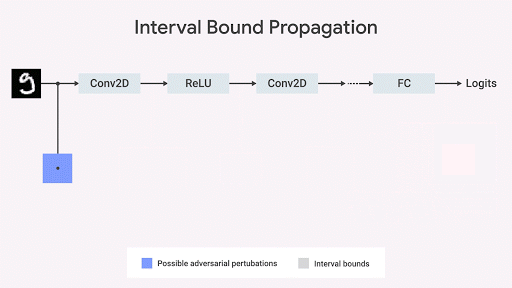
我们证明了「间隔边界传播」(interval bound propagation )是快速且有效的方法,并且与先前的信念相反,这种方法可以获得更加强大的结果(Gowal et al,2018)。特别地,我们证明它可以降低在 MNIST 和 CIFAR-10 数据集上的用于图像分类的现有技术的可证明的错误率(即,任何「攻击者」可实现的最大错误率)。
该领域未来的下一步,将会是学习正确的几何抽象以计算更严格的输出空间过度概率。我们还希望训练出能够与更复杂的规范一致的网络,从而捕捉到理想的行为,例如上面提到的不变性和与物理定律的一致性。
· 形式化验证 ·
严格的测试和训练非常有助于构建强大的机器学习系统。但是,没有多少测试可以形式化地确保系统的行为符合我们的要求。在大规模的模型中,由于输入扰动有无穷多种,因此我们很难列举出给定输入集(例如,对图像的无穷小扰动)所有可能的输出。但是,与在训练中的情况一样,我们可以通过在输出集上设置几何区域来找到更有效的方法。形式化验证是 DeepMind 正在进行的研究主题。
关于如何计算网络输出空间上的精确几何区域,机器学习研究界已经提出了几个的有趣的 idea(Katz et al,2017,Weng et al,2018; Singh et al,2018)。我们的方法(Dvijotham et al,2018),则基于优化和二元性,包括将验证问题表述为一个试图找到被验证的属性中最大的违规行为的优化问题。同时,该问题通过在优化中使用二元性的思想而变得更易于计算。这就会带来了额外的约束,其使用所谓的「切割平面」来细化经「间隔边界传播」计算得来的边界框。这种方法虽然合理但不完整:可能存在兴趣属性为真,但此算法计算的区域范围不足以证明该属性的情况。但是,一旦我们得到了区域范围,这就形式化的保证了不会有违反属性的行为。下图以图形方式说明了该方法。
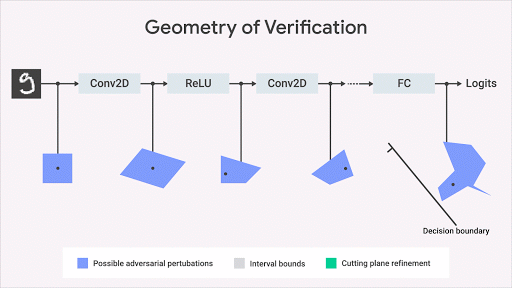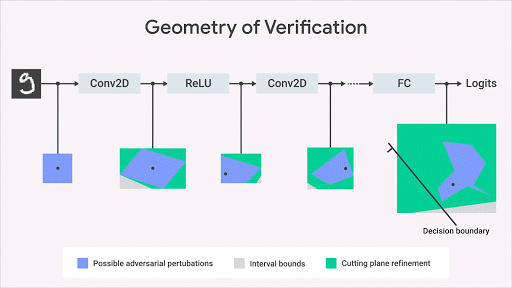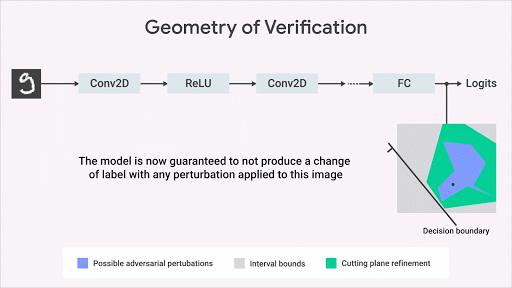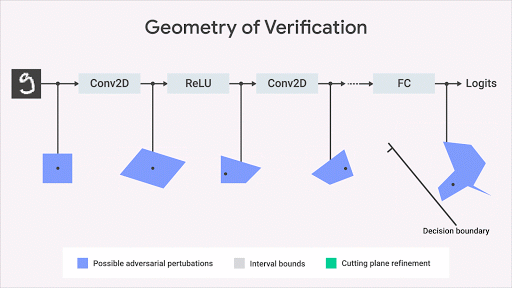
这种方法使我们能够将验证算法的适用性扩展到更广泛的网络(激活函数,体系结构)、一般规范和更复杂的深度学习模型(例如生成模型、神经过程等)以及对抗鲁棒性以外的规范(Qin,2018)。
· 总结 ·
在高风险情况下部署机器学习带来了独特的挑战,并且需要开发相应的能够可靠地检测故障模式的评估手技术。更具体而言就是,我们认为,相比于仅仅从训练数据中隐含地生成规范的方法而言,学习与规范的一致性的方法能够带来更有效的改进。我们对于正在进行的对抗评估、鲁棒性模型学习和形式化规范验证的研究,都感到非常兴奋。
为了确保现实世界中的 AI 系统能够做出「正确的事情」,我们还需要做更多的工作来创建自动化工具。我们对以下方向的进展特别感兴趣:
1、学习对抗性评估和验证:随着 AI 系统的扩展和复杂程度不断增加,设计能很好拟合 AI 模型的对抗性评估和验证算法将变得越来越困难。如果我们可以利用 AI 的强大功能来促进评估和验证,那么将大大加速这项研究的进展。
2、开发用于对抗性评估和验证的工具并对外开放:为 AI 工程师和从业者提供易于使用的工具非常重要,这些工具可以在 AI 系统导致广泛的负面影响之前,就让研究者知道其可能的故障模式。这需要对对抗性评估和验证算法实现某种程度上的标准化。
3、扩大对抗样本的范围:到目前为止,大多数关于对抗样本的工作都集中在对小扰动(通常是图像)的模型不变性上。这为开发对抗性评估、鲁棒学习和验证方法提供了极好的测试平台。我们已经开始探索与现实世界直接相关属性的替代规范,并对未来在这方面的研究感到兴奋。
4、学习规范:在 AI 系统中捕获「正确」行为的规范通常难以进行精准陈述。当我们可以构建能够展示复杂行为并在非结构化环境中行动的更加智能的智能体时,我们将能够创建能够使用部分人类规划的系统,但这些系统还需要从可评估的反馈中更加深入地学习规范。
DeepMind 通过负责任地进行机器学习系统开发和部署,致力于对社会产生积极的影响。为了确保开发人员的贡献是有积极意义的,我们还需要应对许多技术挑战。我们致力于参与这项工作,并很高兴能够与更多人合作解决这些挑战。
via:https://deepmind.com/blog/robust-and-verified-ai/
AI 科技评论报道
滑动查看更多内容



<< 滑动查看更多栏目 >>



